
Database Indexing Clearly Explained
(4 minutes) | What indexes really do, index types, how the optimizer decides, when they help (and when they hurt), and the right mental model


Agent Memory: Building Memory-Aware Agents
Presented by Oracle

Free short course on DeepLearning. By the end, you’ll have assembled a fully stateful Memory Aware Agent that loads prior context at startup, assembles relevant context, state, tools, and outputs and improves across sessions.
How Database Indexing Really Works
Slow queries have a reflex fix: add an index.
It works often enough that teams keep doing it; until write latency creeps up, storage balloons, and the query planner starts making strange choices.
That’s the index tax. Real, measurable, and entirely predictable once you understand what an index actually costs.
The goal isn’t to index everything. It’s to index the right things, and know when to stop.
What an index really does
At the simplest level, an index maps a search key to where the row lives, much like a book index maps a chapter to page numbers.
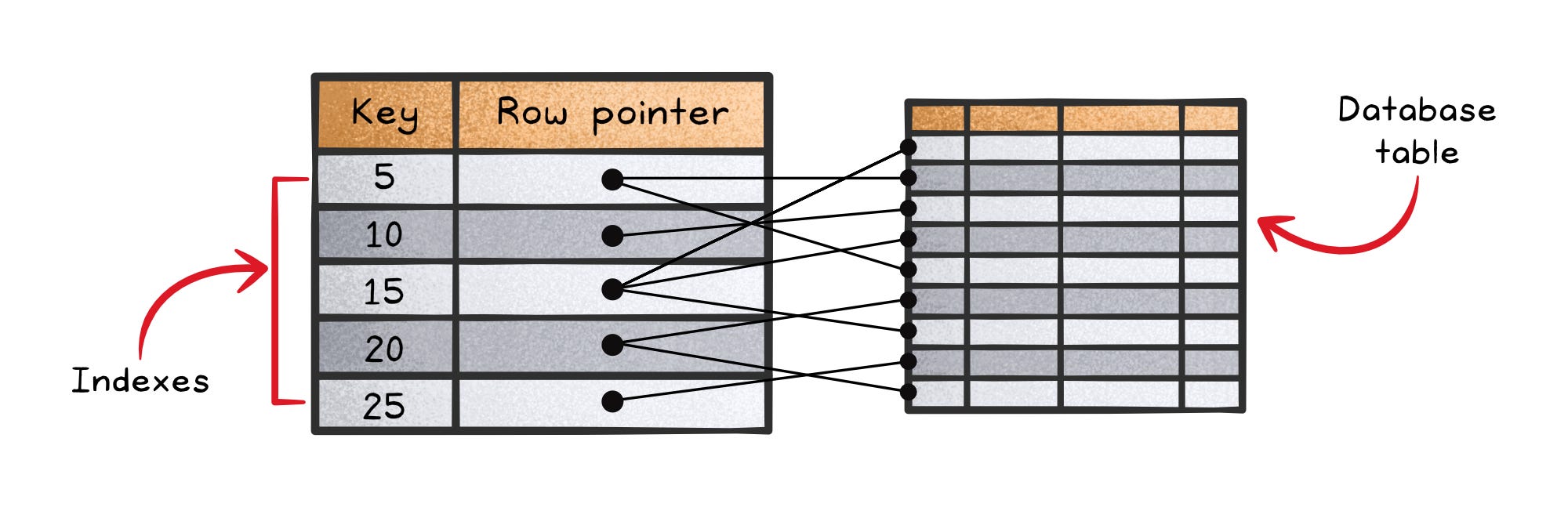
The goal is to cut down how much of the table the engine must look through to answer a query.
That helps in a few common cases:
Point lookups →
WHERE id = 42becomes a targeted search instead of a full scan.Range queries →
BETWEEN,<, and>work well when keys stay in order.Joins → An index on join keys helps the engine find matching rows faster.
Ordering → A tree index can return rows in sorted order without an extra sort step.
Uniqueness → Unique indexes help enforce “this value must appear only once.”
The catch is that every INSERT, UPDATE, and DELETE must also update the index. So every helpful index also comes with a write tax. Add too many, and your database starts carrying extra baggage on every row change.
Index types
Not all indexes work the same way. Each structure solves a different query pattern.
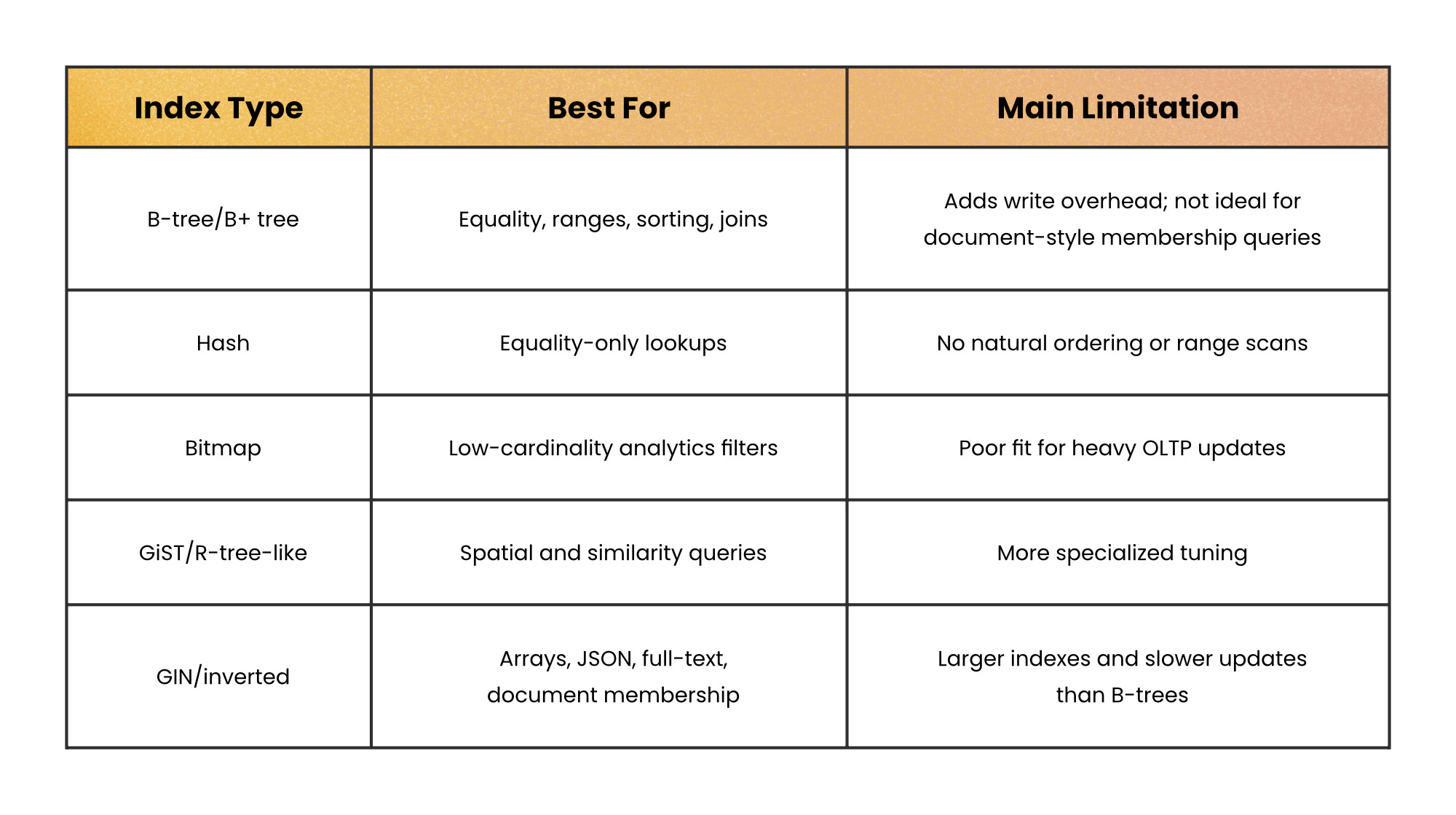
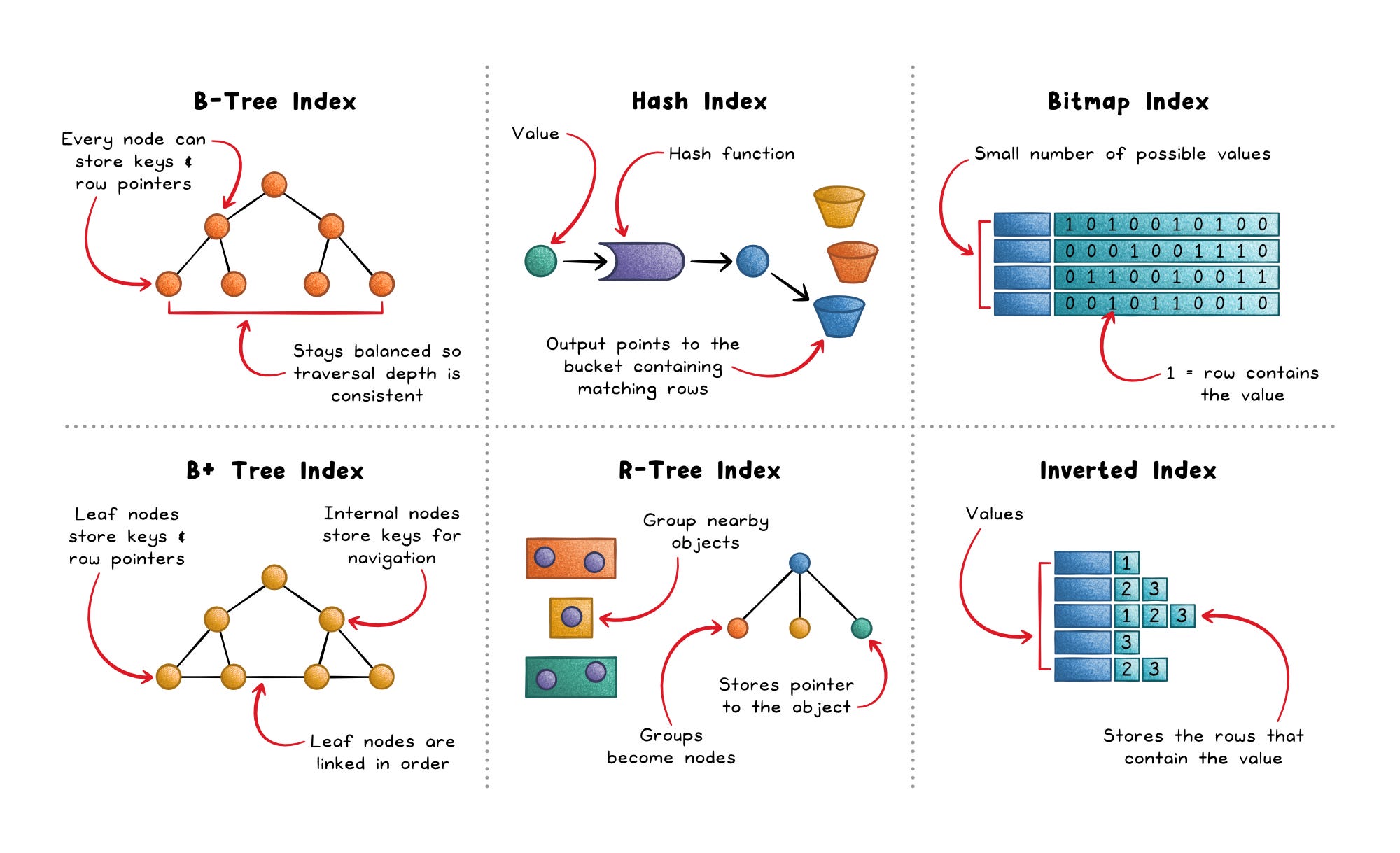
Most relational databases use B-tree style indexes by default, often implemented internally as B+ trees.
B-trees are the safe first choice for most OLTP queries:
Equality filters → Great for exact matches.
Range filters → Great for time windows and ordered values.
Ordered reads → Helpful for
ORDER BY.General-purpose use → Good default when your data is sortable and your workload is mixed.
B-trees are the workhorse, while other index families exist for more specialized conditions and data shapes.
How the optimizer decides
This is what catches most engineers: just because the index exists, doesn’t mean it’ll be used.
The optimizer decides to use an index when its cost model estimates that the index path is cheaper than reading the table directly.
That decision depends heavily on statistics: row counts, value distribution, selectivity, and sometimes histograms. If those statistics are stale, the optimizer can make a bad decision.
This is why keeping statistics fresh matters.
PostgreSQL uses ANALYZE to populate pg_statistic. MySQL manages histograms via ANALYZE TABLE. If statistics are stale, the optimizer can pick a costly plan even when a good index exists.
The optimizer assigns a cost to each candidate plan and picks the cheapest. In PostgreSQL, you can nudge this by tuning random_page_cost relative to seq_page_cost; lowering the ratio makes the planner more willing to use index scans.
When not to add an index
You shouldn’t add an index just because a column appears in a WHERE clause once. Indexes pay off when they serve a repeated access pattern better than their write and storage cost.
Avoid or remove an index when:
It is rarely used → Unused indexes still slow writes.
It duplicates another index → Same leading columns often mean overlapping value.
The predicate is not selective → If most rows match, scanning may still be cheaper.
Writes dominate the workload → More indexes means more maintenance on every change.
The query prevents index use → Wrapping a column in a function can block index use unless you build the matching expression index.
There is also a physical side to this.
Indexes can fragment, bloat, and lose page density over time, especially under heavy updates. That’s why rebuild, reorganize, or reindex operations exist across major databases. An index can be conceptually correct and still operationally unhealthy.
The right mental model
The best indexing strategy is not “index everything.”
It is “match the structure to the predicate, then verify with real plans.”
That means:
Start with the query pattern → Index for how you filter, join, and sort.
Start with B-trees → Switch only when the data shape clearly demands another family.
Keep stats fresh → The optimizer can only choose well with up-to-date statistics.
Prefer fewer, sharper indexes → Each one should earn its keep.
Re-check over time → Workloads shift, and yesterday’s useful index becomes tomorrow’s write penalty.
Indexes are best understood as a trade: you spend extra work on writes so reads can skip unnecessary work. Once you see that trade clearly, index tuning stops feeling like superstition and starts feeling like engineering.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, clear, and visual system design breakdowns straight to your inbox:
Postgres query planner taught me indexes aren't free. WITH queries and EXPLAIN ANALYZE became my debugging duo. Spring Data JPA hides this complexity—until it doesn't.
Very helpful.