
ACID vs BASE
(5 Minutes) | How Each Works, The Core Trade-Off, When to Use Each (and When Not to)


A Model-Driven Approach to Building and Deploying Agents
Presented by Amazon
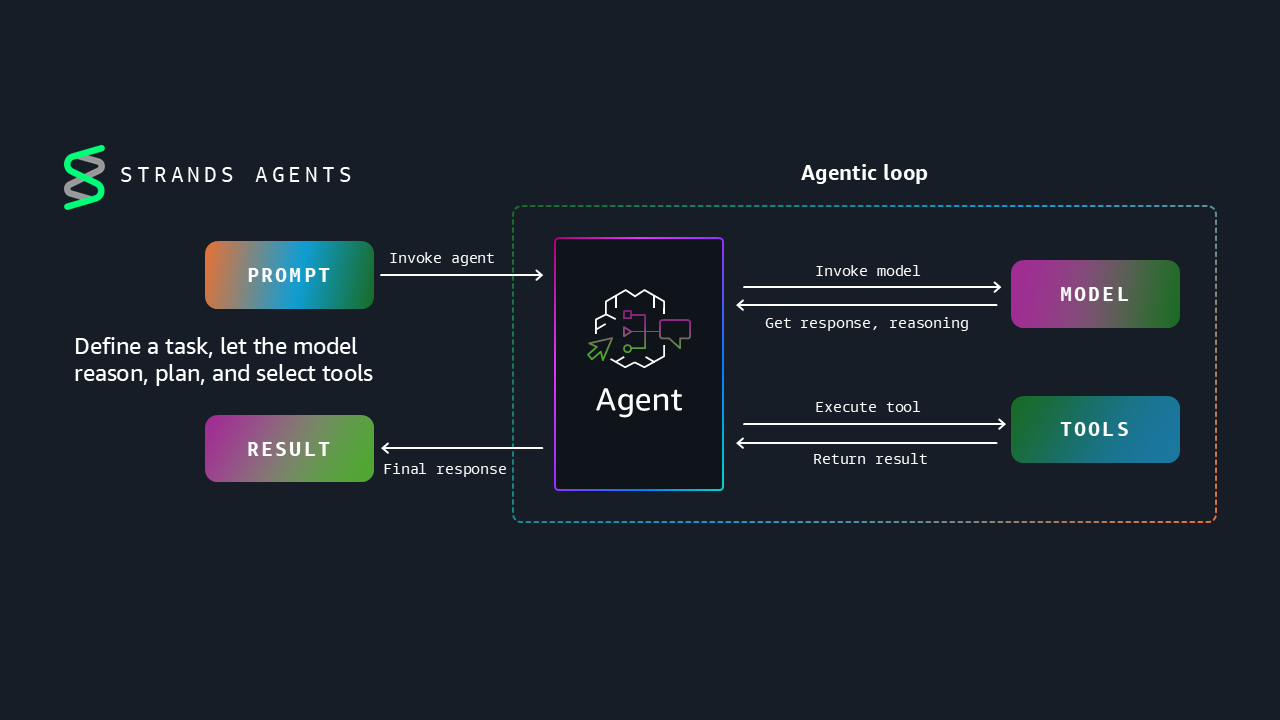
Strands Agents empowers you to create intelligent agentic systems that leverage reasoning models to make dynamic decisions and adapt to unexpected situations. You can now build agents in TypeScript, run agents on edge devices, steer agents through modular prompting, and verify agent performance with evaluations.
ACID vs BASE: How to Choose Your Consistency Model
What’s worse for your product: showing stale data or showing an error? Your system can be fast, or it can be consistent, and the surprise is that you often can’t have both at the same time.
ACID and BASE sit at the center of this tension, yet many engineers treat them like mutually exclusive camps. Understanding their real trade-offs helps you decide when correctness matters more than uptime; and when the opposite is true.
The Core Trade-Off: Safety vs Availability
ACID and BASE sit on opposite ends of a spectrum shaped by the CAP theorem: you cannot have perfect Consistency, Availability, and Partition tolerance at the same time.
ACID → Favors consistency and correctness, even if it means refusing or delaying requests during failures.
BASE → Favors availability and scale, even if it means serving temporarily inconsistent data.
When you stop viewing them as opposing camps and start viewing them as options to tune, the path forward gets simpler.
ACID: Safe, Strict, and Familiar
ACID stands for Atomicity, Consistency, Isolation, Durability.
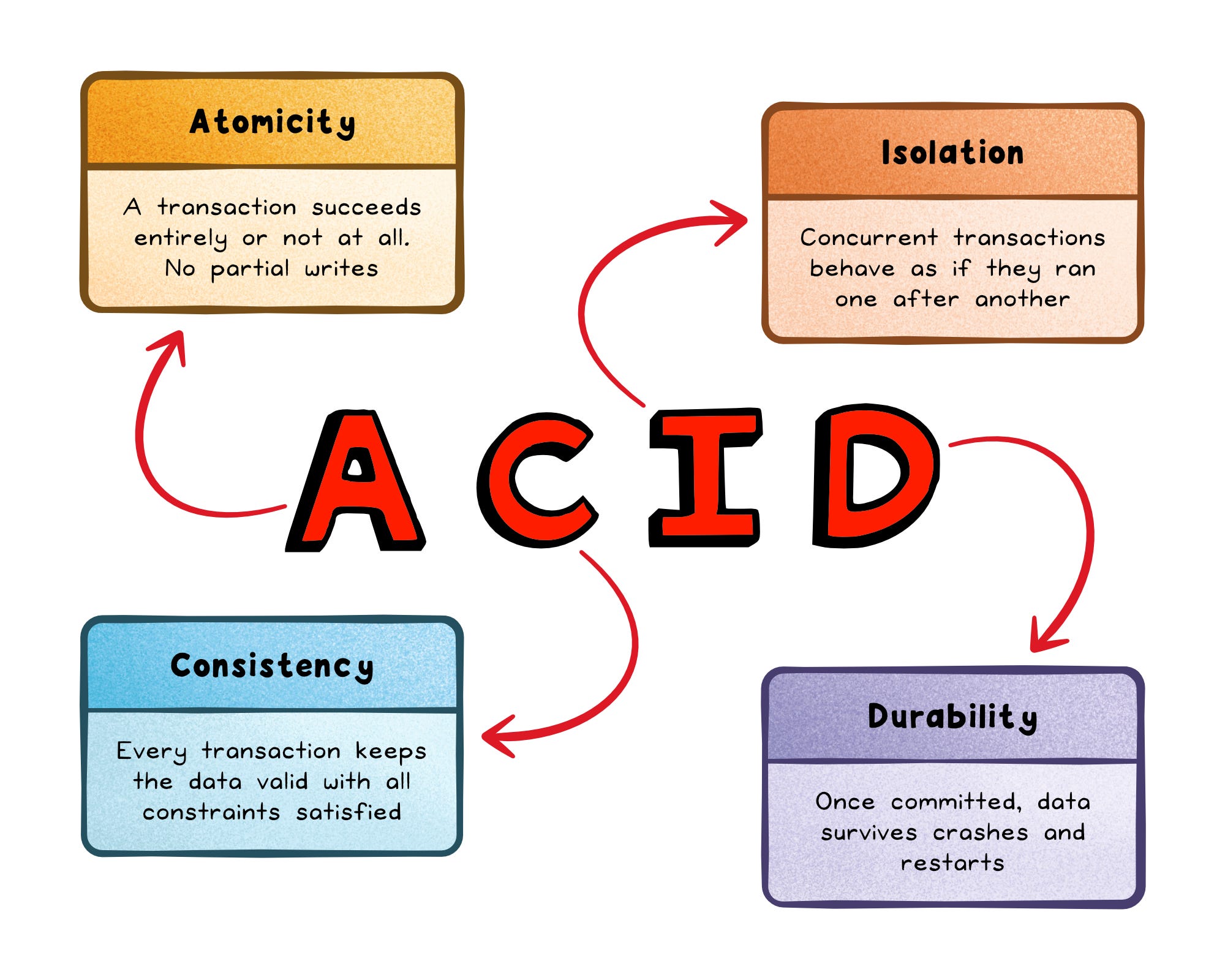
Think of a bank transfer: debit one account, credit another. In an ACID system, either both balance updates land or neither does. There is no state where money disappears or duplicates.
Why Teams Like ACID
Strong data integrity → You never see half-applied changes.
Simpler application logic → The database enforces consistency so you write less reconciliation code.
Mature ecosystem → SQL databases, tools, and operational practices are well understood.
Where ACID Hurts
Horizontal scaling → Global transactions and locks get expensive as you add nodes.
Latency under load → Locking, constraint checks, and write-ahead logs add overhead.
Availability in partitions → During network issues, an ACID system may reject requests rather than risk inconsistency.
When Not to Use ACID
Avoid a purely ACID approach when:
Global low latency is critical → Users are spread worldwide and you cannot afford cross-region transaction hops.
Slightly stale reads are fine → For feeds, analytics, or counters, strict freshness is overkill.
You mostly need write-heavy, append-only workloads → Log ingestion or metrics pipelines usually gain little from strict transactions.
BASE: Always Up, Eventually Right
BASE stands for Basically Available, Soft state, Eventually consistent.
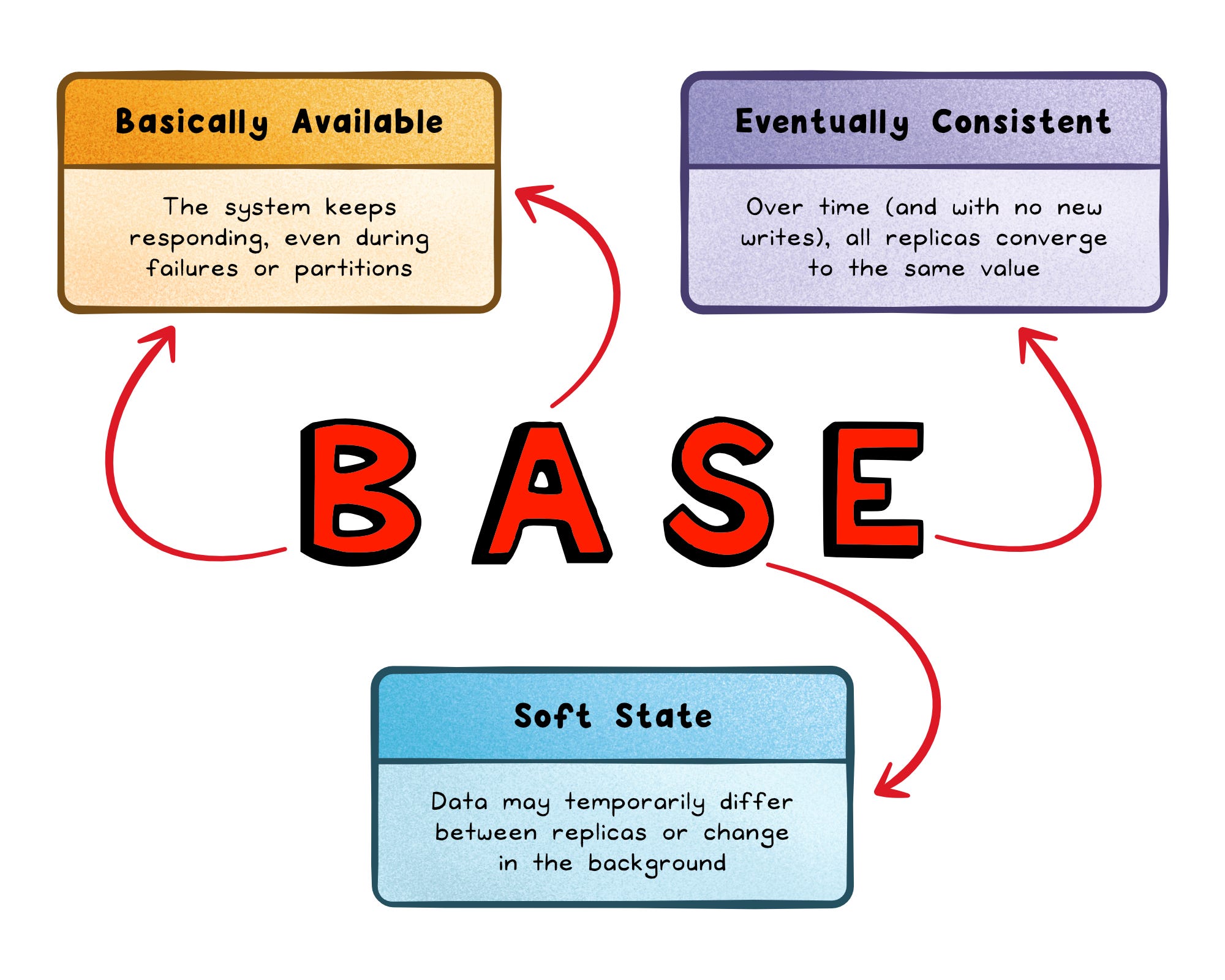
Imagine updating your social profile picture. You see the new image instantly; your friends might see the old one for a bit. The system stays fast and available, and the data settles eventually.
Why Teams Like BASE
High availability → The system prefers “some answer now” over “correct answer later”.
Horizontal scalability → Data is sharded and replicated without global locks.
High throughput → Asynchronous replication and optimistic concurrency reduce coordination costs.
Flexible models → Many BASE systems are NoSQL, handling dynamic or semi-structured data well.
Where BASE Hurts
Stale reads → Different replicas might disagree for a while.
Developer burden → You must design idempotent writes, conflict resolution, and reconciliation.
Weak invariants → “This must never happen” rules (like double-spend) are hard to enforce in real time.
When Not to Use BASE
Avoid a BASE-only approach when:
Violations are business-critical → Double billing, broken ledgers, or inconsistent medical records are unacceptable.
Multi-item atomicity is required → You often need to change several records together or not at all.
Regulatory audits demand a single, precise truth → Eventual fixes after the fact are not enough.
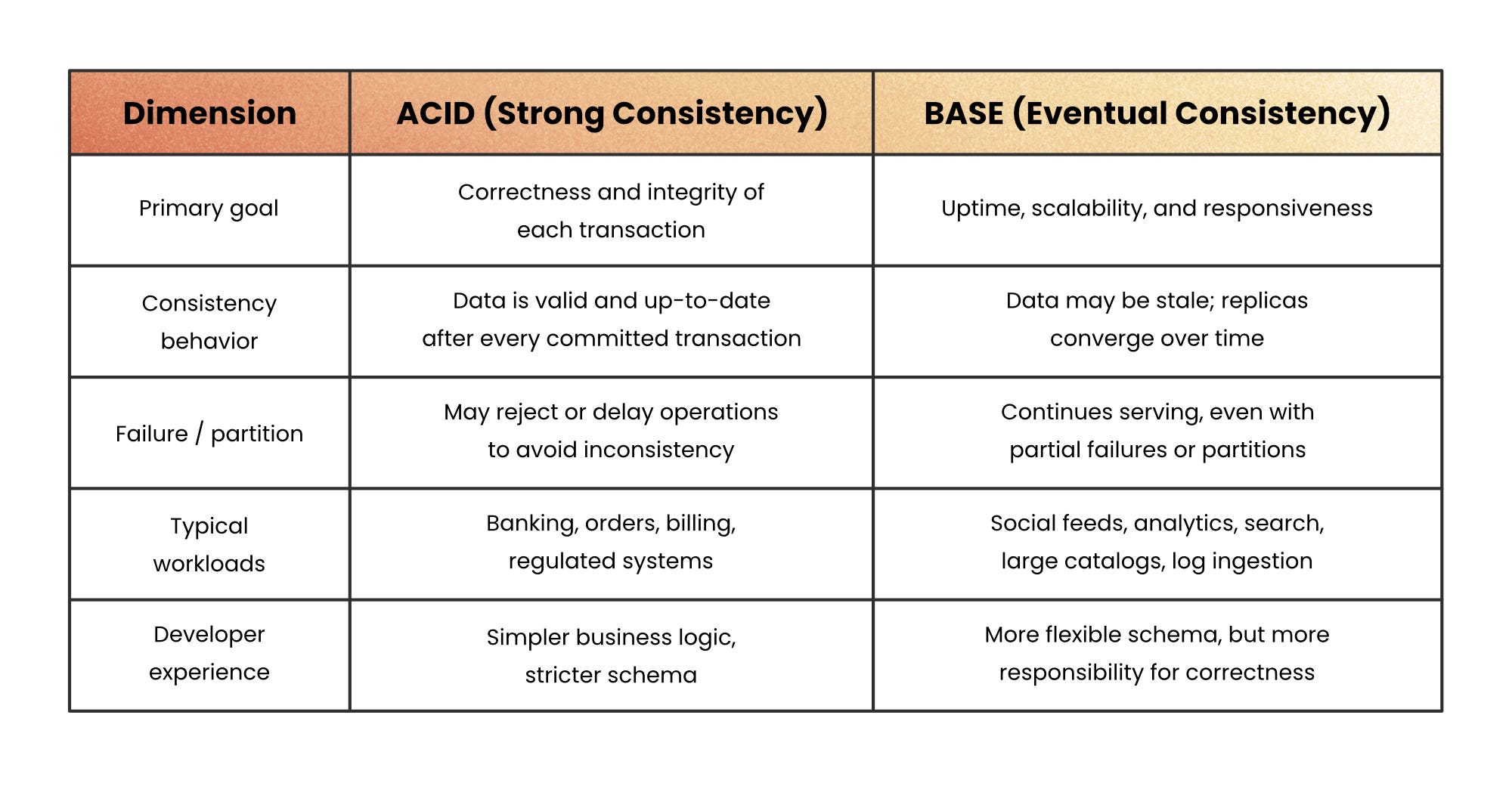
ACID vs BASE Side-By-Side
How to Choose (and When to Mix)
Choosing between ACID and BASE starts by asking what hurts your product more: returning incorrect data or returning no data.
Use ACID for the operations where a single wrong write breaks something fundamental; e.g. payments, inventory, identity changes, permission updates.
Use BASE for the parts of your system where scale and responsiveness matter more than perfect freshness; e.g. feeds, search, analytics, and any view that must stay online even during partial failures.
Most real systems mix the two because different workloads have different correctness needs.
A common pattern is to keep a small ACID core for operations that must always be correct, and use BASE layers to serve that data quickly across regions. The core keeps the truth safe; the edge keeps the system fast and available. If the data can’t be wrong, use ACID. If it can lag slightly or be rebuilt, use BASE.
Recap
ACID and BASE aren’t rivals; they’re tools for different failure modes and different expectations.
ACID protects the operations where correctness is non-negotiable. BASE keeps the rest of your system responsive when scale, geography, or partial failures make strict guarantees unrealistic.
The right choice depends on where mistakes matter and where speed matters. In practice, most architectures use both: ACID to set truth, BASE to spread it.
Designing with both in mind gives you something better than either model alone: a system that stays correct where it counts and stays fast everywhere else.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox:
Good one Nikki.
Here’s a deep dive I wrote about ACID, if anyone wants to check out.
Covered with practical examples along some deep dives as to what happens behind the scenes once you commit a transaction, that is the WAL logs.
Part 1 - https://pradyumnachippigiri.substack.com/p/relational-databases-and-acid-transactions
Part 2 - https://pradyumnachippigiri.substack.com/p/relational-database-and-acid-transactions
WAL logs - https://pradyumnachippigiri.substack.com/p/how-does-the-database-guarantee-reliability