
Batch Processing vs Real-time Streaming
(5 Minutes) | Core Ideas, Benefits, Drawbacks, Where and When to Use Each


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Every PagerDuty Paid Plan Now Includes Full Incident Management
Presented by PagerDuty
Most teams fix incidents. The best teams learn from them.
I’ve worked with teams that resolved incidents in minutes, then made the same mistake a month later. Most teams are great at fixing things, but terrible at learning from them.
Why? Because their post-incident reflection was broken. Either post-incident reviews never happened, or they happened too late, with documentation scattered across 17 different Slack threads, and no follow-through.
The best-in-class way to go about this is to use a comprehensive incident management tool like PagerDuty. Their AI-powered post-incident reviews make learning from incidents much easier.
Batch Processing vs Real-time Streaming
When building data pipelines, two paradigms dominate: batch processing and real-time streaming.
Both aim to turn raw data into insights. But they optimize for different tradeoffs across latency, complexity, and cost.
Let’s unpack them!
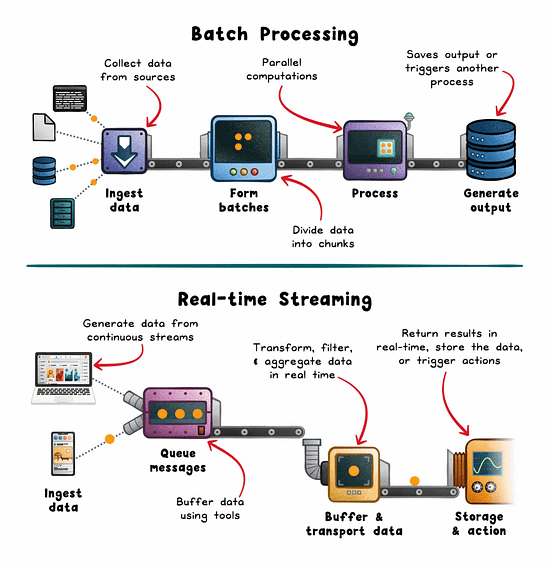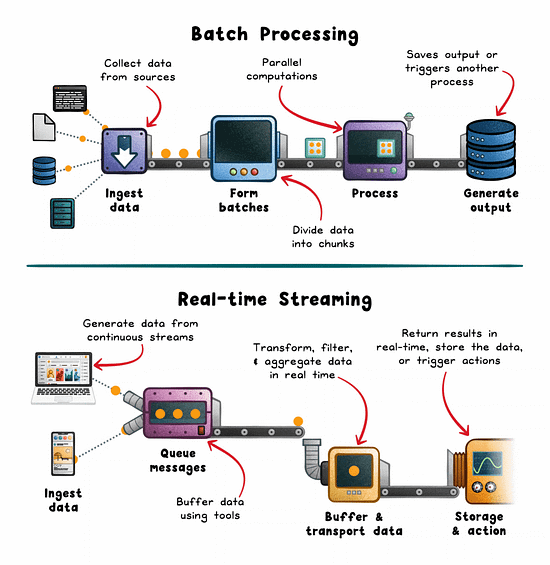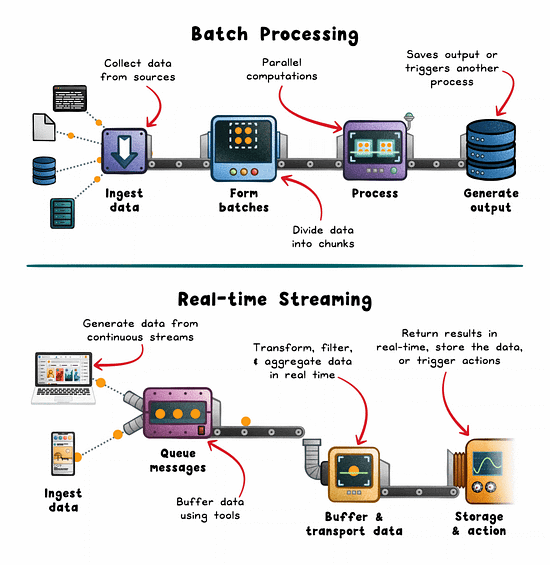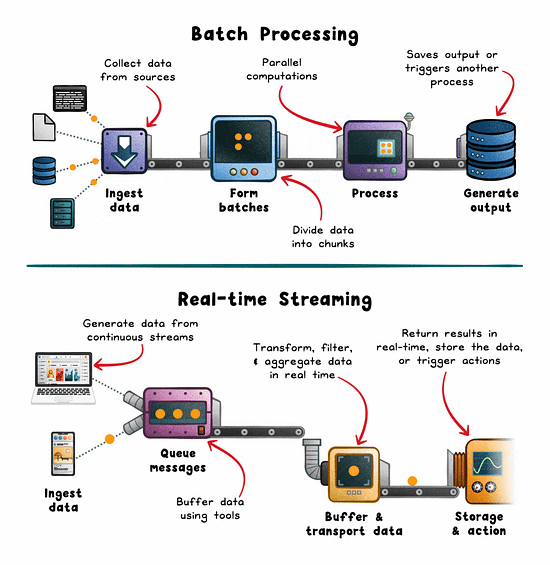
Batch Processing: The Workhorse of Historical Analysis
Batch processing operates on large volumes of data collected over a defined window. Hours, days, or weeks. It’s ideal when latency isn’t critical and efficiency is the priority.
Common use cases:
Daily business intelligence dashboards
Periodic ETL for warehousing
ML model training on historical data
Backfilling gaps in production pipelines
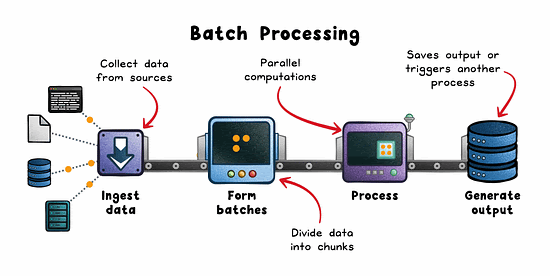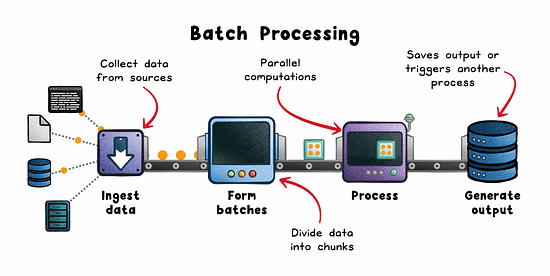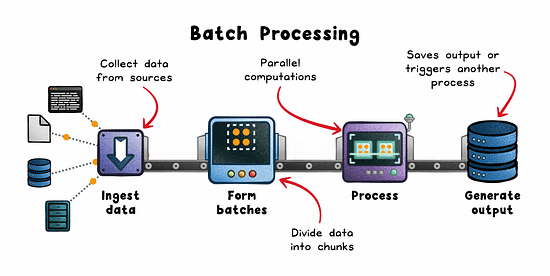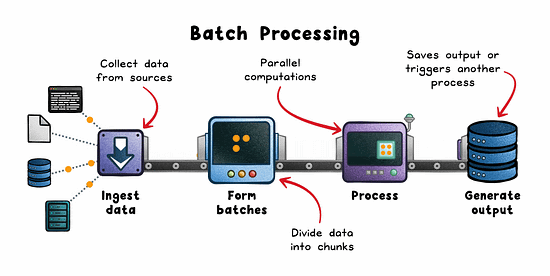
How it works:
Data is pulled from sources like logs, lakes (eg; S3), or OLTP databases.
Split into batches by time or volume.
Distributed engines (eg; Spark, Hadoop, AWS Glue) process in parallel.
Results are stored or consumed downstream.
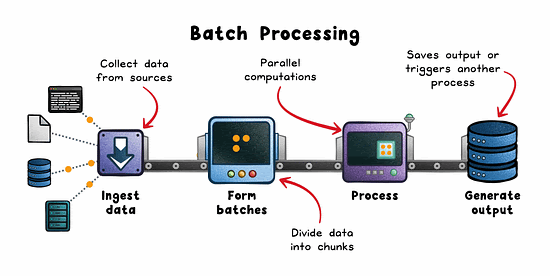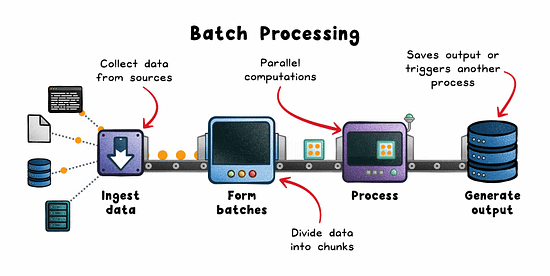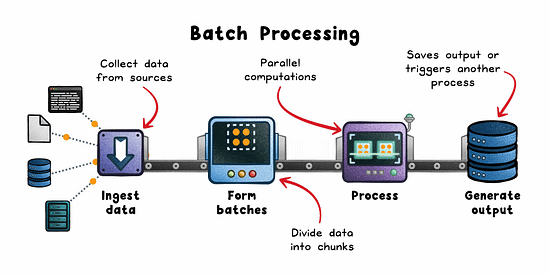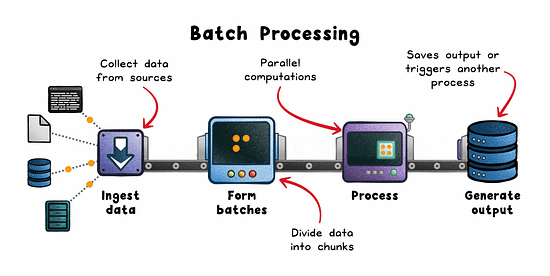
Strengths:
High throughput for large datasets
Simpler to operate and debug
Cost-effective for non-real-time workloads
But it’s inherently retrospective. If your SLA demands real-time insight, batch won’t cut it.
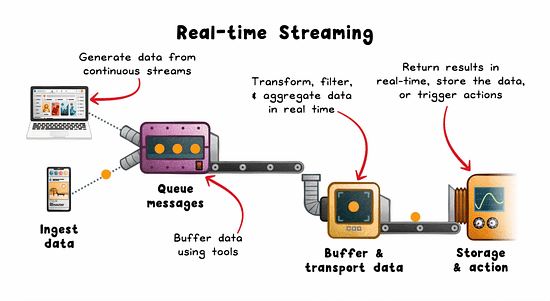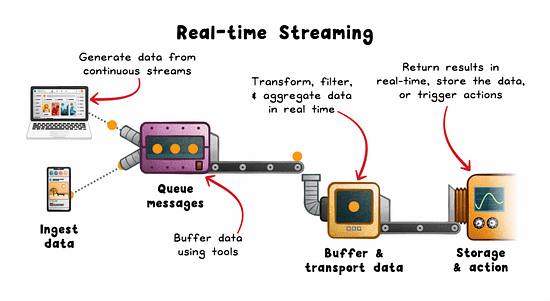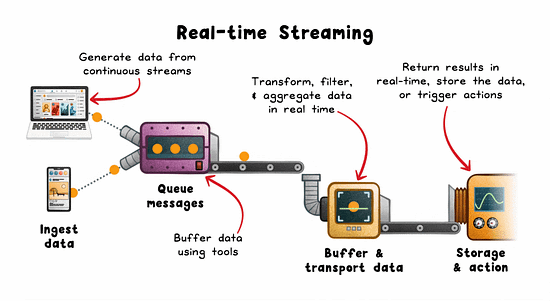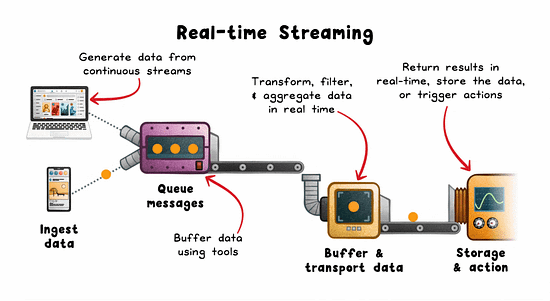
Real-time Streaming: The Engine Behind Instant Feedback
Streaming pipelines minimize the delay between event generation and system response. Instead of waiting for a full dataset, you process each event as it arrives.
Common use cases:
Real-time metrics and alerts
Fraud detection
IoT telemetry processing
Personalization (eg; recommender systems)
How it works:
Events are emitted from sources (sensors, mobile apps, services).
Buffered via brokers like Kafka, Kinesis, or Pulsar.
Stream processors (eg; Flink, Spark Streaming, Beam) apply transformations.
Results trigger alerts, update live UIs, or feed downstream systems.
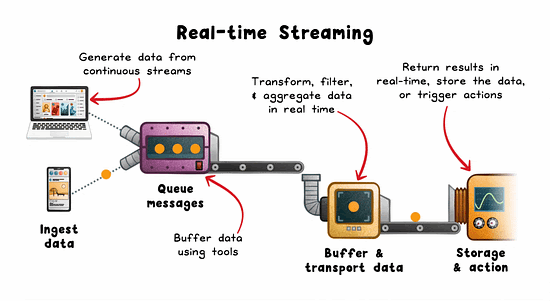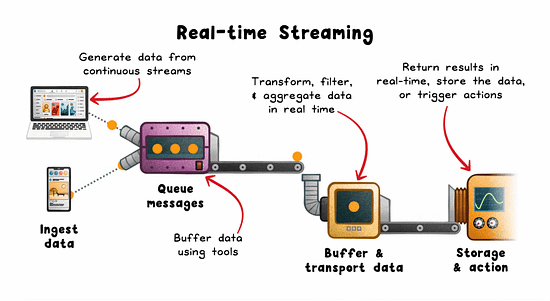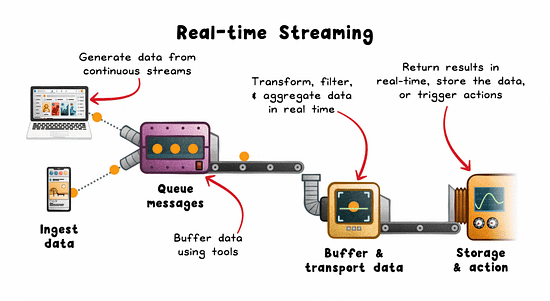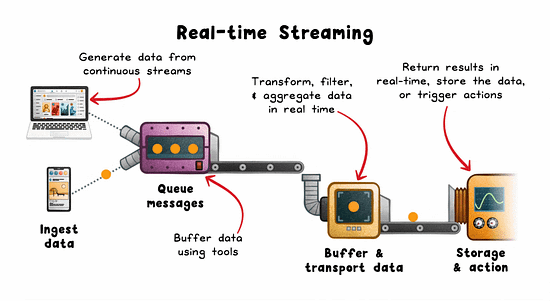
Strengths:
Sub-second latency
Reactive, always-on systems
Scales with high-velocity, high-volume inputs
But streaming introduces operational complexity: maintaining long-running jobs, handling backpressure, ensuring fault tolerance, and managing state across failures.
Key Tradeoffs to Consider
Streaming also brings harder tradeoffs around data consistency:
At-most-once: Fastest but may drop data
At-least-once: Can cause duplicates
Exactly-once: Ideal but harder to guarantee and more expensive to achieve
You’ll need to account for idempotency, checkpointing, and state recovery to get this right.
Most Real-world Systems Use Both
In production, hybrid patterns are common:
Lambda architecture: Runs both a batch layer (for completeness and correctness) and a streaming layer (for low-latency views) in parallel. Outputs from both layers are merged to serve analytics or product features.
Kappa architecture: Simplifies the pipeline by treating all data as a stream. Even reprocessing is done by replaying from a durable event log (like Kafka), eliminating the need for a separate batch system.
For example, a fintech platform may stream transaction data to detect fraud in real time, while also running nightly batch jobs to reconcile ledgers and generate compliance reports.
Final Thoughts
The choice between batch and streaming isn’t about preference.
It’s about the latency your product can tolerate, the volume your infrastructure can handle, and the correctness guarantees your domain requires.
Get those tradeoffs right, and your data stack becomes a competitive edge, not a bottleneck.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: