
Circuit Breakers: How to Stop Small Failures from Spreading
(4 Minutes) | What they are, what triggers a trip, why they help so much, observability, and when to use them (and when not to)


Write Software: Private, Persistent, Share with a Link
Presented by exe.dev
Exe.dev gives you instant VMs over SSH. Spin up a full VM in seconds over SSH with built-in HTTPS exposure, persistent storage, and zero cloud configuration. No networking setup, no rebuilding environments, no YAML. Optimized for side projects, internal tools, and AI agents. Start a new sandbox, systemd and all, in a second.
Circuit Breakers: How to Stop Small Failures from Spreading
Retries make your system more resilient. Until they make it worse.
When a dependency is genuinely down, retrying doesn’t help.
That is how a small outage turns into a bigger one: threads pile up, retries multiply, queues grow, and healthy parts of the system start failing just because they are waiting on something unhealthy.
A circuit breaker exists to stop that spread.
It fails fast on purpose, because a quick “no” is often safer than a slow collapse.
What a circuit breaker actually is
A circuit breaker is a proxy that sits between your code and a dependency like an API, database, or downstream service.
It monitors every call for failures, timeouts, and slow responses. When things look bad enough, it stops forwarding requests entirely and starts failing fast instead of letting threads pile up waiting for a service that won’t recover on its own.
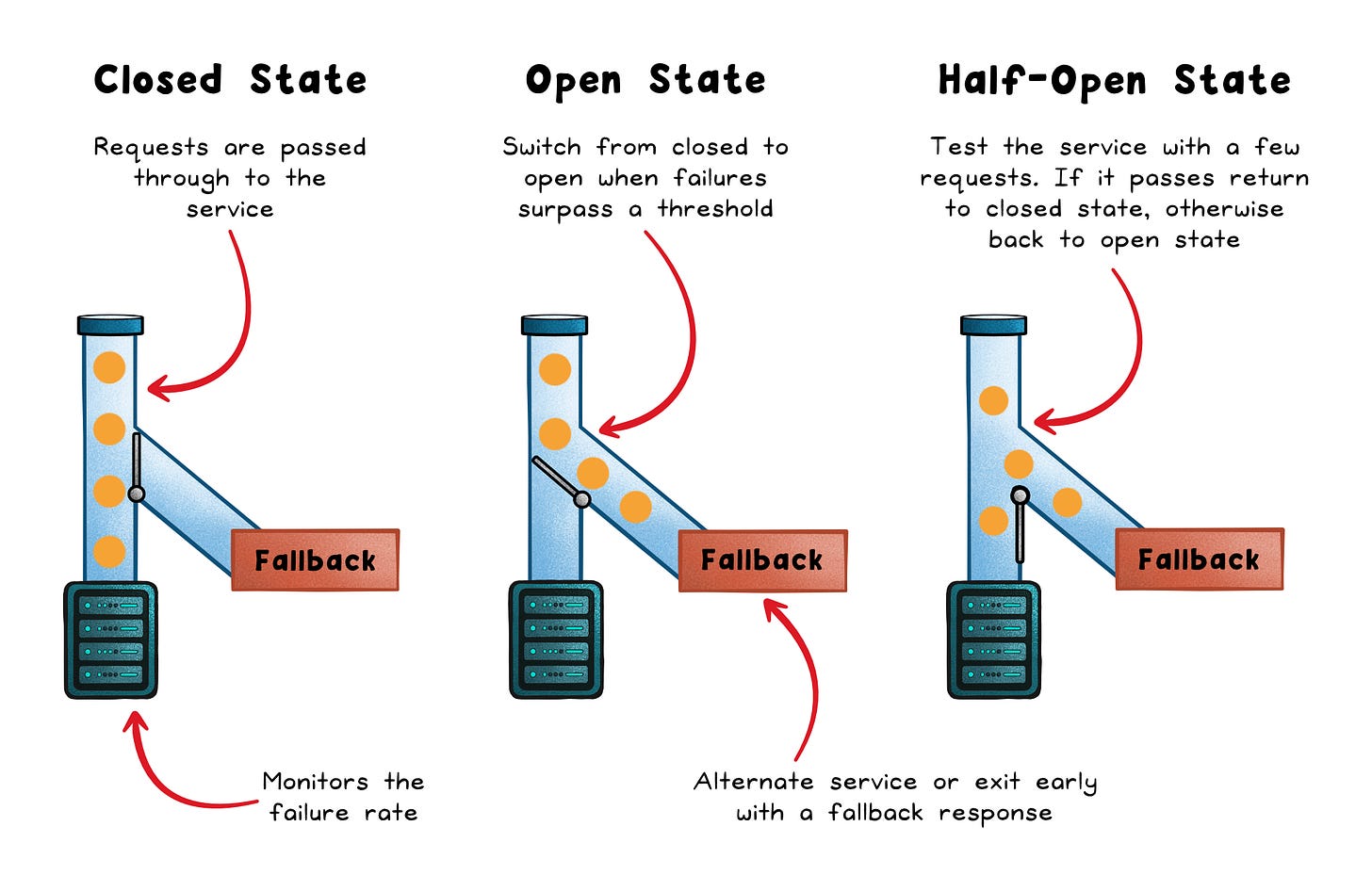
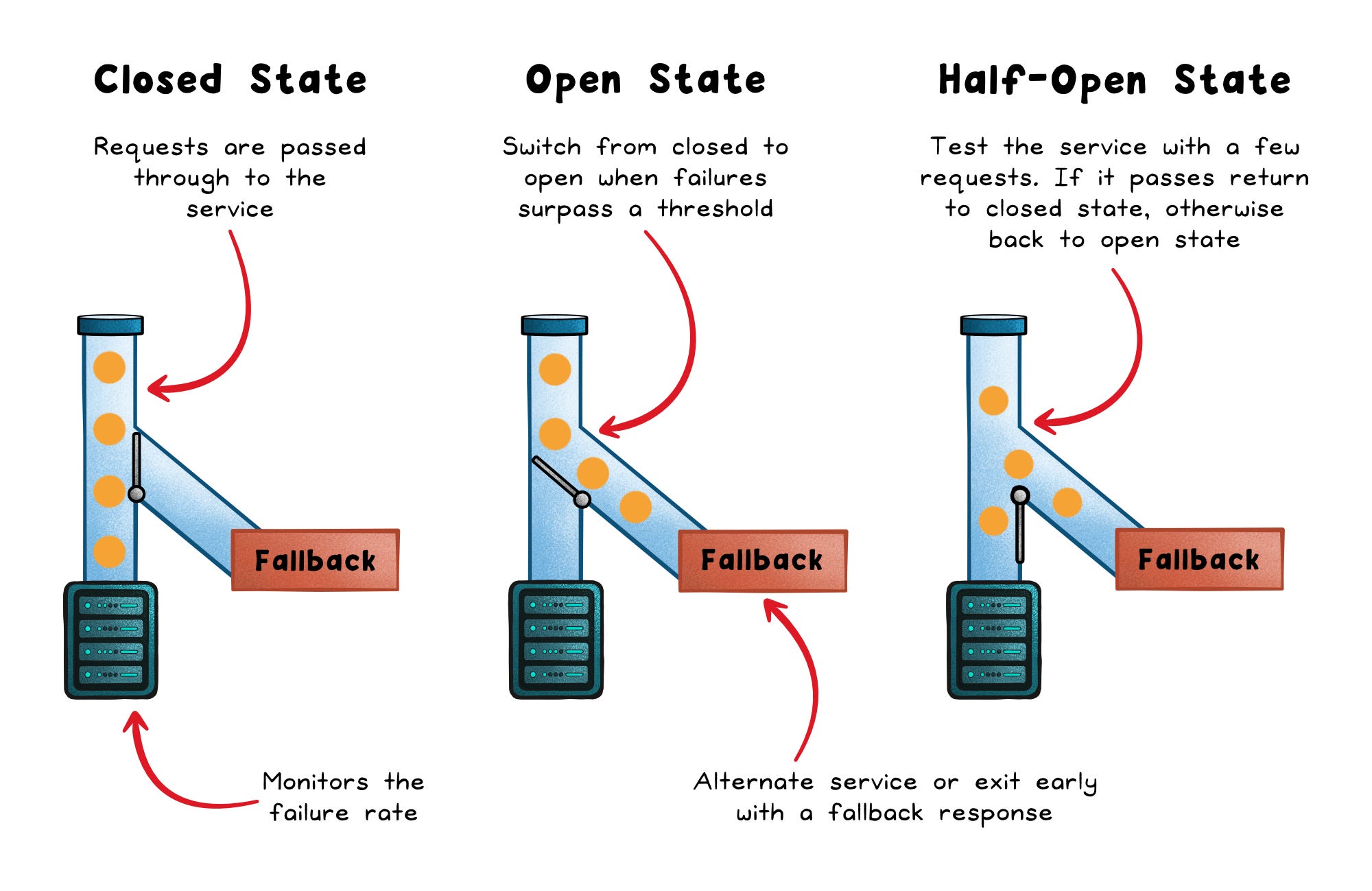
Most health-based circuit breakers use three states:
Closed → Requests flow normally, and the breaker tracks failures, timeouts, or slow calls.
Open → Requests fail immediately instead of touching the unhealthy dependency.
Half-open → A small number of trial calls test whether the dependency has recovered.
What triggers a trip
Not all failures look the same, so not all circuit breakers trip for the same reason.
Some open after a run of consecutive failures. That works well for low-traffic calls where even a few failures are meaningful.
Some open on failure rate. Instead of asking “Did five calls fail in a row?” they ask “Is too large a share of recent traffic failing?” That works better for high-volume services because it filters out noise.
Some open on slow-call rate. This is important because a dependency does not need to be fully down to be dangerous. A slow database can burn your connection pool long before it starts returning errors.
And some proxy or mesh-level breakers focus on capacity rather than health. They trip on too many active requests, pending requests, retries, or connections. These don’t ask whether the dependency is broken. They ask whether the system can safely take more load.
Here is the key difference:
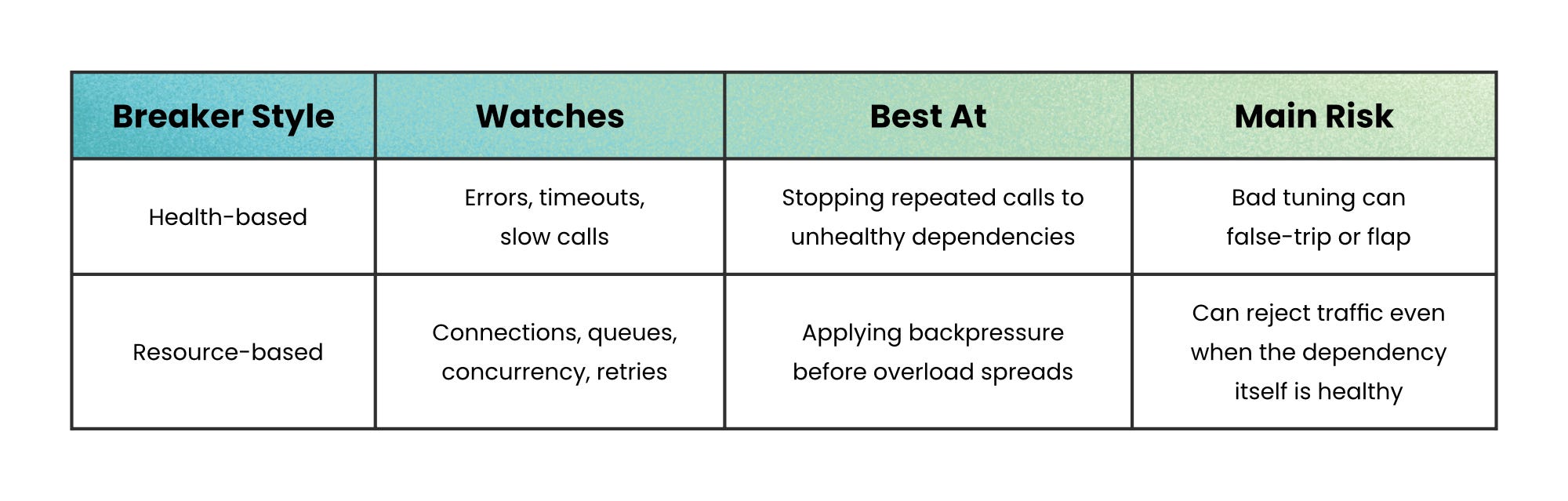
That is why teams often use both. One protects against unhealthy behavior. The other protects against unhealthy volume.
Why circuit breakers help so much
The biggest benefit is not speed. It is containment.
When a dependency is clearly struggling, the breaker stops your service from wasting resources on calls that are likely to fail anyway.
That gives the rest of your system room to breathe.
It also makes failure easier to shape.
Fail fast → Users get a quick error or fallback instead of waiting through long timeouts.
Protect capacity → Threads, sockets, and pools stay available for work that still has a chance to succeed.
Reduce blast radius → One broken service is less likely to drag healthy services down with it.
Support graceful degradation → You can return cached data, defaults, or partial results instead of total failure.
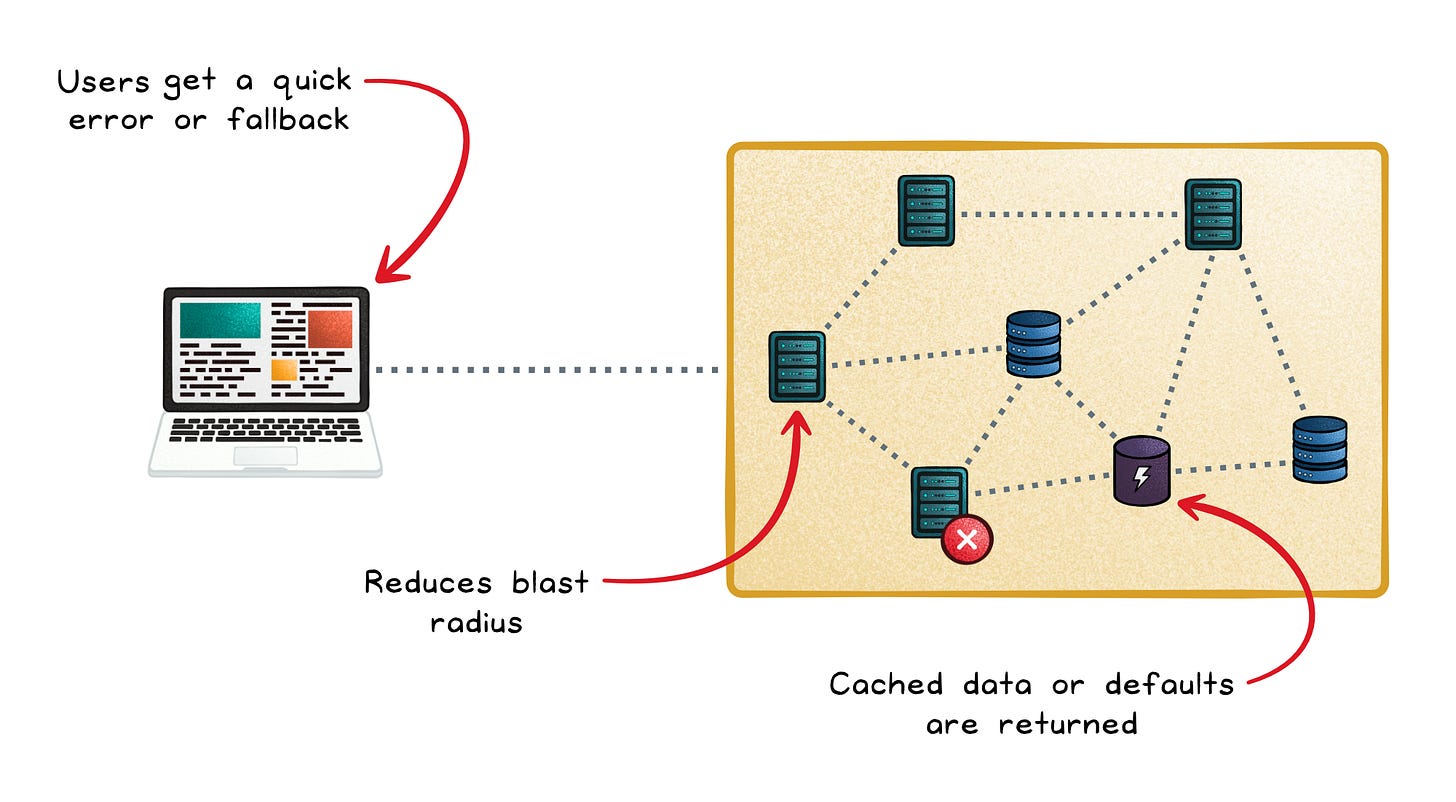
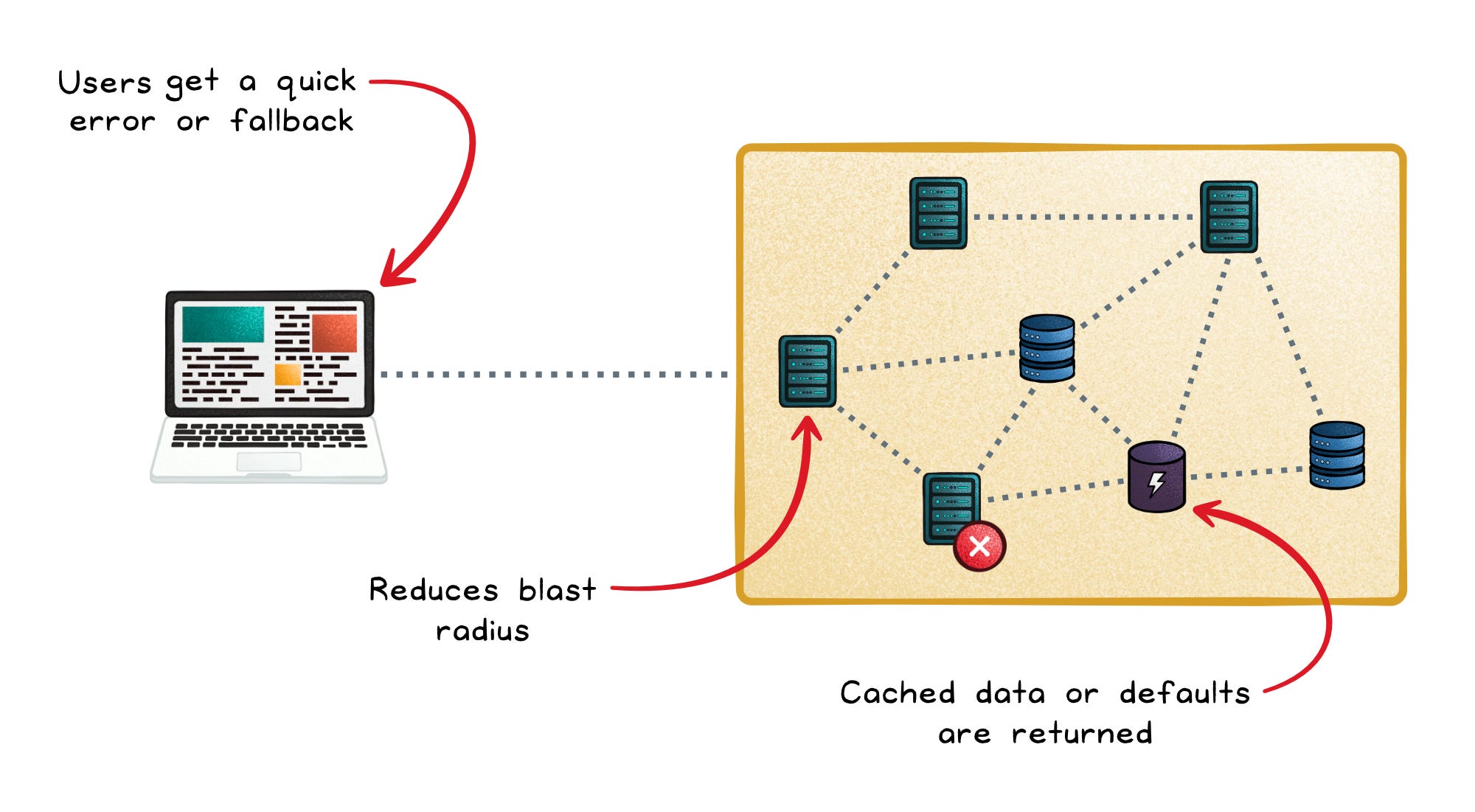
This is why circuit breakers often pair well with fallbacks. If a recommendation service is down, your app can still show popular items. If a profile service is slow, you can still render most of the page.
The user sees degraded behavior, not a frozen system.
Observability is non-negotiable
A circuit breaker without monitoring is a black box that silently shapes your availability.
At minimum, track:
State transitions (Closed → Open → Half-Open)
Failure rate and slow-call rate gauges
Not-permitted calls, requests the breaker rejected without forwarding
Overflow counters if you’re using Envoy (e.g.
upstream_cx_overflow)
Alert on state transitions when they exceed a rate threshold, and alert on sustained not-permitted calls correlated with user-impact SLIs (service level indicators).
One-off blips don’t warrant pages; sustained opens that burn your error budget do.
When not to lean on a circuit breaker
Circuit breakers are powerful, but they are not a substitute for basic resilience hygiene.
Do not use circuit breakers as a bandage for missing timeouts. If your calls can hang indefinitely, a circuit breaker will only react after damage is already done. Always set clear, enforced timeouts first, because they limit how long resources stay blocked.
Separate retries from circuit breakers. They solve different failure patterns. Retries help with brief, transient failures. Circuit breakers help when failure lasts long enough that retrying becomes harmful.
Avoid adding breakers everywhere. Not every dependency needs one. Each breaker introduces configuration, monitoring, and edge cases. Use them where failure is costly, not where it is merely inconvenient.
And be careful with shared breakers. If one breaker covers several independent shards or providers, failures in one can block traffic to the healthy ones too.
Wrapping up
Cascading failure doesn’t start with a catastrophic event.
It starts with one slow service and nothing to stop the pressure from spreading.
A circuit breaker is that stop.
That is the real win: a smaller blast radius when something goes wrong. And in distributed systems, survival often depends less on avoiding failure and more on containing it.
👋 If you liked this post → Like + Restack + Share to help others learn system design.