
Connection Pooling Clearly Explained
(6 Minutes) | The Problem, How Pooling Works, Benefits vs Tradeoffs, and The Sweet Spot


Introducing Developer Tier for Aiven Postgres & MySQL Services
Presented by Aiven
Building side projects, POCs, or agents? Aiven’s new $5 fully managed PostgreSQL Developer tier is an ideal choice. A fully managed database you can spin up instantly. No pricing overkill. No ops tax. Just a real database to practice or test on (without the setup work or fees).
Connection Pooling Clearly Explained
Imagine rebuilding a bridge every time someone needs to cross it.
The first few people make it through, but soon, traffic piles up, and the builders can’t keep up. It’s inefficient, exhausting, and entirely avoidable.
That’s what many apps do when they open a brand-new database connection for every request. Each one starts from scratch (handshakes, authentication, encryption) before any real work happens.
Connection pooling changes the story.
Instead of rebuilding bridges, you keep a few sturdy ones open and let everyone share them. The result is smoother traffic, lower latency, and a backend that stays steady under load.
The Problem
Every connection to a database is a tiny ceremony.
First comes the TCP handshake. Then TLS negotiation. Then authentication. Only after all that can your query even begin.
That setup might take milliseconds, but at scale, it impacts latency and burns CPU cycles you never see. Multiply that across thousands of short-lived requests, and your backend spends more time connecting than doing work.
Without pooling, each request starts cold:
Extra latency → Every new connection repeats the full setup cost.
Server strain → The database must authenticate, allocate buffers, and set up session state for each connection, eating into CPU and memory.
Connection churn → Opening and closing sockets rapidly causes kernel overhead, port exhaustion, and ephemeral TCP delays.
Throughput collapse → At peak load, clients race to open more connections than the server can handle, triggering timeouts and throttling.
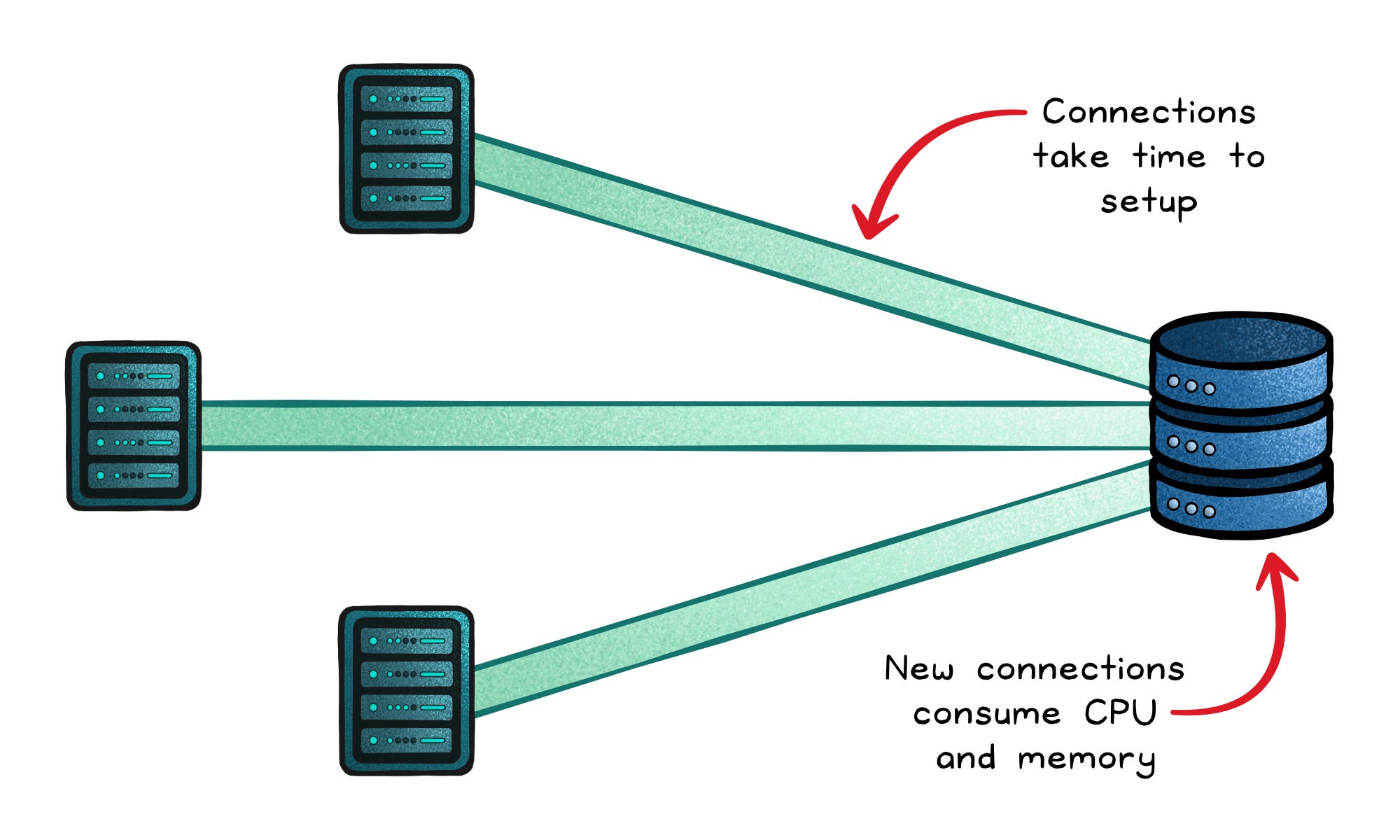
In high-concurrency environments (web APIs, microservices, serverless functions) this inefficiency compounds. You’re not just slowing down individual requests; you’re draining the very capacity your system depends on.
Pooling breaks that pattern by reusing a small number of ready, authenticated connections so the system can spend less time connecting and more time computing.
How Pooling Works
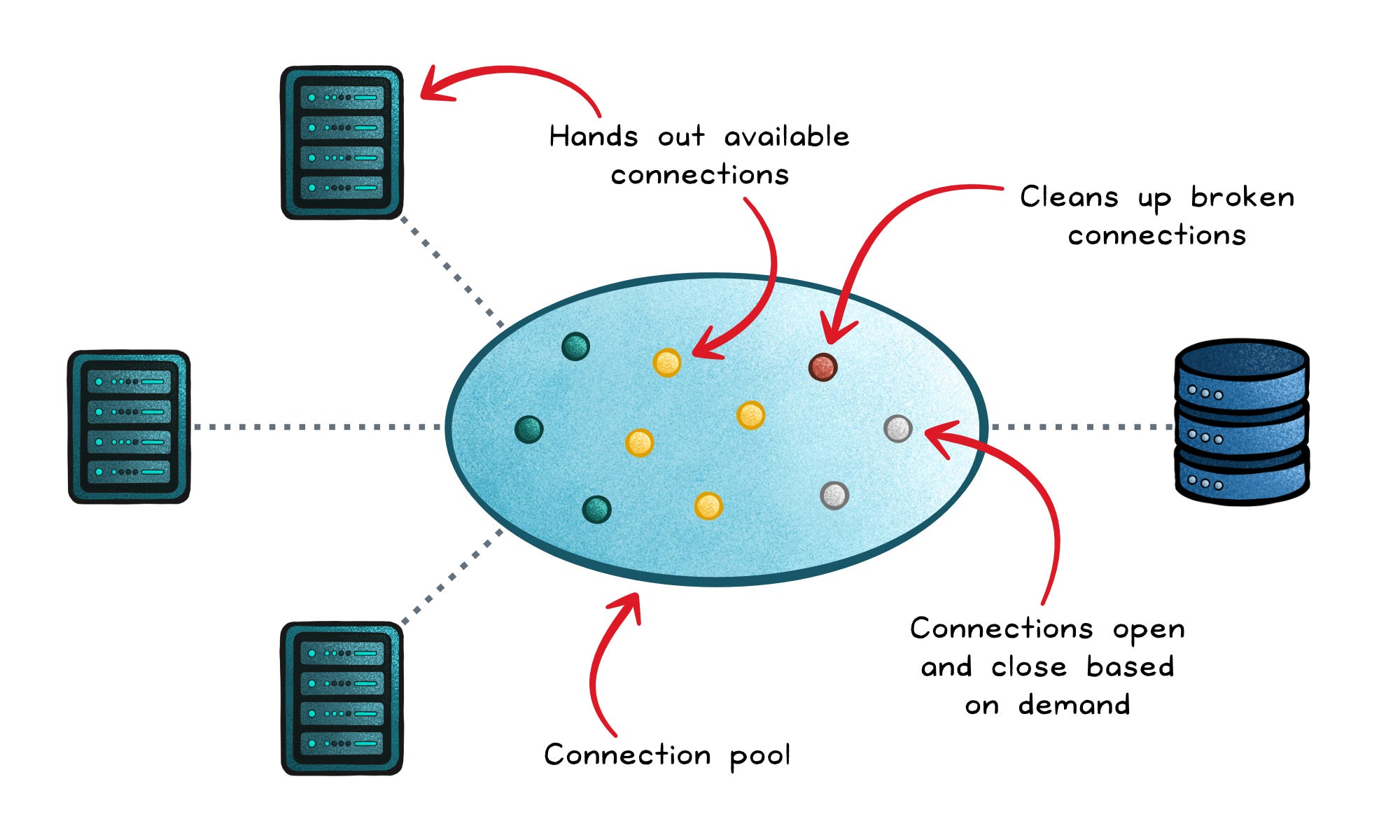
A connection pool manages how database connections are created, shared, and reused across requests.
Instead of opening and closing sockets on every query, the pool keeps a managed set of open, ready-to-use connections. When your application needs one, it borrows from the pool; when it’s done, it returns it for reuse.
Under the hood, the pool manages a few key behaviors:
Creation → When the app starts or demand increases, the pool opens new connections up to its configured maximum. These are fully established (TCP, TLS, authentication complete) and ready to serve queries.
Checkout → Each request asks the pool for a connection. If one is idle, it’s handed out instantly. If all are busy, the request waits in a queue until a connection is free or until a timeout expires.
Release → When the work is done, the connection isn’t destroyed. It’s reset to a clean state (rolling back open transactions, clearing temporary settings) and then returned to the pool for the next request.
Validation → Before reuse, the pool checks that the connection is still alive, often with a lightweight “ping” or
SELECT 1. Broken or idle-too-long connections are closed and replaced.Cleanup → A background task prunes long-idle connections to prevent waste and keep the pool healthy.
The exact behavior depends on the pool’s configuration:
Min and max size → Define how many connections stay open at idle and how far the pool can grow under load.
Idle timeout → Determines how long unused connections remain open before being closed to save resources.
Wait timeout → Sets how long a request waits for a free connection before failing. Shorter waits prevent request pileups when the pool is exhausted.
Validation strategy → Decides when to test connections (on borrow, on release, or periodically) to balance performance and reliability.
For example, a pool might keep 5 idle connections ready, grow up to 20 under load, and prune extras after 30 seconds of inactivity. A request that finds all 20 busy waits up to 2 seconds, then fails fast rather than hanging indefinitely.
Benefits vs Tradeoffs
Connection pooling looks like a free performance boost; and mostly, it is.
But every optimization comes with a cost. Pooling improves performance not by doing more, but by doing less; reusing work instead of repeating it. The real challenge lies in tuning it to your system’s concurrency and traffic patterns.
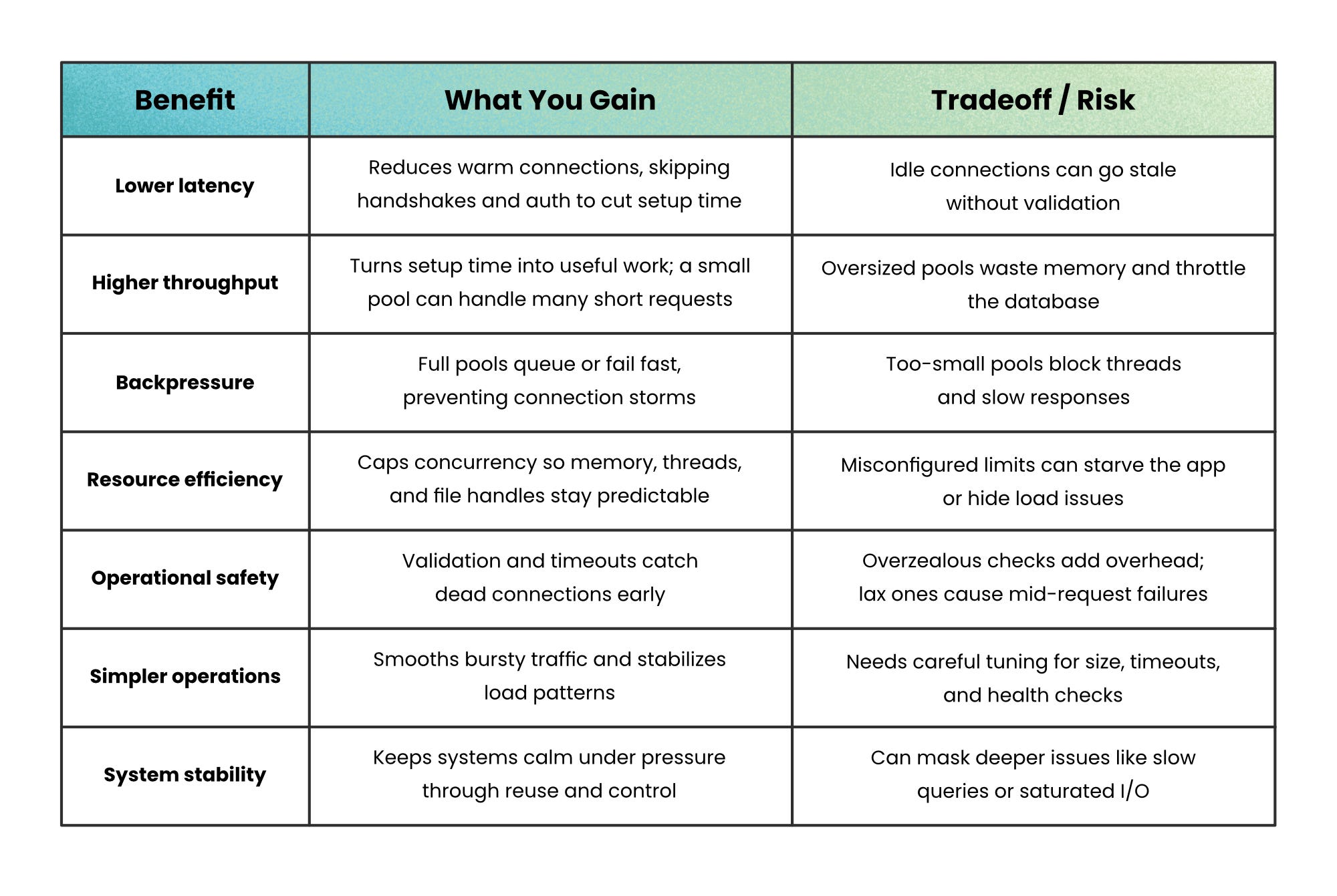
What You Gain
Lower latency → Each query skips the handshake, authentication, and TLS setup. You reuse a warm connection instead of building one from scratch, shaving milliseconds off every request.
Higher throughput → A fixed pool can easily handle hundreds or thousands of quick operations per second. Since it reuses connections instead of recreating them, the system’s effort goes into running queries, not re-establishing them.
Backpressure under load → When the pool fills, new requests wait or fail fast instead of spawning new sockets. That controlled queue prevents connection storms and protects your database from overload.
Resource efficiency → By capping how many connections run at once, you keep memory, file handles, and backend threads predictable, which keeps your system steady even during traffic spikes.
Operational safety → Idle timeouts and validation checks catch broken connections early, so small faults become quick recoveries instead of hidden outages.
What You Trade Up
Pooling doesn’t eliminate all disadvantages; it shifts it from per-request setup to ongoing coordination.
Those same controls that make your system stable can also become choke points if misconfigured.
Idle cost → Every open connection holds server resources (memory, session state). Oversized pools can quietly throttle your database’s capacity.
Blocking risk → If the pool is too small, threads wait on connections instead of serving users. Without careful timeout tuning, this can cascade into app-wide slowdowns.
Complex tuning → Finding the right pool size, idle timeout, and validation frequency isn’t one-size-fits-all. You balance latency, CPU, and concurrency based on workload.
False confidence → A healthy pool can mask deeper performance issues. Queries that max out CPU or I/O still create bottlenecks; the pool just helps you hit that limit more gracefully.
Stale connections → Long-idle connections can drop silently because of network or load balancer timeouts. Without proper validation, the next request fails halfway through.
The Sweet Spot
A well-tuned pool sits between chaos and waste.
Too large, and you overload the database. Too small, and you throttle yourself.
Healthy pools are dynamic: they scale up under load, scale down when quiet, and validate connections just often enough to stay fresh without wasting cycles.
The goal isn’t to open as many connections as possible; it’s to maintain just enough to keep your system steady at peak efficiency.
Wrapping Up
Connection pooling doesn’t add new features or fancy abstractions; it simply makes the work you already do more efficient.
It’s a quiet optimization that saves you from the hidden tax of constant handshakes and wasted connections.
When tuned well, it’s the difference between a system that panics under load and one that stays calm, predictable, and fast.
Pooling reminds us that performance isn’t always about doing faster work; sometimes it’s reusing the work you’ve already done.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox:
Loved this breakdown, very well written and easy to read. Was a great refresh for me and made me think deeper about connection pooling, LIFO/FIFO Under the hood and semaphore locks used for release of connections