
Bloom Filters Clearly Explained
(5 minutes) | Most systems waste time proving what isn’t there. Bloom filters make “no” almost free.


AI Gets Better When Work is Specialized
Presented by Atlassian

Planning, coding, testing, and reviewing are different kinds of work. When one AI tries to do everything, quality drops. Rovo Dev addresses this with focused subagents that operate inside the terminal, reasoning over Jira, Confluence, and repo history via Atlassian’s Teamwork Graph. Each agent owns a narrow responsibility, enabling workflows that scale without losing context or control.
Bloom Filters Clearly Explained
You don’t notice it, but your system wastes more time proving what isn’t there than what is.
Every cache miss, every 404, every “not found” database query costs real CPU, I/O, and bandwidth; all to confirm a negative.
That’s where Bloom filters quietly shine.
They don’t store data; they store possibility. Instead of asking “is this in the set?” and paying full price every time, you ask a probabilistic gatekeeper first.
It answers instantly: definitely not or maybe, go check.
The trick is in accepting a sliver of uncertainty to save massive compute.
When “no” becomes the most expensive answer
Every large system eventually asks the same question: does this exist?
A URL, a user ID, a cache key, a file chunk; all get checked millions of times per second.
That check feels cheap, until you multiply it by scale.
Take a web crawler. It must avoid re-fetching URLs it’s already seen. The obvious solution is to keep every URL in a hash set. Simple, until “every” means billions. Even with compact encoding, that’s terabytes of memory just to remember what you’ve touched. Skip the memory, and you waste bandwidth re-downloading duplicates instead.
At scale, “no” dominates.
Most URLs are new. Most cache lookups miss. Most database keys aren’t there. Yet every query costs the same as a hit: full network calls, disk reads, and CPU time just to confirm nothing exists.
What you really need isn’t a full record of the past, just a cheap way to say “definitely not.”
You don’t care which URLs you’ve seen, only whether something could have been seen before.
Bloom filters help turn expensive “no” answers into near-free ones. What you trade up is a small, controllable chance of being wrong for a massive gain in speed and space.
How it works
A Bloom filter answers one question fast: could this exist?
It does it without storing the item, just a few bits of evidence that it might have been seen before.
Here’s how it works:
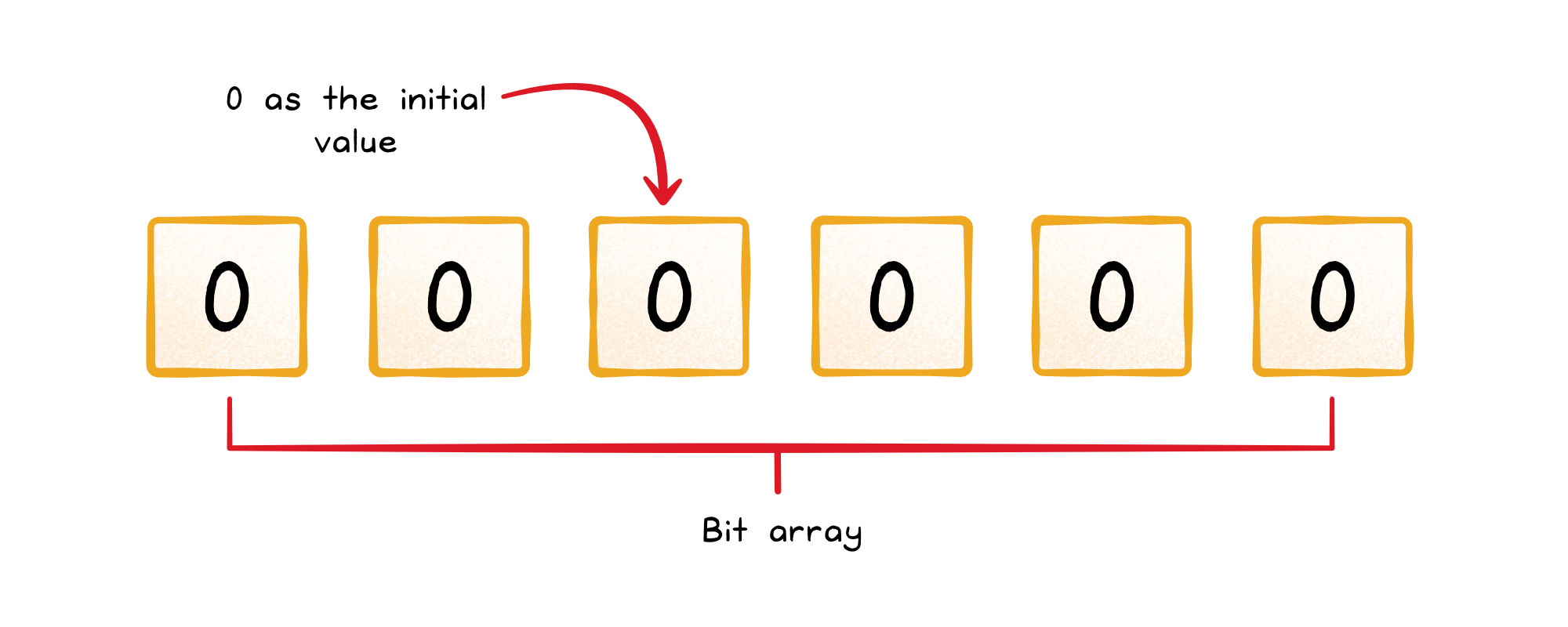
Start with an empty bit array.
Picture a long row of bits, all set to 0. This is your blank canvas.
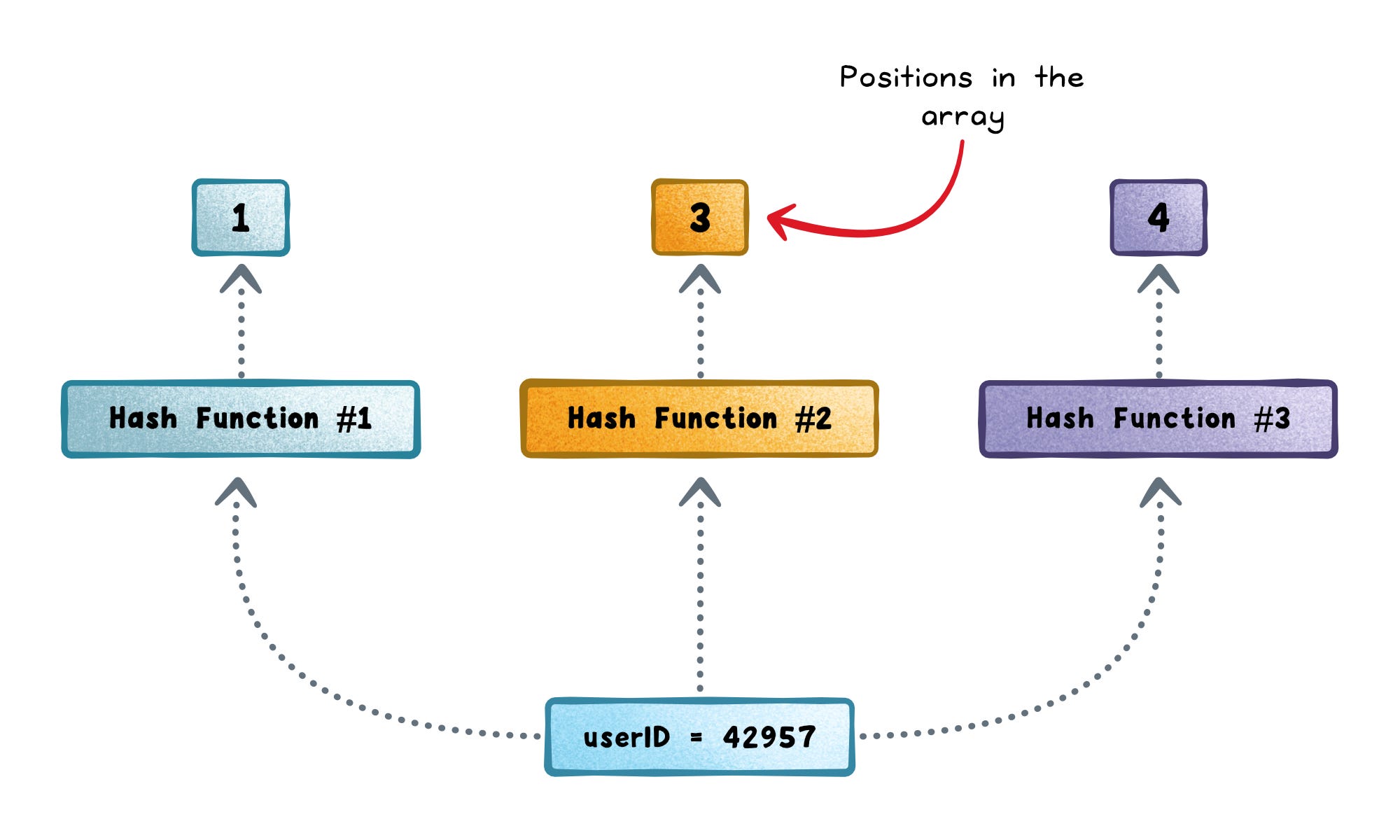
Hash the input several times.
Each item (a URL or user ID) is fed into a number of different hash functions.
Each hash produces an index which is a position in the bit array.
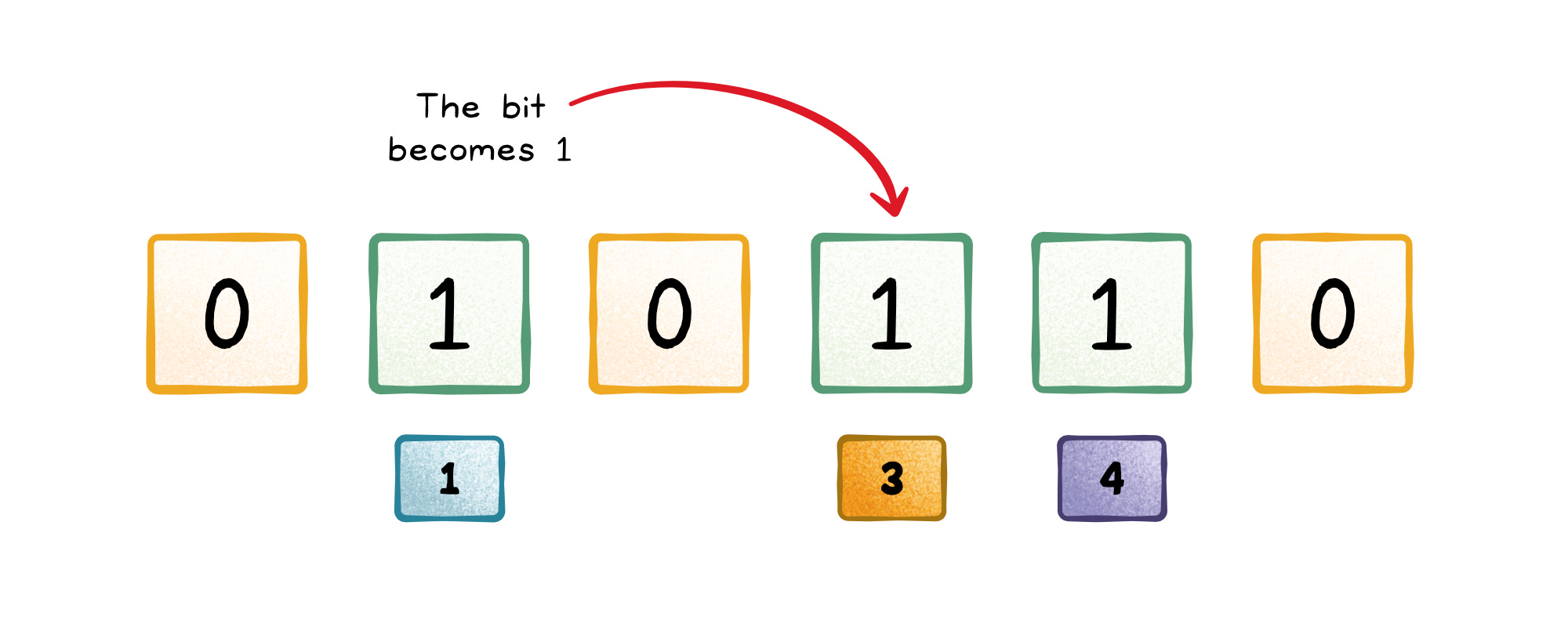
Set those bits to 1.
For every hash output, that bit becomes 1. You never store the item itself, just the pattern of bits it activates.
To query, repeat the hashes.
When you check if something exists, you hash it again across all hash functions and see which bits it maps to.If any of those bits are 0 → the item definitely doesn’t exist.
If all are 1 → it might exist.
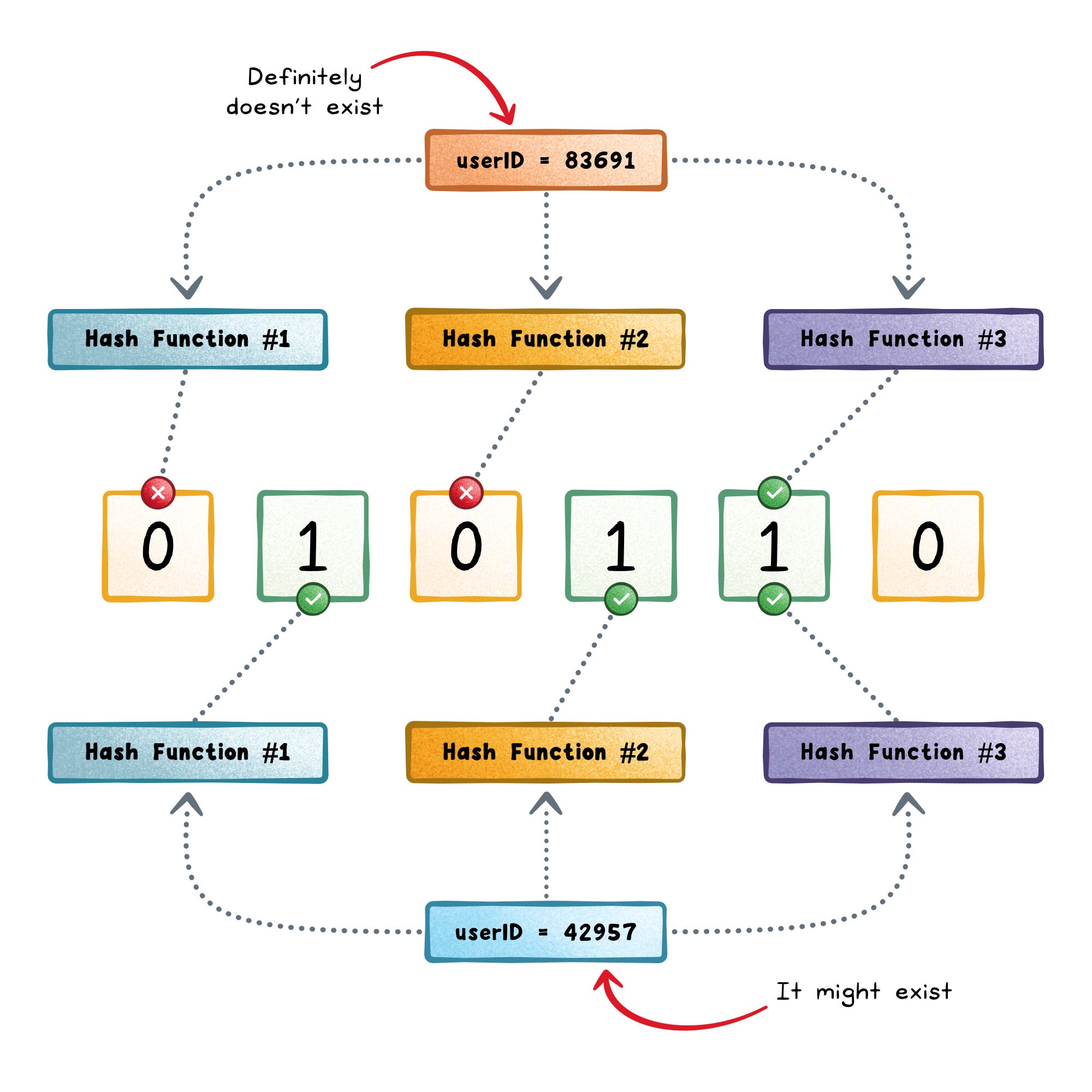
A Bloom filter never gives false negatives: if you inserted it, it will always return “maybe.”
But it can give false positives.
The more items you insert, the more bits flip to 1, and the higher the chance that unrelated items collide.
The trick is that you can tune this probability by the number of hash functions you use.
Each hash function sets one more bit in the array. Too few, and the filter doesn’t mark enough spots; it forgets what it’s seen and returns more false positives. Too many, and it flips too many bits; the array fills up faster, and collisions rise, again increasing false positives.
There’s a sweet spot where the filter stays balanced: enough hashes to remember patterns, but not so many that everything looks like a match.
That balance is what makes Bloom filters powerful. You decide how much uncertainty you can afford, and trade a bit of it for massive savings in efficiency.
Where they’re used
You’ve probably relied on Bloom filters without realizing it. They hide inside the systems that need to skip pointless work fast.
Databases → Engines like Cassandra, LevelDB, and Bigtable use Bloom filters to skip disk reads for keys that don’t exist. This cuts random I/O and keeps “not found” queries cheap.
Web crawlers → Track which URLs have been seen before. Instead of storing billions of strings, a Bloom filter flags duplicates in memory and saves massive bandwidth.
Browsers and security tools → Chrome Safe Browsing and spam filters use them to pre-check URLs or sender lists locally, calling a remote service only when there’s a “maybe.”
Distributed caches → Systems like CDN edge caches use them to decide if an object might exist on another node before sending a request.
Stream processors → Platforms like Kafka Streams and Flink use them to drop duplicate events before aggregation or storage.
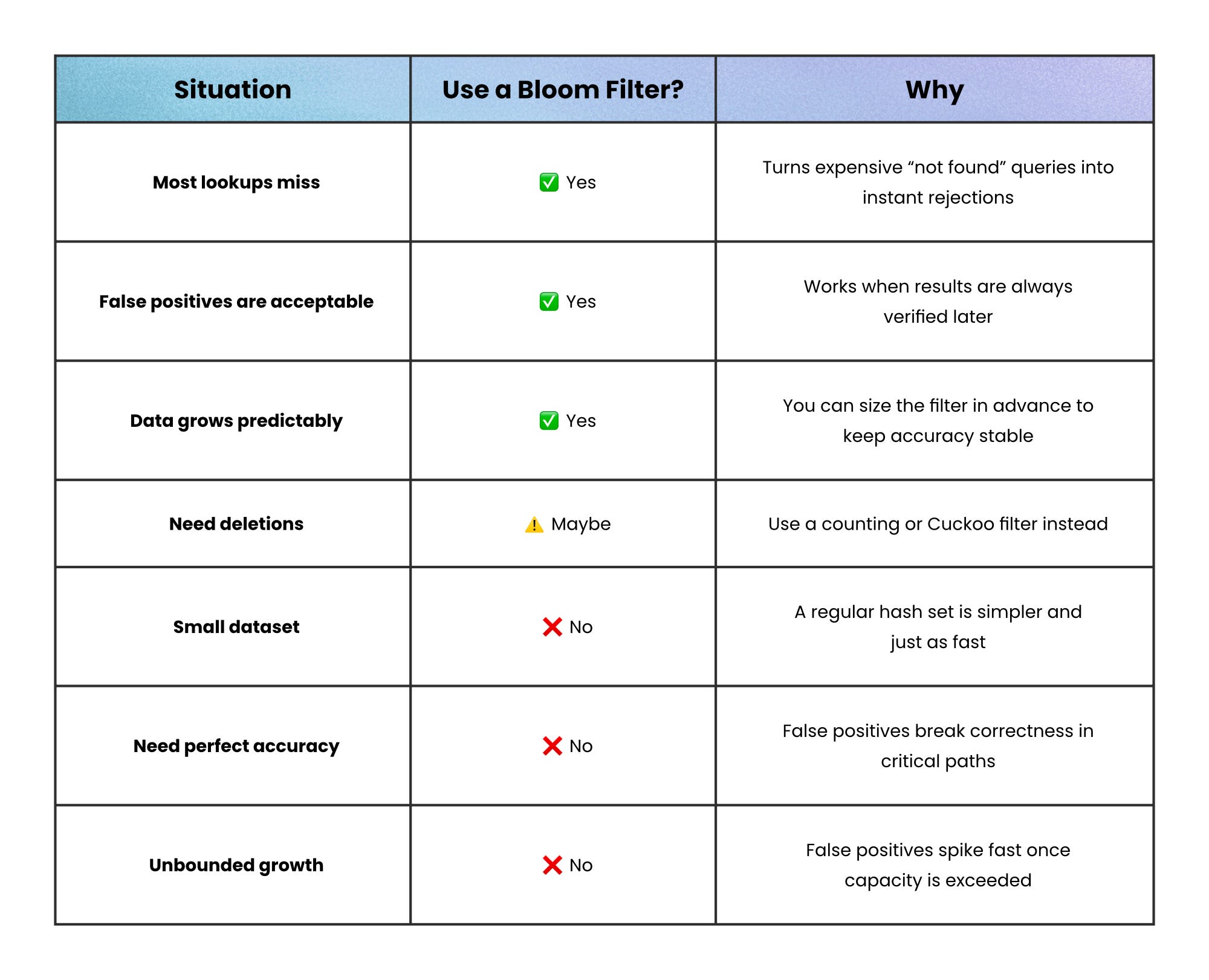
When not to use a Bloom filter
Bloom filters are powerful, but they’re not for every job.
They work best when most lookups miss and precision doesn’t matter. When the cost of being wrong outweighs the savings, the same trick that speeds you up can quietly hurt you.
Here’s when a Bloom filter isn’t worth that cost:
You need exact answers → Bloom filters always allow false positives. If a wrong “maybe” breaks correctness (like in billing, access control, or authentication) use an exact set or index instead.
You need frequent deletions → Standard Bloom filters can’t remove items. Once a bit is set, it stays set. Counting or Cuckoo filters solve this, but with more memory and complexity.
Your dataset is tiny → If you’re only tracking thousands of items, the math doesn’t pay off. A normal hash set fits in memory and stays simpler to maintain.
Your data grows unpredictably → Bloom filters must be sized in advance. Exceed that capacity and false positives spike fast. Use scalable variants if growth is unbounded.
Putting it into practice
Bloom filters make sense when the goal is speed, not certainty.
They shine when most lookups miss, when wasted work costs more than a small chance of being wrong, and when you can live with “maybe” as an answer.
Bloom filters remind us that at scale, certainty is overrated.
They don’t try to know everything; just enough to skip what doesn’t matter.
When most of your system’s time goes to proving nothing exists, a fast “maybe” is all you need.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, clear, and visual system design breakdowns straight to your inbox:
Nice write-up on what can be a tricky subject!
Good one Nikki. Here’s an article on bloom filters I’d written, would love if I could get your eyes on this - https://pradyumnachippigiri.substack.com/p/the-power-of-bloom-filters-in-system