
API Gateway vs Load Balancer vs Reverse Proxy
(5 min read) | Same edge, different responsibilities, how the wrong choice quietly creates failure modes, and more


Refactor with Context, Not Guesswork
Presented by Atlassian
Rovo Dev is Atlassian’s context-aware AI agent for the entire SDLC. One of the use cases where it excels is refactoring. It helps teams plan changes, generate consistent multi-file updates, and review pull requests against Jira acceptance criteria and Confluence context. Learn how Atlassian engineers used Rovo Dev and AI-driven workflows to safely refactor a large monorepo.
API Gateway vs Load Balancer vs Reverse Proxy
API gateways, load balancers, and reverse proxies are often grouped together as the same kind of component.
They all sit at the edge, forward requests, and are introduced when systems need to scale.
That surface-level similarity hides an important truth: each one exists to solve a different problem, and using the wrong component quietly creates new failure modes. Many production issues start here; not with bugs, but with blurred responsibilities at the edge.
Knowing how to categorize each component is what keeps your edge simple instead of fragile.
The One Decision Each Component Makes
If you remember nothing else, remember the verb each one optimizes for:
Load balancer → distribute traffic across identical copies of the same service.
Reverse proxy → forward + optimize traffic to one or more backends, often with caching, TLS termination, and routing rules.
API gateway → govern API traffic across many services: auth, rate limits, routing, transformations, and sometimes aggregation.
In practice, it’s like standing at a building entrance:
A load balancer points you to the least busy elevator (same destination, different car).
A reverse proxy sends you to the right department and might hand you a cached brochure instead of interrupting staff.
An API gateway does that and checks your badge, enforces rules, and sometimes translates what you asked for into what the building understands.
What Each One is Good at (and Why)
API Gateway: “One door” for many APIs
An API gateway is a single entry point for clients that need to call multiple backend services. It commonly acts like a reverse proxy plus API management features.
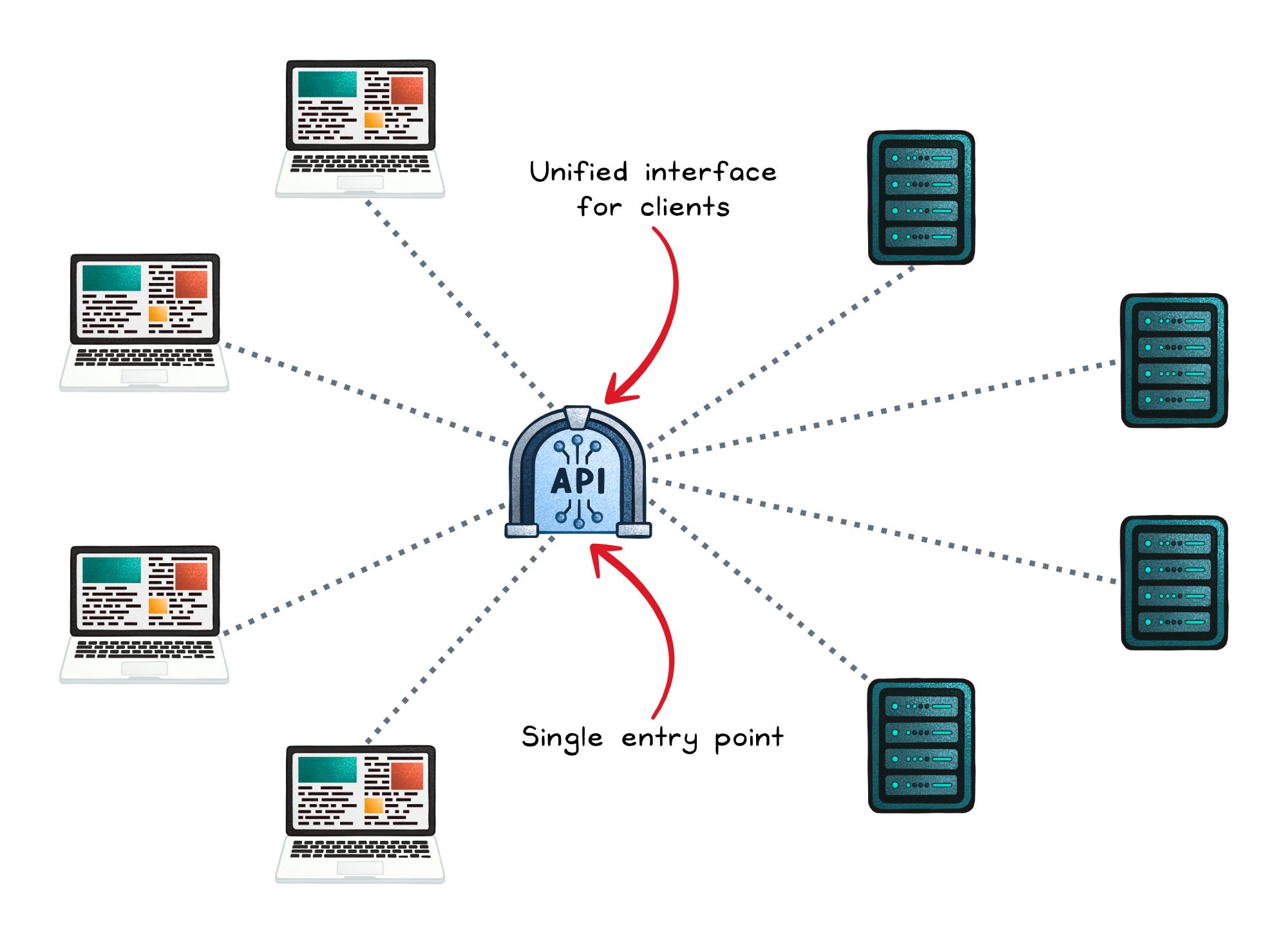
Typical jobs it handles well:
Authentication + authorization → Enforce consistent access rules once, not in every service.
Rate limiting + quotas → Stop one client from bringing down your fleet.
Request/response transformation → Convert formats, add/remove headers, normalize shapes.
API composition → Fan out to multiple services and aggregate a single response.
Protocol translation → Bridge HTTP/JSON clients to gRPC (or other) services.
Tradeoffs to plan for:
Added hop + processing → Auth checks and transforms add latency (often small, but real).
Operational criticality → If it fails, clients can lose their only entry point unless you build redundancy.
Config complexity → Lots of power means lots of ways to misconfigure routing/policies.
Load Balancer: “Spread work so nothing overloads”
A load balancer distributes incoming traffic across multiple servers so no single instance becomes the bottleneck. It usually performs health checks and avoids unhealthy instances, which is how it improves uptime.
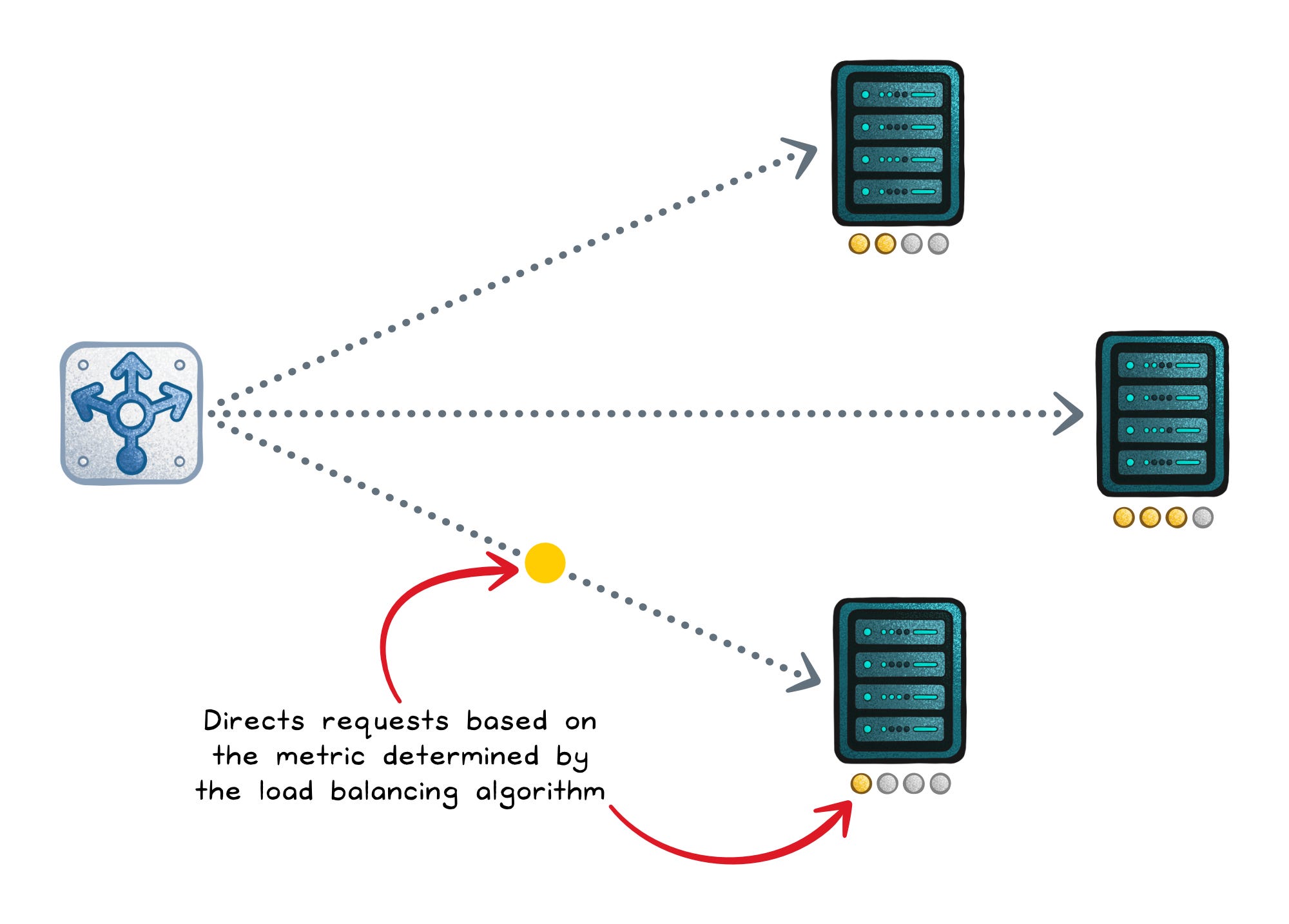
There are two important categories:
Layer 4 (L4) → Routes using IP/port; fast and protocol-agnostic, but content-blind.
Layer 7 (L7) → Understands HTTP and can route by path/headers/cookies.
What it’s great at:
High availability → Prevents traffic from being sent to unhealthy nodes.
Horizontal scaling → Add/remove instances and keep one stable client-facing endpoint.
Basic edge duties → TLS termination, sticky sessions (when you’re stuck with state).
Common gotchas:
“One LB instance” thinking → A load balancer can also be a single point of failure unless made redundant.
Expecting API policy features → It’s not designed for per-endpoint auth, transforms, or analytics.
Reverse Proxy: “Front the servers, hide them, and speed things up”
A reverse proxy sits in front of backend servers, forwards requests on their behalf, and makes the backend topology invisible to clients. It typically operates at the application layer (L7) and can make routing decisions based on request content.
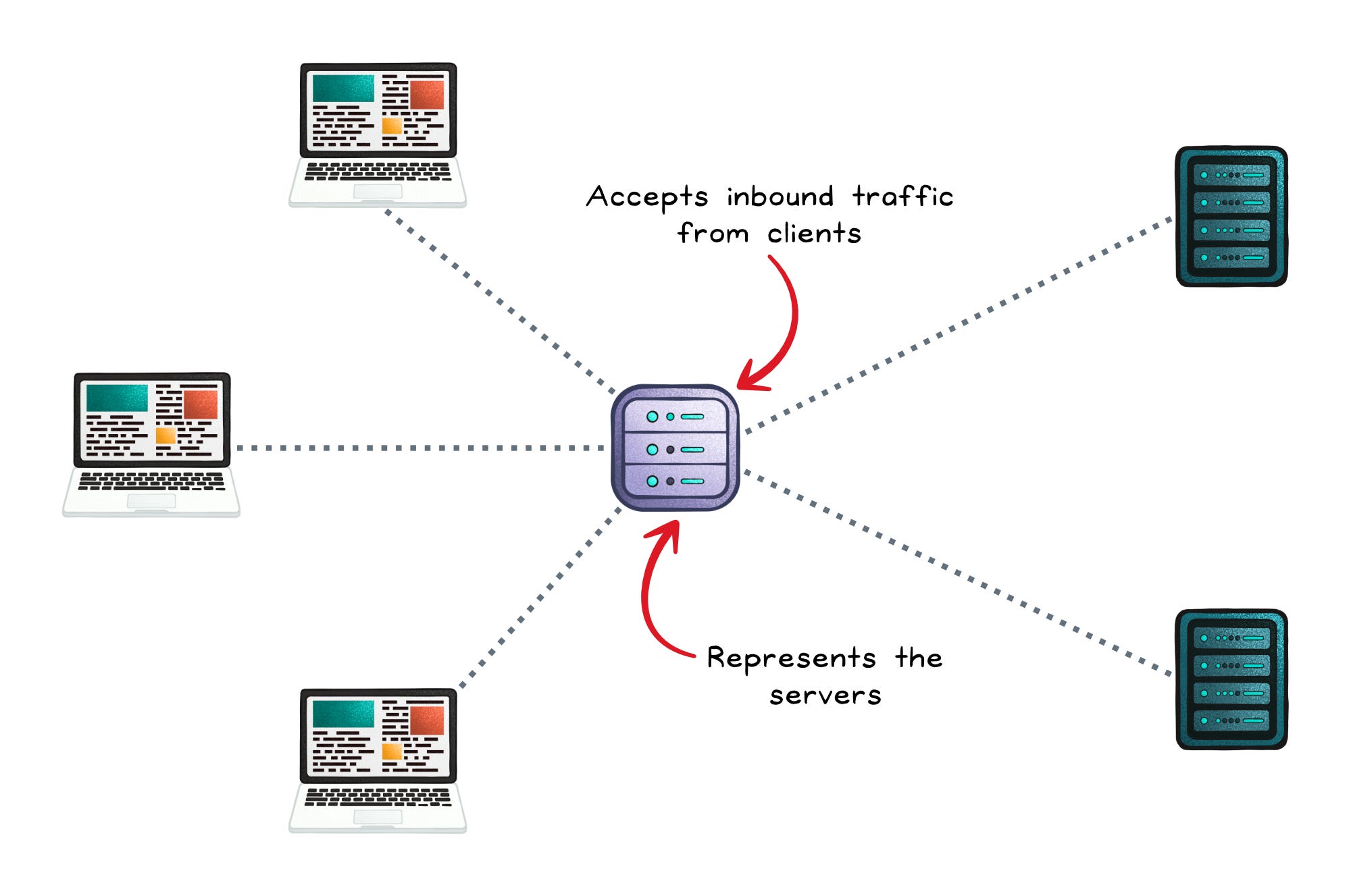
Where they add the most value:
TLS termination → Handle certificates centrally so app servers don’t have to do the encryption work.
Caching + compression → Serve common responses fast, reduce backend load and bandwidth.
Security shielding → Hide backend IPs and filter obvious bad traffic before it lands.
Routing + rewriting → Map clean external paths to messy internal routes.
“Good enough” load balancing → Many can round-robin across a small pool of backends.
Its limits are mostly scope:
It’s not full API management → You won’t get rich per-consumer quotas, developer portal concepts, or deep API analytics by default.
It’s still a choke point → Needs redundancy and careful config like anything in the hot path.
Quick Comparison: Same Edge, Different Responsibilities
When these components get confused, it’s usually because they’re compared by features. A clearer comparison looks at what responsibility each one owns. The table below strips things back to first principles so you can see where overlap is intentional; and where it’s a smell.
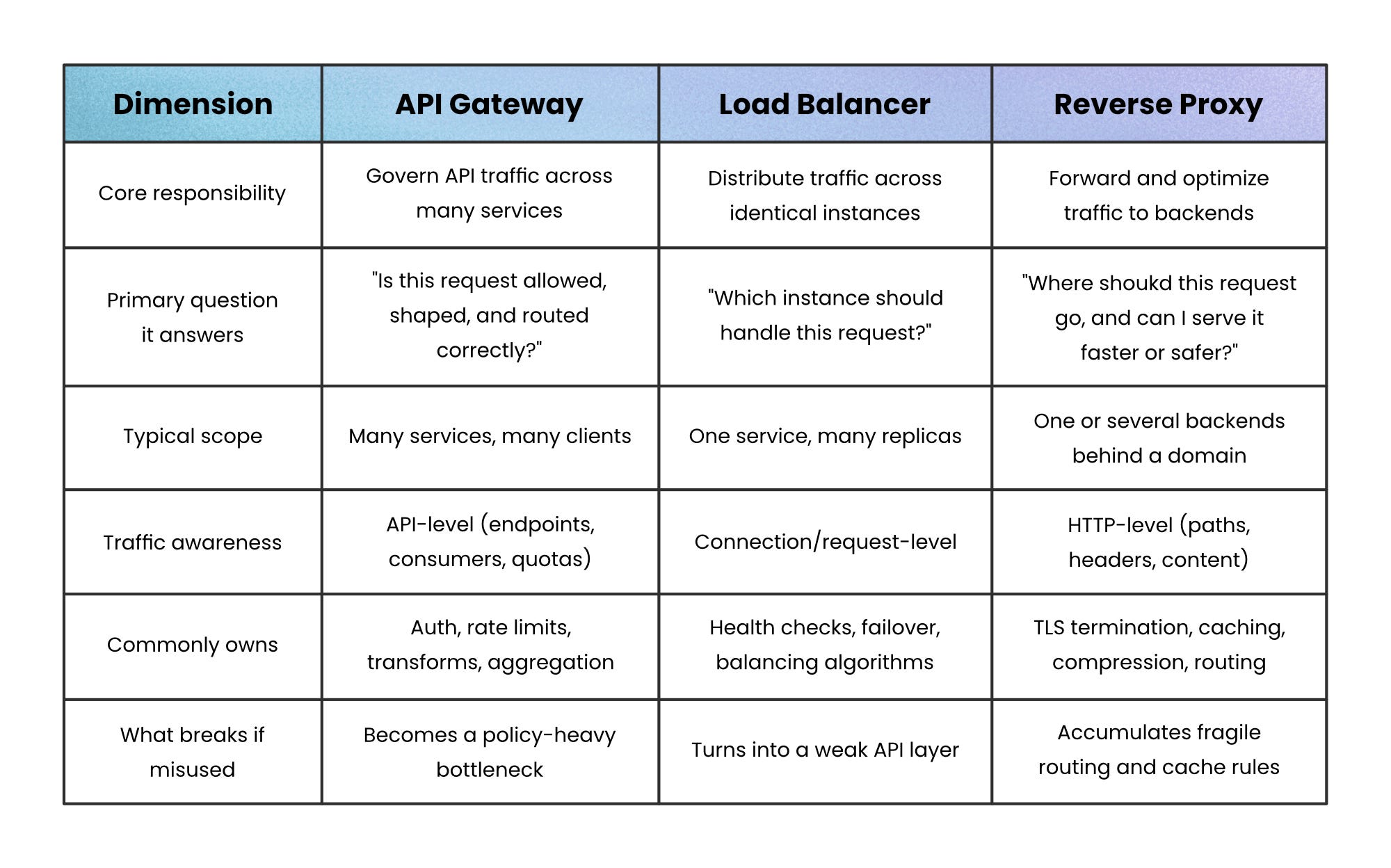
Seen this way, the overlap makes sense.
All three sit at the edge, but each one draws the boundary in a different place.
Choosing the Right Tool (and Avoiding the Wrong One)
Most edge mistakes come from reaching for a tool because it’s available, not because it matches the problem.
These components overlap in capability, but they should not overlap in responsibility.
Start by being clear about your context and requirements:
Many replicas of the same service → use a load balancer, because the core problem is distributing work safely and evenly.
One domain with multiple backends and performance concerns → use a reverse proxy, because it can route, cache, and protect without API-level policy overhead.
Many services behind a single public API → use an API gateway, because clients need consistent rules, simplified access, and sometimes response aggregation.
These tools are not mutually exclusive.
Larger systems often layer them deliberately: a gateway for API policy, a load balancer for instance-level distribution, and reverse proxies where caching or TLS termination reduce pressure downstream.
The key is intent.
Each component should earn its place by owning a single, clear responsibility. If it can’t explain why it’s there, it’s probably doing too much; or shouldn’t be there at all.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox:
I love it.