
CAP Theorem Clearly Explained
(4 minutes) | Choosing your failure mode, avoiding common mistakes, and a decision checklist.


Build AI Apps with MongoDB
Presented by MongoDB

Looking to stay ahead of the curve on AI? MongoDB AI Learning Hub has the technical training pathways and tools you need to level up your AI app-building game. Explore practical guides, tutorials, and quick starts for all skill levels, from foundational concepts like understanding AI tool stacks to advanced implementations using RAG, MongoDB Vector Search, and LLM optimization.
CAP Theorem Clearly Explained
“Make it consistent, highly available, and fault-tolerant” sounds like a reasonable requirement.
It isn’t.
In any distributed system, a network failure forces a choice that no amount of engineering can avoid: either your nodes agree on the truth and some requests fail, or every request gets an answer and some of those answers are wrong.
Both are valid designs, and CAP Theorem is the lens that makes that tradeoff explicit so you choose deliberately instead of by accident.
What is CAP Theorem?
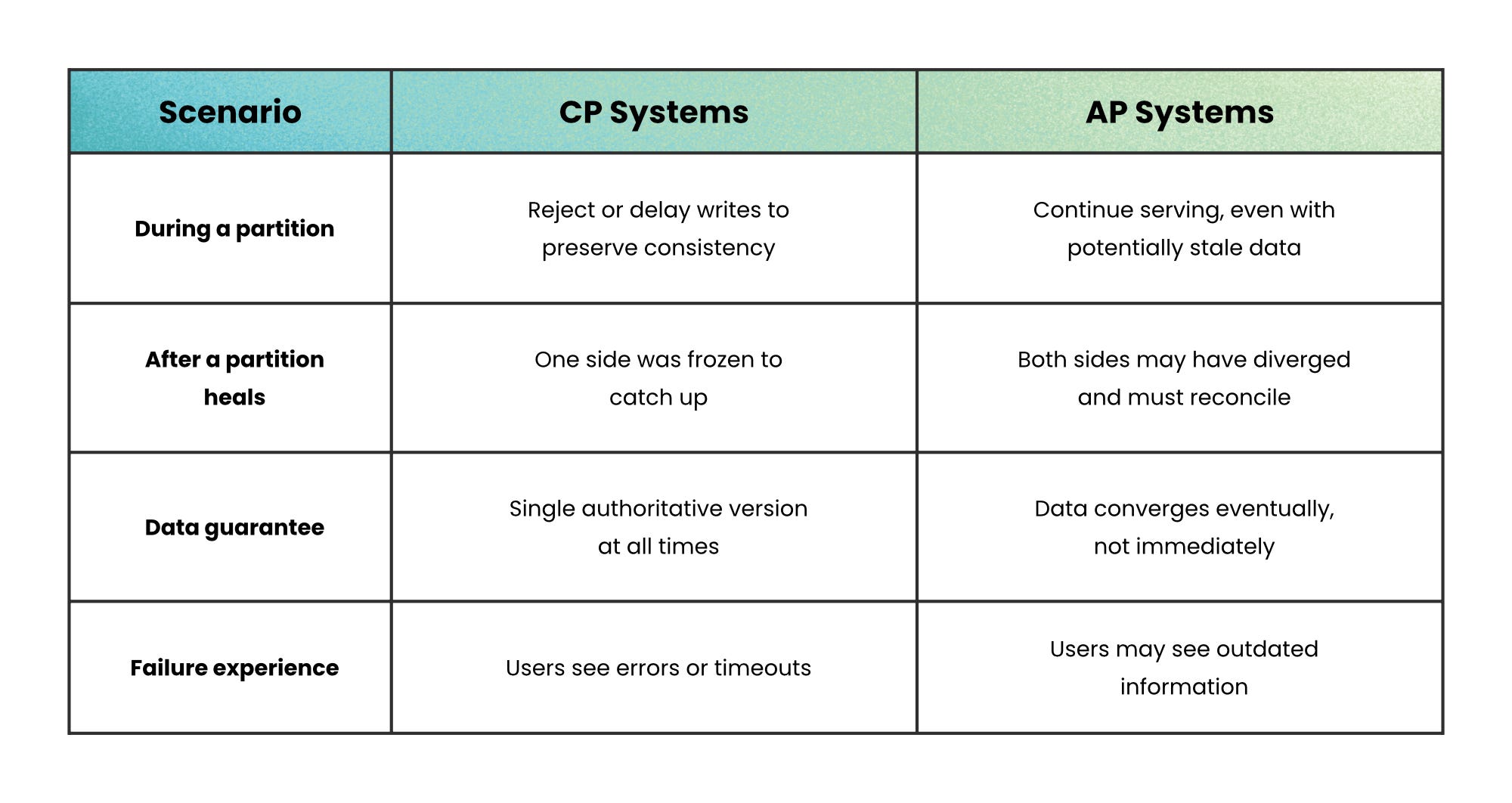
CAP Theorem states that a distributed data store cannot simultaneously guarantee all three of the following properties at the same time:
Consistency (C) → Every read returns the most recent write, or an error; never stale data.
Availability (A) → Every request receives a response, even if some nodes are out of date.
Partition Tolerance (P) → The system keeps operating despite network failures that split nodes into isolated groups.
The common summary is “pick two of three.”
It’s catchy, but misleading.
CAP is not about permanently giving something up. It’s about what happens when the network splits.
A clearer way to look at it: when a partition occurs, you must choose between consistency (all nodes agree on the same data) and availability (every request receives a response).
During normal operation, when nodes can communicate reliably, you can have both.
The tradeoff only appears the moment the network breaks.
CP vs AP: two different failure philosophies
Systems that lean toward Consistency + Partition Tolerance (CP) will refuse or delay operations when they can’t guarantee a single, up-to-date view of the data. They’d rather return an error than return something wrong.
Systems that lean toward Availability + Partition Tolerance (AP) will keep serving requests even when nodes disagree, accepting that some responses may be stale. They’d rather serve something than serve nothing.
How a partition actually plays out
A partition occurs when there’s a network split and nodes can’t reliably talk to each other.
Imagine a five-node cluster. A network failure divides it into two groups: three nodes on one side, two on the other.
CP behavior
CP systems preserve a single source of truth by refusing to make progress without enough agreement.
Quorums/consensus → Writes (and sometimes reads) require enough nodes to agree.
Leader-based replication → Only one leader can accept writes; the other side of a split becomes read-only or errors out.
User experience → Some users see failures/timeouts, but you avoid split-brain state.
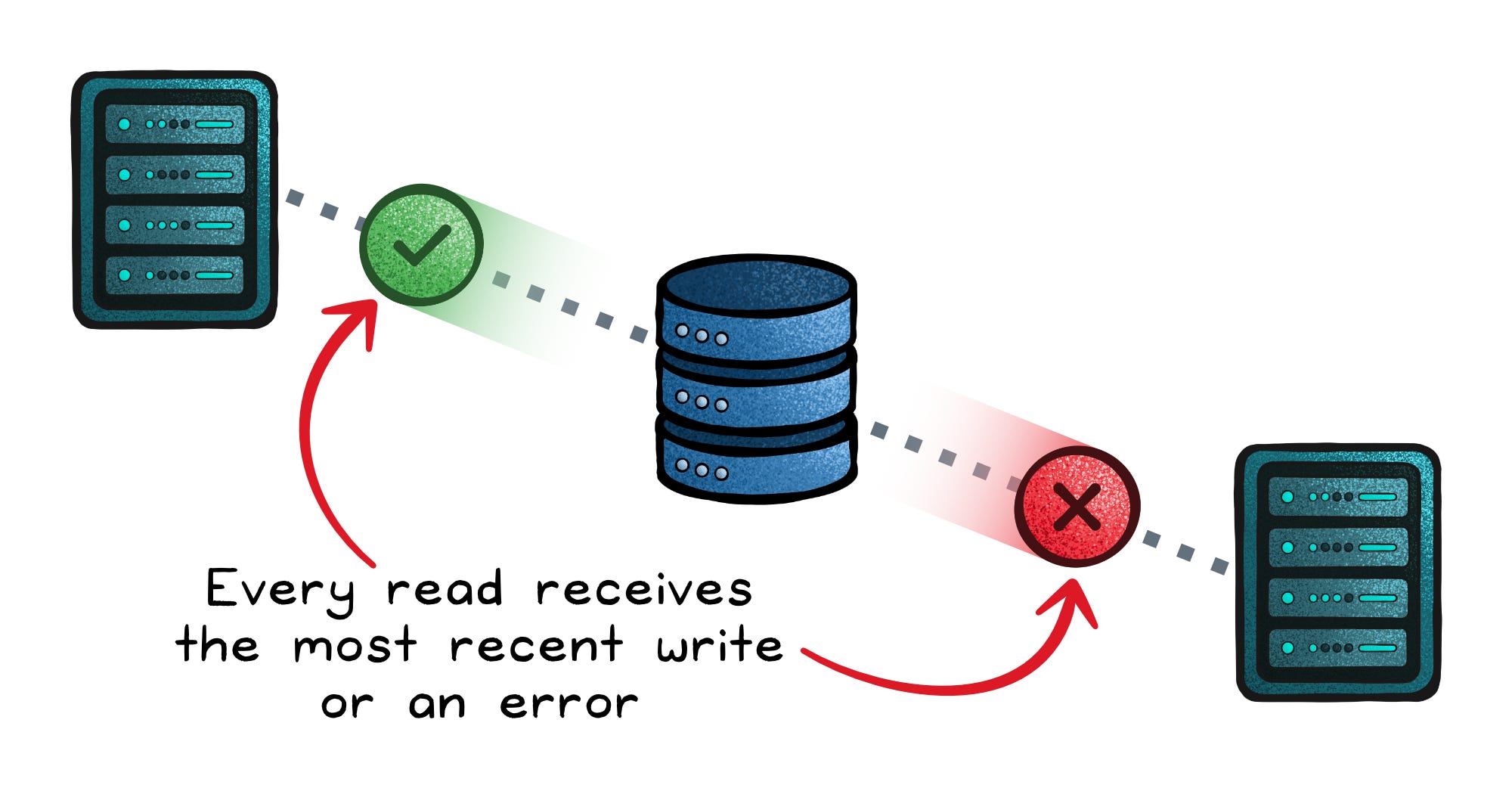
The three-node side has a majority, so it continues processing requests.
The two-node side does not, so it stops accepting writes. It may become read-only or fully unavailable.
When the network heals, the minority side syncs from the majority. There is no data conflict because only one side was allowed to move forward.
The result is clean, but some users saw errors or timeouts during the split.
AP behavior
An AP system keeps accepting operations on each side of the partition and repairs the mismatch later.
Eventual consistency → Replicas converge after communication returns.
Conflict resolution → You need a resolution plan: last-write-wins, merge, keep multiple versions, or domain-specific reconciliation.
User experience → The system stays up, but different users may see different answers temporarily.
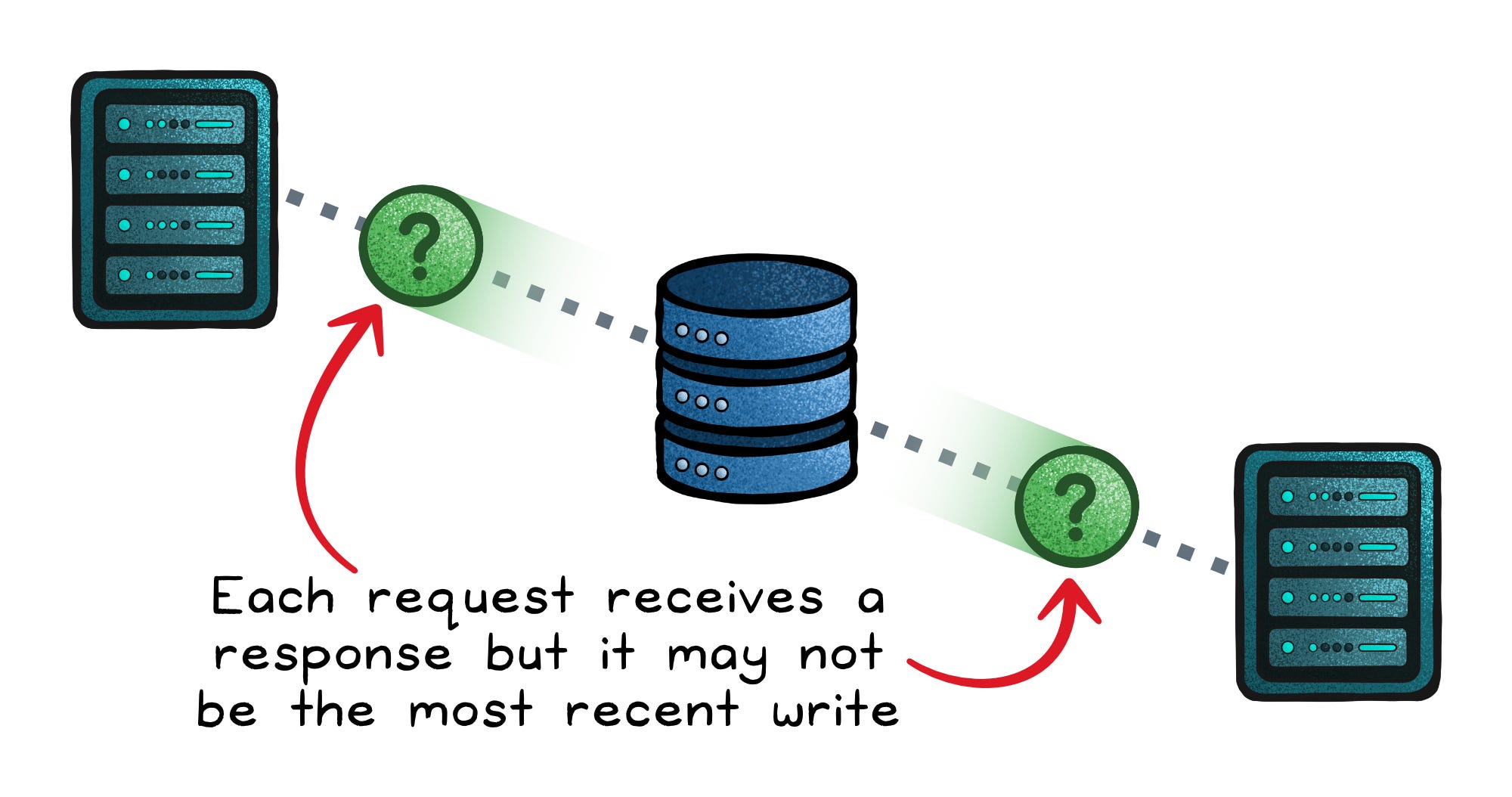
Each side believes it has the latest state. When the network reconnects, the system detects divergent updates; for example, two users modifying the same record on different sides.
Now reconciliation begins.
The database applies a conflict strategy such as last-write-wins. The service stayed available, but some data required conflict resolution.
Neither outcome is a bug. Both are deliberate design decisions baked into the system you chose.
Common mistakes that cause outages
Most confusion around CAP doesn’t come from the theorem itself.
It comes from how we simplify it.
Here are the mistakes that cause the most architectural regret.
Treating CAP as a permanent label → A system is not “CP” or “AP” as a fixed identity. During normal operation, well-designed systems provide both consistency and availability because the network is healthy.
Assuming partition tolerance is optional → You cannot avoid partitions by trusting your infrastructure. You can reduce their frequency with better networking, tighter time synchronization, or private backbone links, but you cannot eliminate its possibility entirely.
Confusing CAP consistency with ACID consistency → These are different guarantees. ACID consistency means a transaction leaves the database in a valid state according to defined rules. CAP consistency means every read returns the most recent write across nodes.
Forgetting to design recovery logic → Choosing availability during a partition is only half the decision. “Eventually consistent” requires a reconciliation strategy. You must define how conflicts resolve.
A decision checklist you can actually use
Start by asking one question: what hurts your product more, returning incorrect data, or returning no data at all?
Returning incorrect data hurts more → Choose CP.
Common use cases: payments, balances, inventory counts, permissions, leader election
Returning no data at all hurts more → Choose AP.
Common use cases: feeds, analytics views, caches, activity timelines, search indexes
Most real systems don’t pick one globally; they pick per component.
A common pattern is to have a small CP core for writes that must be correct (orders, balances, permissions), and AP layers that serve and cache data quickly across regions.
The core enforces truth; the edge keeps the system fast.
The worst outcome is not choosing consciously. Systems that ignore CAP don’t escape its constraints; they just encounter them as surprises.
Wrapping up
Every distributed system has already answered the CAP question, either deliberately or by default.
The database you picked, the replication strategy you configured, the consistency level you left unchanged: all of it adds up to a position on the spectrum.
Understanding CAP doesn’t give you new options. It tells you which option you’re already on, and whether it’s the right one.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, clear, and visual system design breakdowns straight to your inbox:
Good reminder that CAP isn’t “pick two forever.”
Designing systems is really about choosing the failure mode that hurts your product the least.