
CDC Clearly Explained
(6 Minutes) | How it Works, When to Use it (and When Not to), The Trade-Offs, and Why Teams Adopt CDC


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Try Oracle AI Database for Free
Presented by Oracle

Oracle 26ai brings AI directly into the Oracle Database, eliminating the need to move data across systems. It adds built-in vector search, automates tuning & indexing, and supports documents, JSON duality, graph, and more.
Try it completely free with up to 2 CPUs, 2GB of RAM, and 12GB of storage to build AI‑driven applications seamlessly alongside your data. Simple install via a Docker image.
Change Data Capture (CDC): How to Keep Your Data in Sync in Real Time
Your analytics dashboard looks wrong. Your microservice data doesn’t match the source.
The culprit isn’t your database; it’s your sync.
Batch jobs are slow, brittle, and always a step behind.
Change Data Capture (CDC) solves that by streaming only what changed, when it changed.
The Problem
Batch pipelines worked when data volumes were small and latency expectations were measured in hours.
Today, products depend on instant feedback loops: personalized feeds, live dashboards, fraud detection, and collaborative editing.
When your data only refreshes overnight, those experiences fall behind.
And as data grows, batch jobs become heavier: they re-scan entire tables, strain databases during load windows, and deliver snapshots already outdated by the next run.
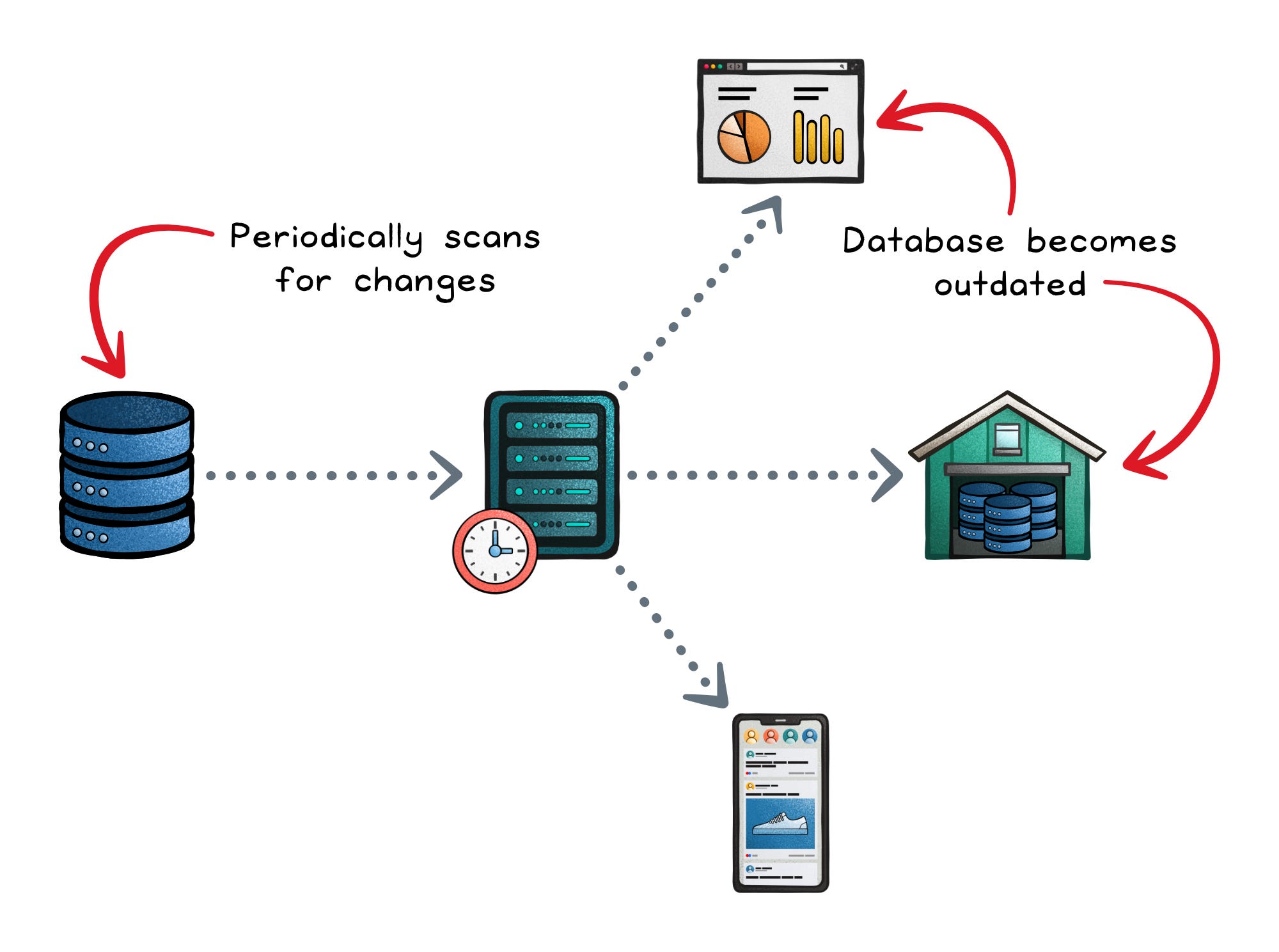
What you need instead are incremental, low-latency updates that don’t overload your source systems.
That’s what Change Data Capture (CDC) provides: capturing inserts, updates, and deletes as they happen, and streaming them downstream in real time.
What CDC is (and How it Works)
Change Data Capture (CDC) is a design pattern that tracks and streams every change made to a dataset (insert, update, or delete) so other systems can react in near real time.
Instead of reprocessing an entire table, CDC captures only what changed and when, then delivers that delta downstream as an event.
How it Works
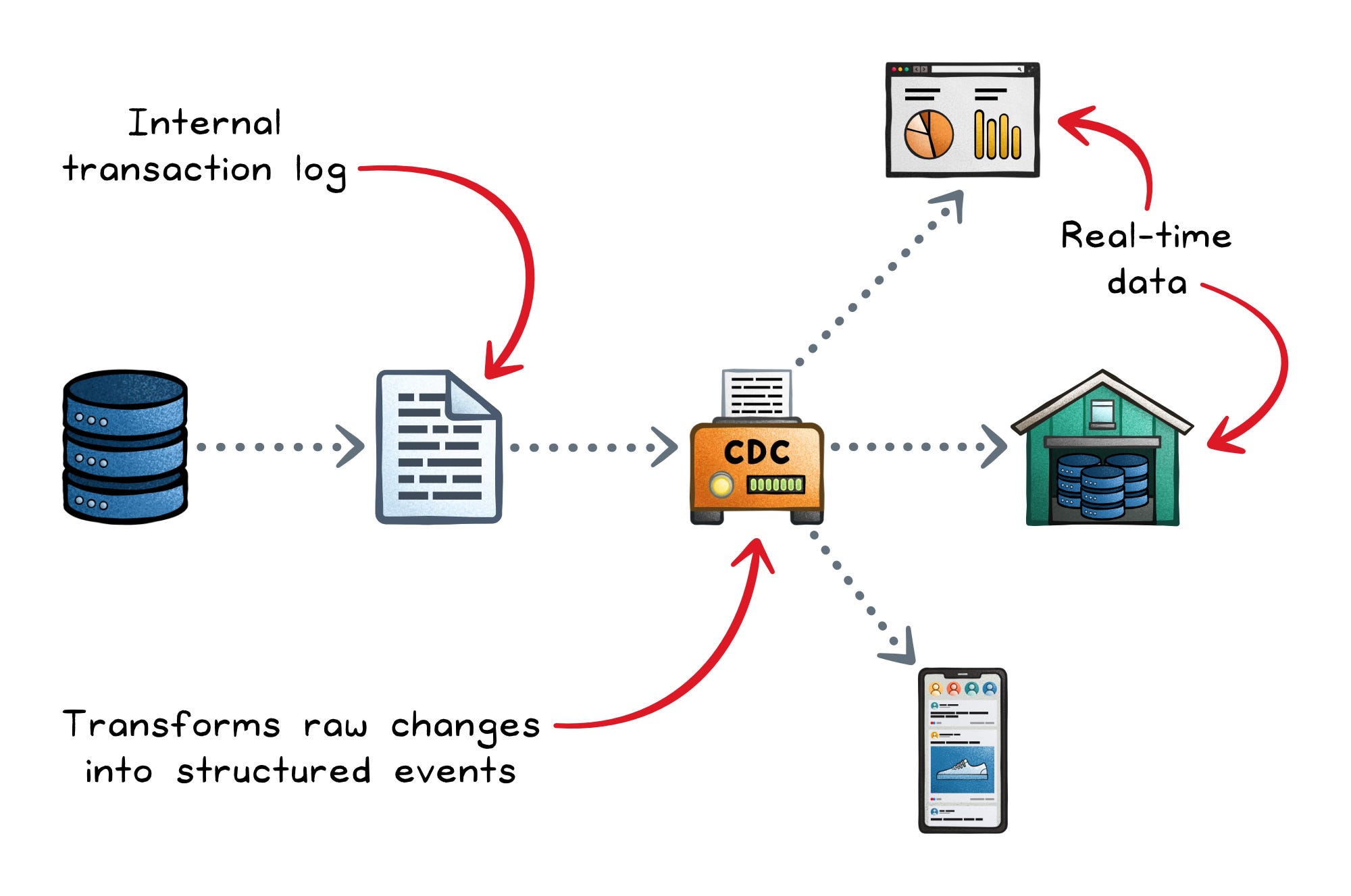
Every database already records its own history internally; it must, to ensure durability and recovery.
CDC taps into that same information.
When a row is added, updated, or deleted, the database logs those operations in its transaction log.
CDC systems read those logs, transform the raw changes into structured events, and push them to a delivery mechanism (like Kafka, Kinesis, or Pub/Sub) where other systems can consume them.
Capture Methods
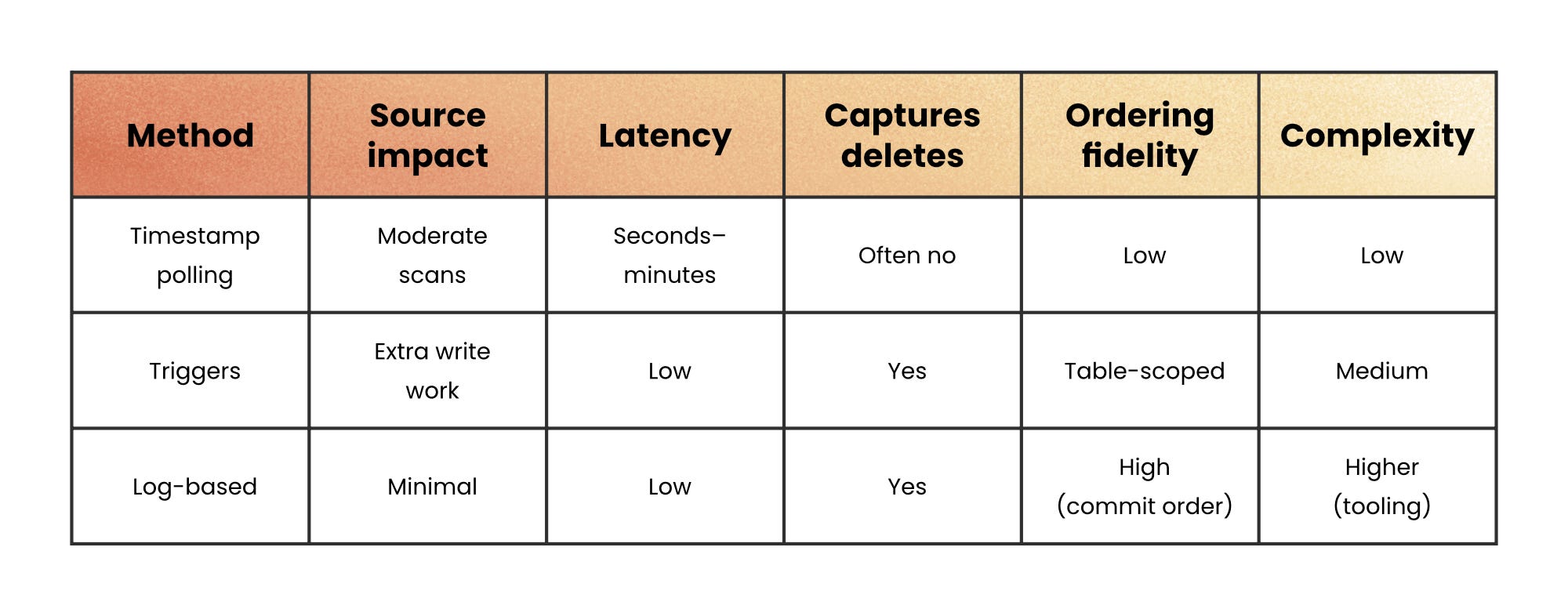
Different systems detect changes in different ways, each with its own trade-offs:
Timestamp polling → The simplest form. Periodically query rows with a last_modified column newer than the last checkpoint. Easy to implement but misses hard deletes and adds latency between polls.
Database triggers → Functions that fire automatically on INSERT, UPDATE, or DELETE, writing change details into a separate table. Reliable and immediate, but can add overhead to write-heavy systems and complicate schema management.
Log-based capture → The modern standard. Instead of modifying the application layer, it tails the database’s transaction log to extract every committed change in order. It’s low-latency, minimally invasive, and preserves the exact write order; ideal for replication and streaming.
Why Teams Adopt CDC
When every change in your database becomes an event, new possibilities open up: real-time analytics, instant personalization, faster decisions, and simpler integrations.
That’s the practical power of CDC.
The Advantages
Real-time sync → Changes are reflected within seconds, enabling live dashboards, personalization, and fraud detection. Because changes ship as they occur, not in scheduled batches.
Efficiency → Update only what changed; avoid table scans and bulky reloads that hurt performance and cost.
Consistency → Stream updates in commit order so downstream states match the source with minimal drift.
Decoupling → Publish and subscribe to data changes; microservices read from the stream instead of relying on direct calls. This keeps services loosely coupled and more resilient.
Trade-Offs and Common Gotchas
Change Data Capture gives you fresher, cleaner data; but it’s not free.
You trade simplicity for precision, and you take on new moving parts that need care and monitoring.
Understanding those trade-offs early helps you design CDC pipelines that stay reliable as they scale.
More moving parts → You need to add capture agents, message streams, offset tracking, retries, and backfill mechanisms. To make the system resilient, you’ll need idempotent consumers (so replays don’t corrupt state) and strong observability for lag, offsets, and dead-letter queues.
Schema evolution risk → When the source schema changes, the CDC stream must evolve with it. Adding a new column is simple; renaming or dropping one can break every downstream consumer. To stay safe, roll out changes in backward-compatible phases.
Security & access → Reading a database’s transaction log or replication stream requires privileged access. If the CDC pipeline isn’t secured, those logs can reveal sensitive data like emails or credentials.
Not an audit trail by default → CDC shows the fact of change but not the business context. If you need a full historical audit or compliance record, you’ll need an additional event store or append-only log.
When CDC is the Right Tool
Use CDC when your data volumes are large, but the portion that changes daily is small, and when fresh data makes a real difference.
Real-time data needs → Ideal for use cases that depend on real-time accuracy, such as live dashboards, personalized recommendations, fraud detection, or inventory updates. Even a few minutes of lag can distort analytics, surface incorrect stock levels, or block timely user responses.
Continuous integration → Replace brittle batch windows with a continuous stream of data flowing into warehouses, caches, or indexes. This enables near real-time analytics and search updates without impacting the performance of transactional databases.
Microservices data propagation → Use CDC to share data between service-owned databases without adding synchronous dependencies.
Migrations and disaster recovery → Load existing data once, then mirror ongoing changes until cutover or failover.
When Not to Use CDC
CDC isn’t the answer for every integration.
If your data or business constraints don’t demand real-time sync, simpler and cheaper methods may serve better.
Append-only feeds → If the source already emits new records (like log files, telemetry data, or event streams), you don’t need CDC. Consuming the existing stream directly is simpler and avoids unnecessary replication overhead.
Small datasets or tolerant SLAs → When data volumes are modest, or hourly or daily latency is acceptable, batch loading is often easier to maintain.
Strict historical or auditing requirements → CDC captures the fact of change, not the full historical context. If you need to reconstruct every intermediate state or explain why a change occurred, you’ll need a dedicated versioned or event-sourced store.
Recap
Change Data Capture turns databases into living data streams, moving information the moment it changes instead of waiting for the next batch window.
It keeps systems consistent, enables real-time analytics, and simplifies how services share state. But like any architectural shift, it comes with complexity: more moving parts, stricter contracts, and a higher bar for reliability.
Start small. Capture what truly benefits from real-time data, prove the value, and expand gradually.
The goal isn’t to stream everything, it’s to stream what matters.
When used deliberately, CDC becomes one of the most powerful patterns for keeping modern systems fast, consistent, and in sync.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: