
Consistent Hashing Clearly Explained
(6 Minutes) | How It Works, Why It Matters, and When Not to Use It


Accelerate Agents to Production With Amazon Bedrock AgentCore
Presented by AWS
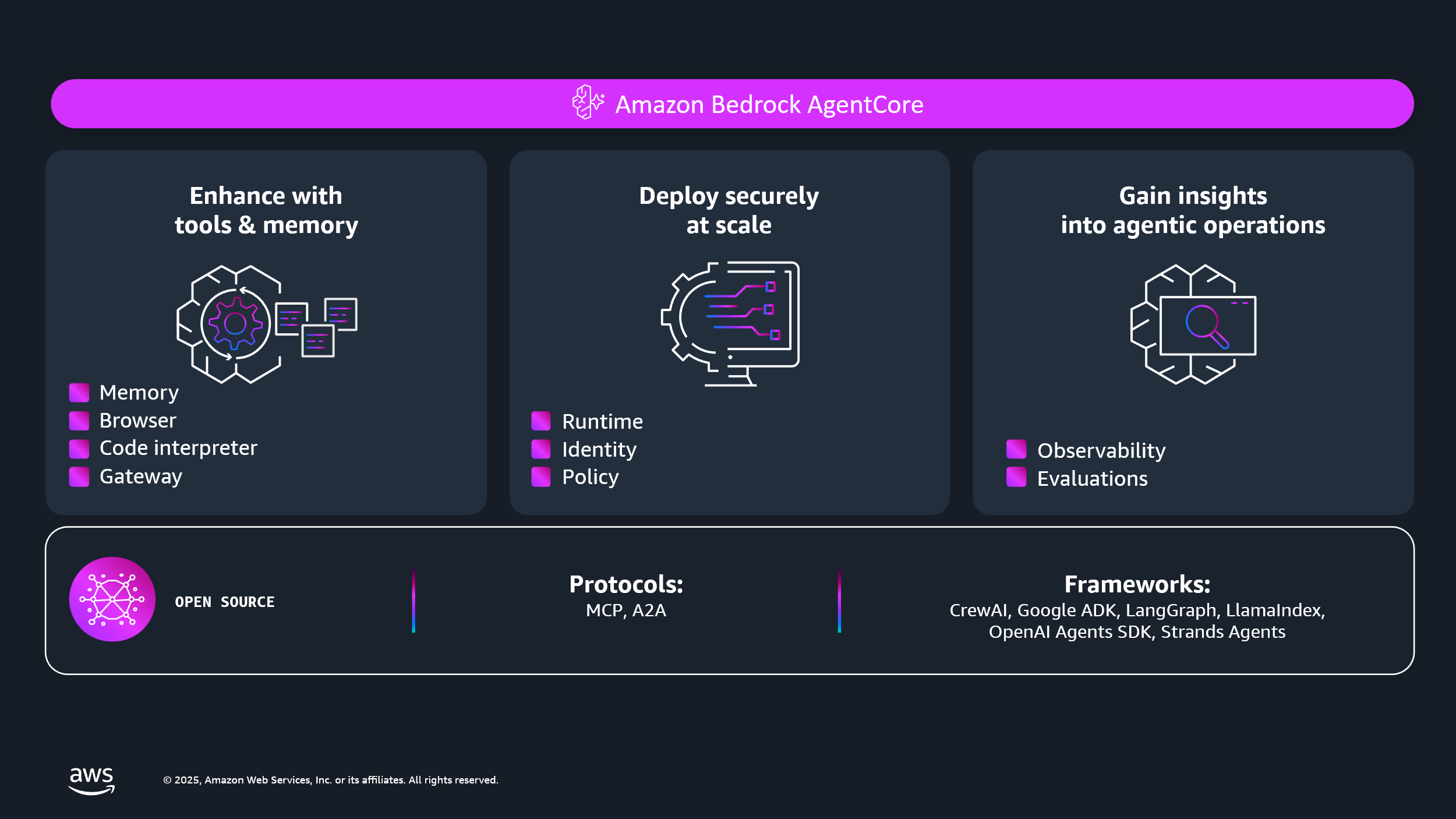
Accelerate agents to production with composable services that work with any framework, any model. AgentCore is an agentic platform for building and running production-grade AI agents, securely at scale, with no infrastructure to manage. Now with complete control over agent actions through policies, and continuous evaluations of real-world agent behavior to boost quality.
Consistent Hashing: The Key to Stable Scaling in Distributed Systems
You finally scale your cache cluster, then watch your hit rate nosedive.
Adding one new server shouldn’t break everything, yet your monitoring lights up: latency spikes, databases struggle, and the cache you trusted suddenly forgets everything it knew.
The culprit is usually hiding in plain sight: a simple hash(key) % N sharding strategy.
It works fine when your cluster is static, but the moment you add or remove a node, every key gets rehashed and shuffled across the fleet. What should be a routine scaling step turns into a full cache reset.
Consistent hashing fixes that.
It keeps most keys exactly where they were, even as servers come and go; so your system scales smoothly instead of starting over every time it grows.
Why Naive Hashing Breaks When You Scale
At the heart of most caching and sharding strategies is a single line of code:
shard = hash(key) % N
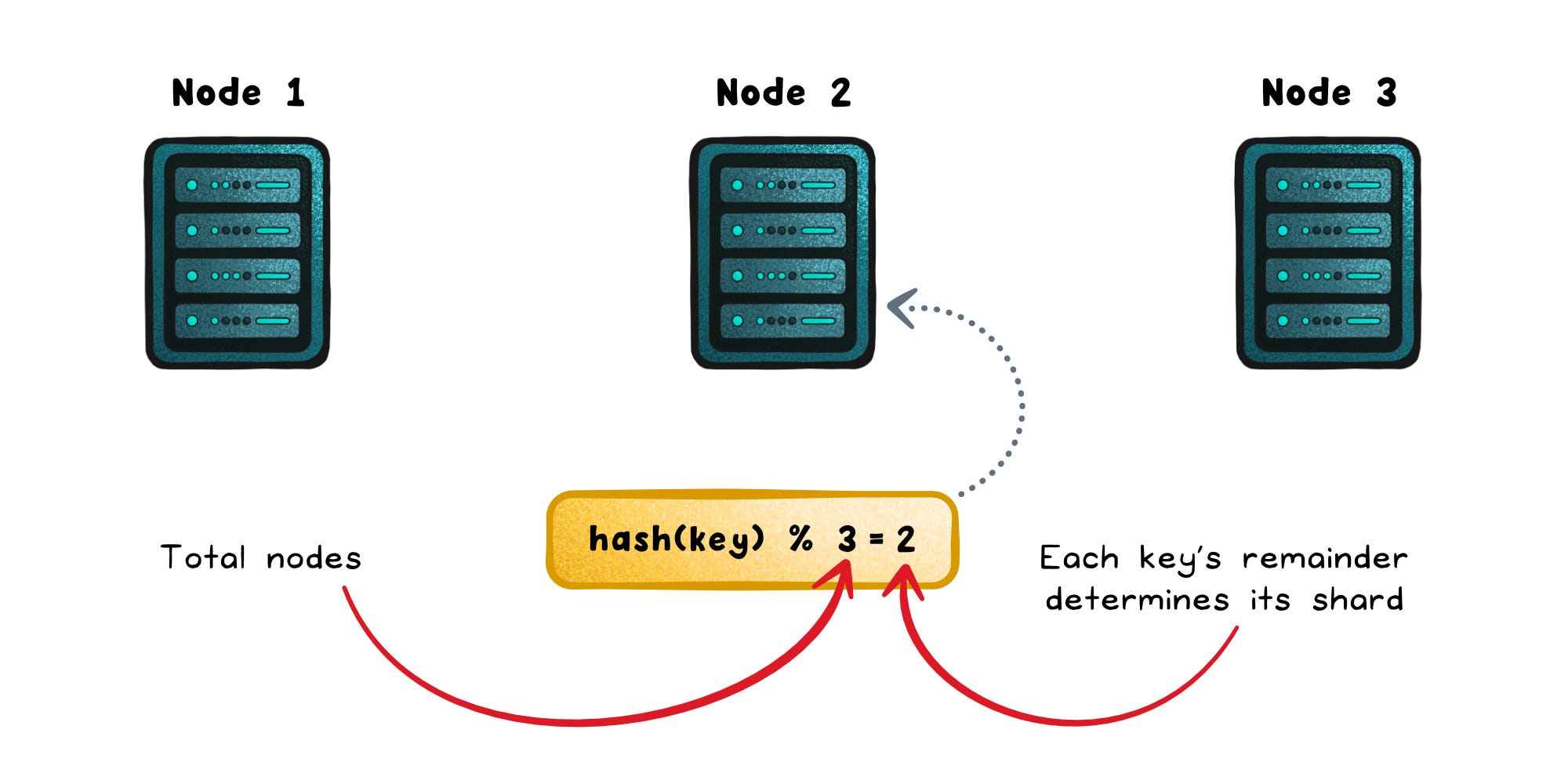
It’s simple, fast, and evenly spreads data; until the cluster changes.
Add or remove a node, and that one line suddenly remaps almost every key in the system.
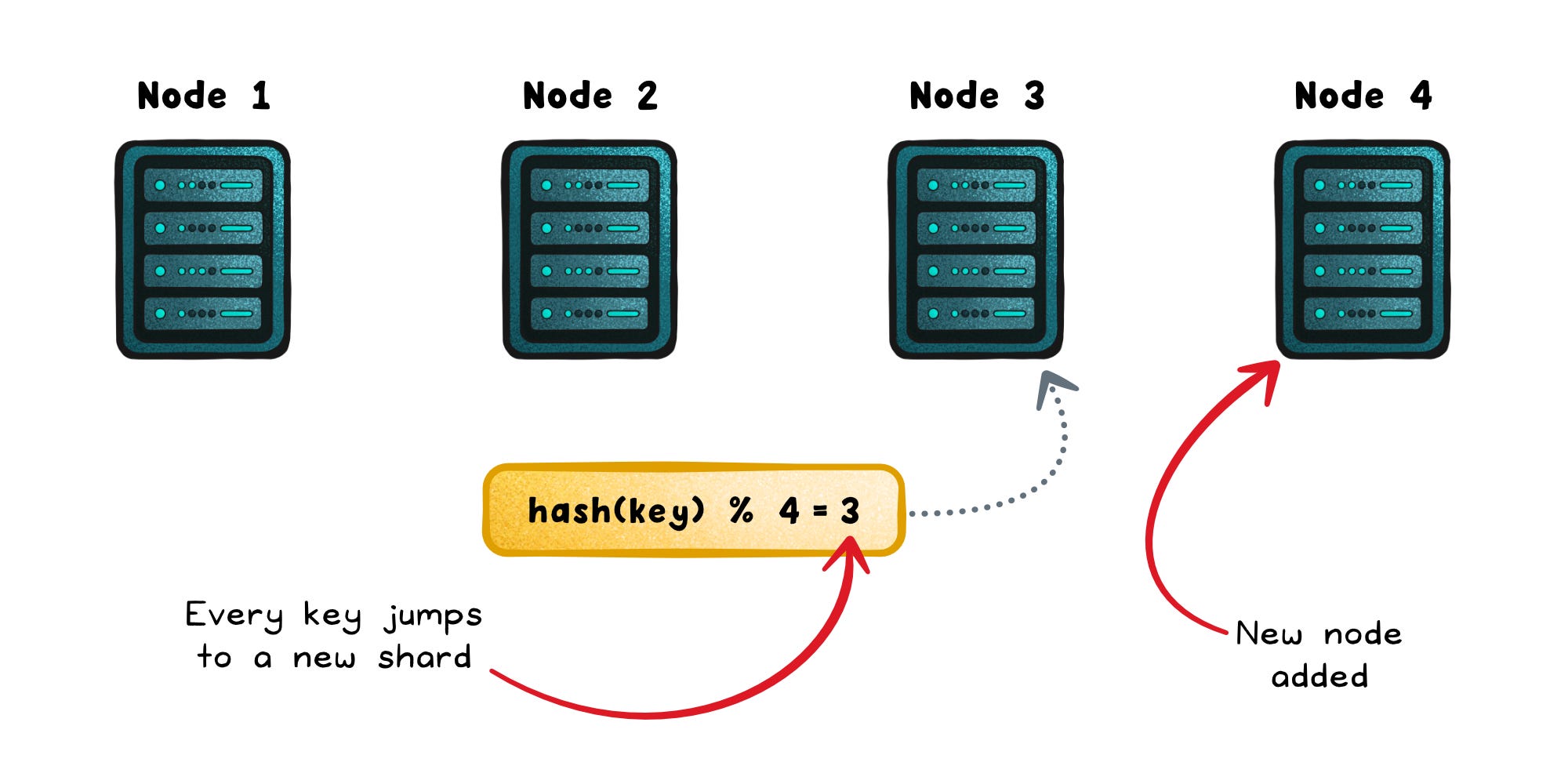
Distributed systems are designed to change: nodes fail, scale, and get replaced all the time. But this formula couples your data layout directly to the number of nodes (N). The moment N shifts, the entire mapping shifts with it.
That’s why caches go cold, databases get flooded, and load balancers lose affinity after what should have been a harmless scaling event.
This causes a few predictable problems:
Cache clusters lose their memory → When keys jump to new servers, all previous cache entries become invalid. Every request that once hit instantly now misses, forcing a round trip to the database until the cache repopulates.
Storage systems move too much data → Each node must reassign or copy large chunks of data to new destinations to maintain balance. This migration floods the network and keeps disks busy doing housekeeping instead of serving users.
Load balancers lose affinity → Requests that were consistently routed to the same node suddenly scatter across the cluster. That breaks session locality, increases cache misses even further, and causes temporary spikes in latency.
In short, naive hashing doesn’t fail because it’s wrong; it fails because it assumes nothing ever changes.
How Consistent Hashing Works
Consistent hashing starts with a simple idea: instead of mapping keys to servers, you map both keys and servers into the same space.
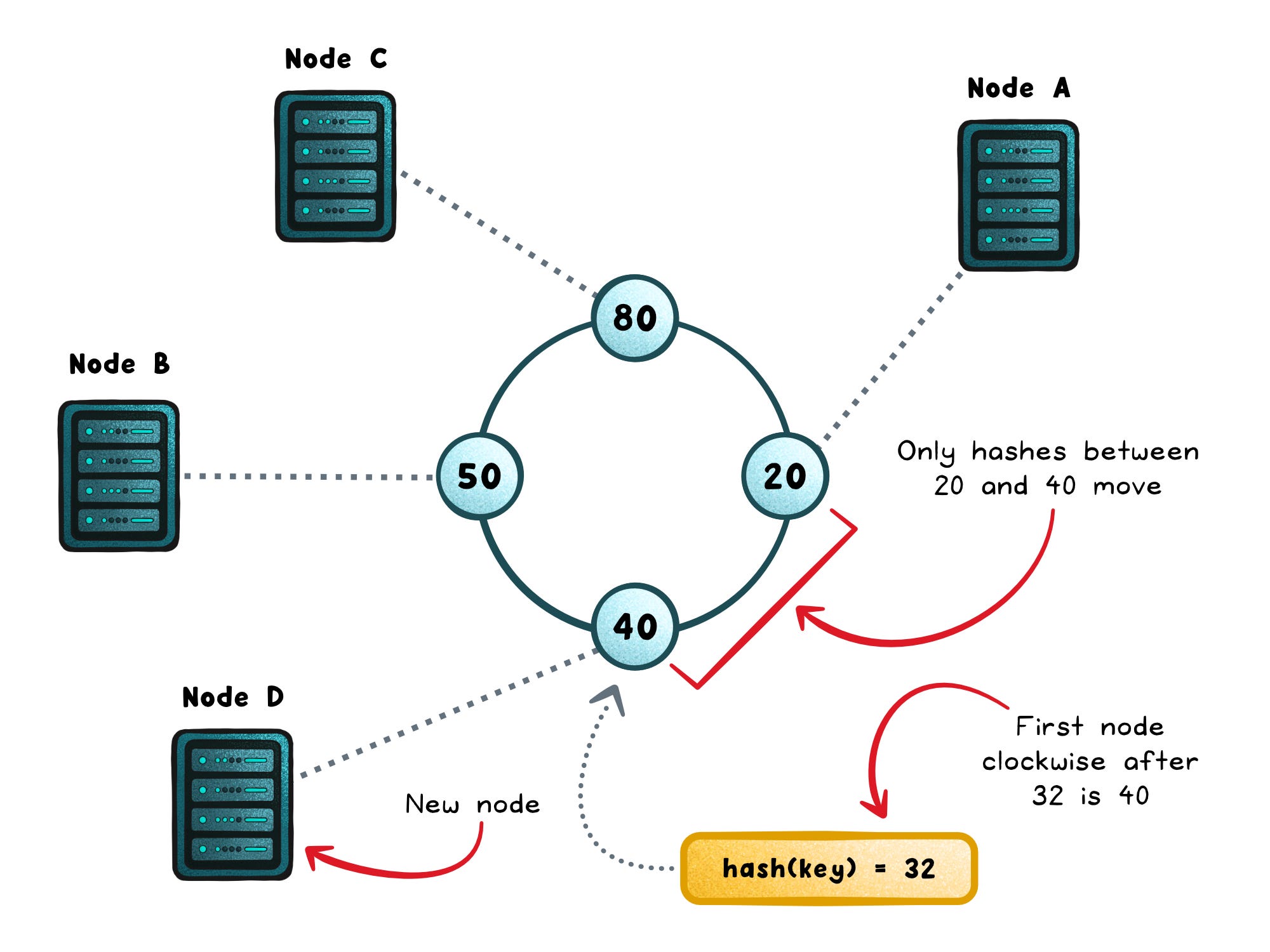
Imagine a ring where every point represents a hash value from 0 to the maximum possible output of your hash function. Each server is assigned one or more points on this ring, often called virtual nodes or vnodes. Each key is also hashed to a point on the same ring. To find where a key belongs, you move clockwise until you hit the first server. That’s the node responsible for that key.
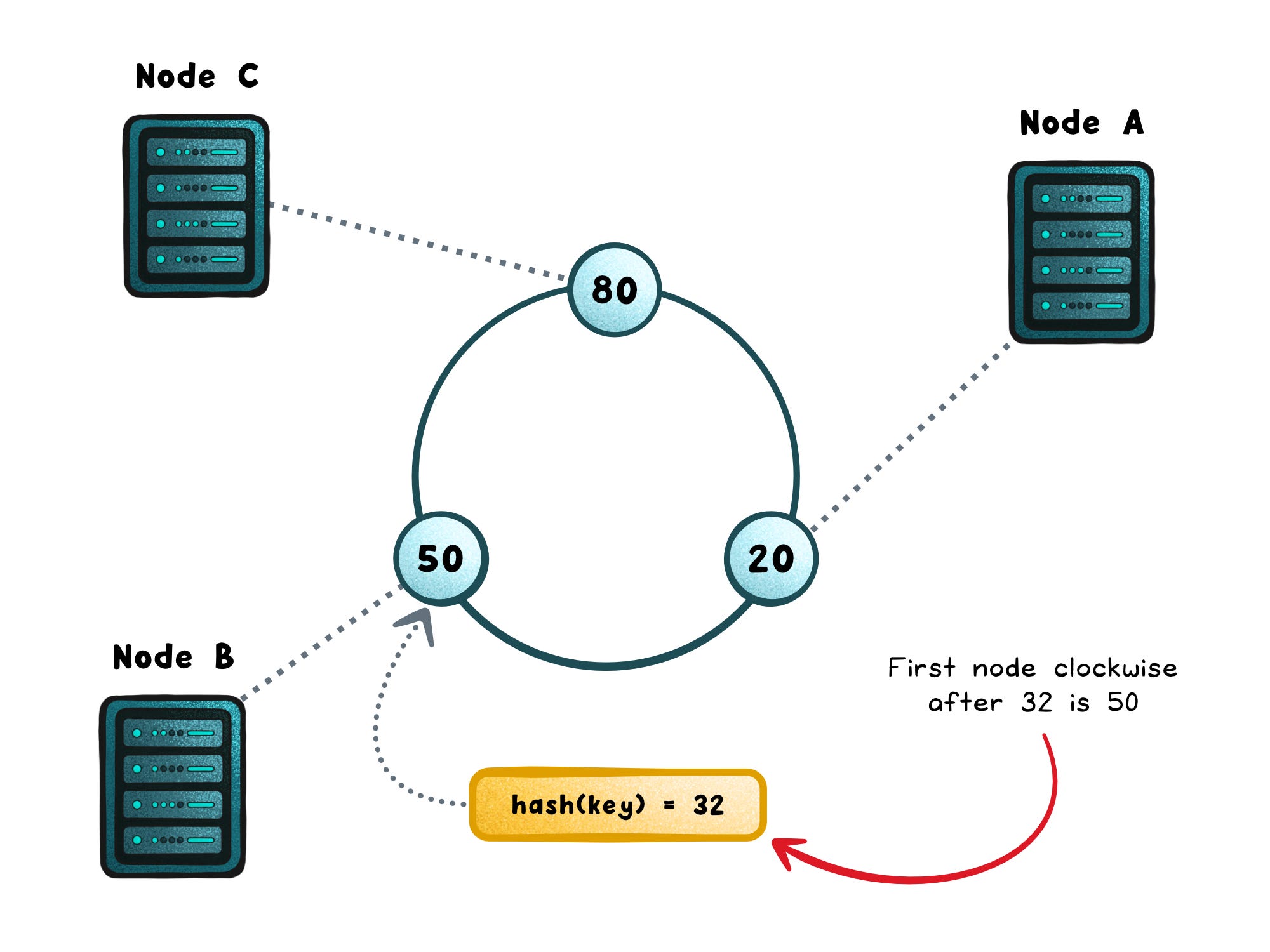
This tiny change (using a circle instead of a list) makes a massive difference.
When you add a node, only the keys that fall between its new position and the previous node need to move.
When you remove a node, the same applies in reverse. The rest of the keys stay exactly where they are.
Most implementations also use multiple virtual nodes per physical server. This spreads each server’s share of the ring more evenly and smooths out random imbalances in the hash function. If one server has twice the capacity of another, you simply give it twice as many virtual nodes.
Because consistent hashing doesn’t depend on the total number of nodes, it naturally scales up or down with minimal disruption.
In practice, when a cluster grows, only about 1/N of the keys move; so caches stay warm, rebalancing is light, and new nodes can join without chaos.
Why It Matters
You might never write a consistent hashing algorithm; but you use one almost every day.
Whenever you connect to a Redis cluster, store data in Cassandra, or route traffic through a CDN, consistent hashing is quietly at work.
These systems rely on it to keep data stable, minimize rebalancing, and prevent cascading failures when nodes change.
Even if your framework handles it for you, understanding the principle changes how you design.
You start thinking about:
Choosing the right key → What you hash decides how evenly load spreads. Narrow keys (like region or prefix) overload hash ranges, while diverse keys distribute requests evenly and keep every node busy.
Scaling strategy → Adding or removing nodes gradually prevents unnecessary churn.
Replication design → Knowing that keys are placed by proximity helps plan for failover and redundancy.
When Not to Use It
Consistent hashing is powerful, but not universal. Some problems call for different trade-offs.
When you need range queries → Consistent hashing scatters keys uniformly across the hash space. That randomness breaks ordering, which means you can’t efficiently scan “everything between A and B.” Databases that support range lookups, like MySQL or HBase, use range partitioning instead.
When traffic is heavily skewed → If a small number of keys receive most of the requests, they can overload a single node even if the hash is fair. In those cases, you need replication or a bounded-load variant that limits how hot a single node can get.
When load balancing is stateless → For web servers that don’t store session data or cache locally, there’s no need to keep the same key-to-node mapping. Round-robin or least-connections algorithms are simpler and often faster.
In short, consistent hashing shines when keeping data near its original home saves time and cost. But if your system depends on order, tolerates churn, or needs strict balancing on every request, another approach will fit better.
Wrapping Up
Consistent hashing is one of those ideas you rarely touch but constantly rely on.
It’s built into the tools you already use (Redis, Cassandra, Envoy, CDNs) and it’s the reason they scale without chaos. You don’t need to implement it, but you should understand what it guarantees and what it doesn’t.
Here’s what matters most:
It’s about stability, not balance → Consistent hashing doesn’t promise perfect distribution; it promises predictable change. When the cluster shifts, only a fraction of keys move.
Your choices still shape the outcome → The key you hash, how often you scale, and whether nodes have equal capacity all affect performance. The algorithm stays simple; real systems don’t.
Plan for churn → Adding or removing a node moves roughly 1/N of data. Knowing that helps you schedule scaling and avoid cold starts.
The best systems don’t fight change; they’re built to absorb it. Consistent hashing is how distributed systems keep caching steady while everything around them moves.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox: