
Domain-Driven Design, Broken Down
(5 minutes) | How DDD prevents your model from collapsing as systems and teams scale


Refactor with Context, Not Guesswork
Presented by Atlassian
Rovo Dev is Atlassian’s context-aware AI agent for the entire SDLC. One of the use cases where it excels is refactoring. It helps teams plan changes, generate consistent multi-file updates, and review pull requests against Jira acceptance criteria and Confluence context. Learn how Atlassian engineers used Rovo Dev and AI-driven workflows to safely refactor a large monorepo.
Breaking Down Domain-Driven Design
Early systems succeed because everyone shares the same mental model.
Late-stage systems fail because that model fractures.
Teams grow, terminology drifts, and the code becomes a poor translation of the business. At that point, speed drops even if your infrastructure is flawless.
Domain-Driven Design targets that exact moment of failure.
The real problem DDD solves
In complex products, the hardest part is not the codebase. It’s agreeing on what the business is actually doing.
Domain-Driven Design (DDD) forces the domain into the foreground.
You model the business concepts directly, so the code reads like the business operates.
That only works if you draw boundaries and protect them. Otherwise you get one giant model that tries to mean everything.
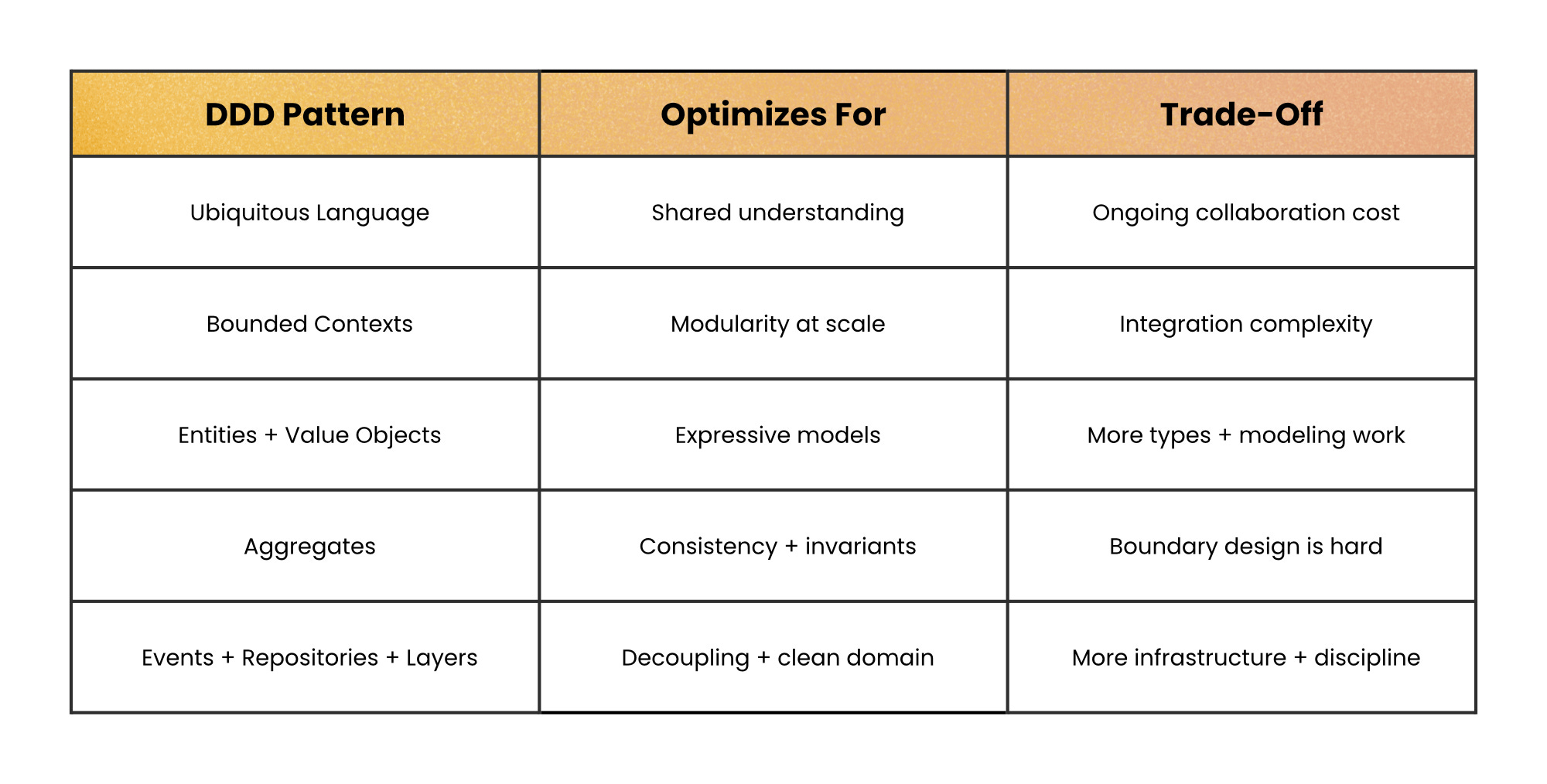
Five core patterns that make DDD work
1) Ubiquitous Language
Most teams think they share vocabulary.
They usually don’t.
In meetings, everyone nods when someone says “order,” “account,” or “encounter.” In code, those same words quietly drift into something else.
Ubiquitous language is a shared vocabulary that developers and domain experts use everywhere: meetings, tickets, docs, and code.
You stop translating “business terms” into “engineering terms.”
Pros:
Shared meaning → Reduces back-and-forth and avoids “same word, different idea.”
Readable code → New engineers learn by reading domain names, not glue code.
Better decisions → Clear terms expose missing rules and edge cases.
Cons:
Upfront effort → Workshops and alignment feel slow early.
Requires discipline → Sloppy naming breaks the whole benefit.
2) Bounded Contexts
Shared language breaks down at scale.
Not because people are careless, but because the business is not one thing.
Bounded Contexts accepts that reality.
A bounded context is a clear boundary where a particular model and language apply. Outside that boundary, the same word can legitimately mean something else.
In an e-commerce system, “Product” in Inventory can mean descriptions and pricing, while “Product” in Order Management can mean a purchasable line item.
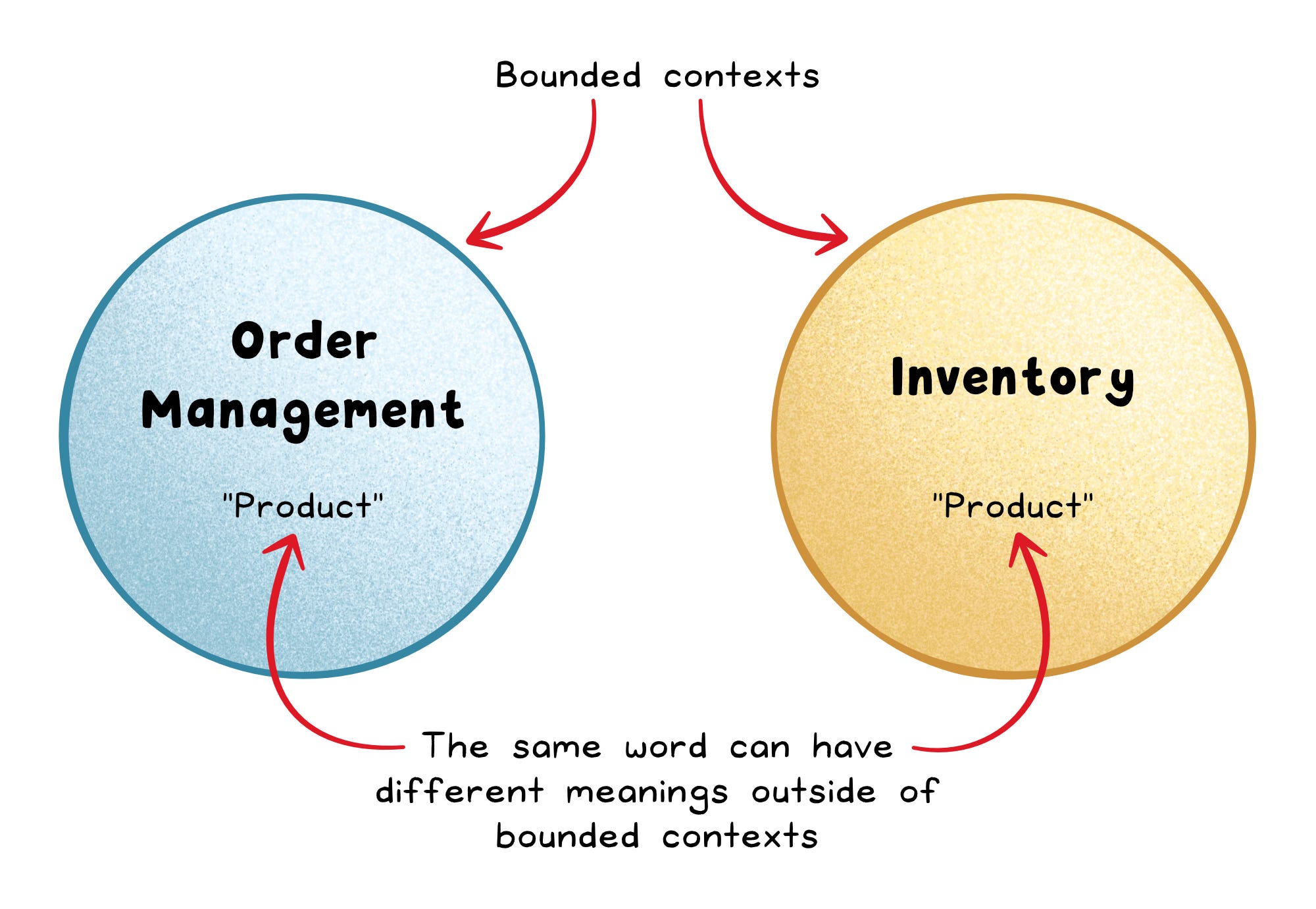
Bounded contexts prevent your system from becoming one giant argument about what a “product” really is.
Pros:
Clear boundaries → Prevents a single model from becoming a “big ball of mud.”
Team ownership → Lets teams evolve independently with fewer collisions.
Safer change → Local refactors stay local because meanings don’t leak.
Cons:
Integration work → You must design how contexts talk and what they share.
Boundary mistakes → Wrong splits create friction and duplicated logic.
3) Model identity and value (Entities + Value Objects)
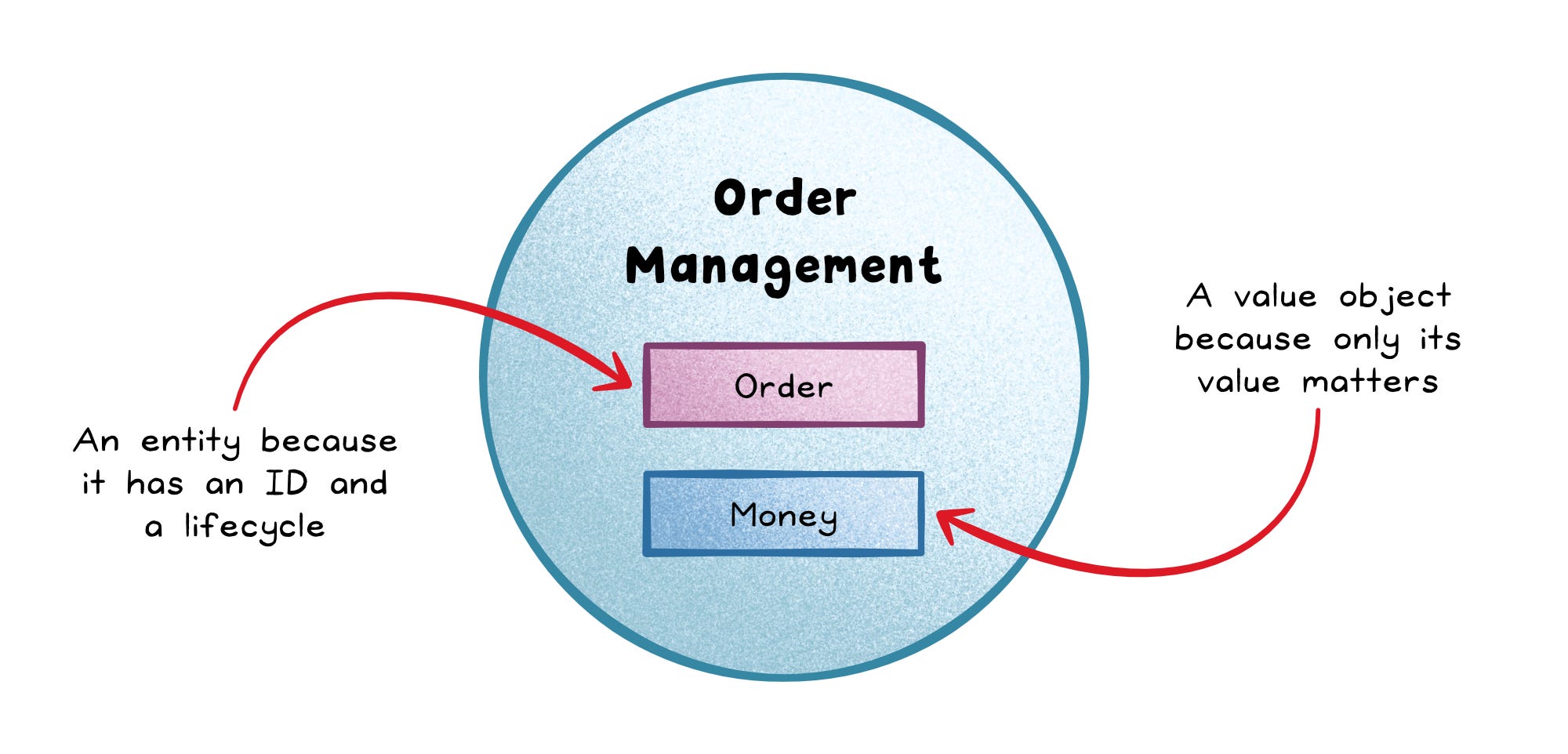
Inside a bounded context, you model the domain with entities and value objects.
An entity is defined by identity and lifecycle; like a Customer that stays the same “person” even if their address changes.
A value object is defined only by its values and is often immutable; like Money or Address.
Pros:
Clear intent in code → “Identity” and “attributes” stop being mixed together.
Fewer accidental bugs → Value objects reduce side effects because they are treated as pure descriptive values.
Better tests → You can test domain behavior directly, because it lives where the domain lives.
Cons:
More types upfront → You will write more domain code early, because clarity has a cost.
Requires discipline → If you slip into “anemic models” (data-only objects), you lose most of the value.
4) Enforce consistency with Aggregates
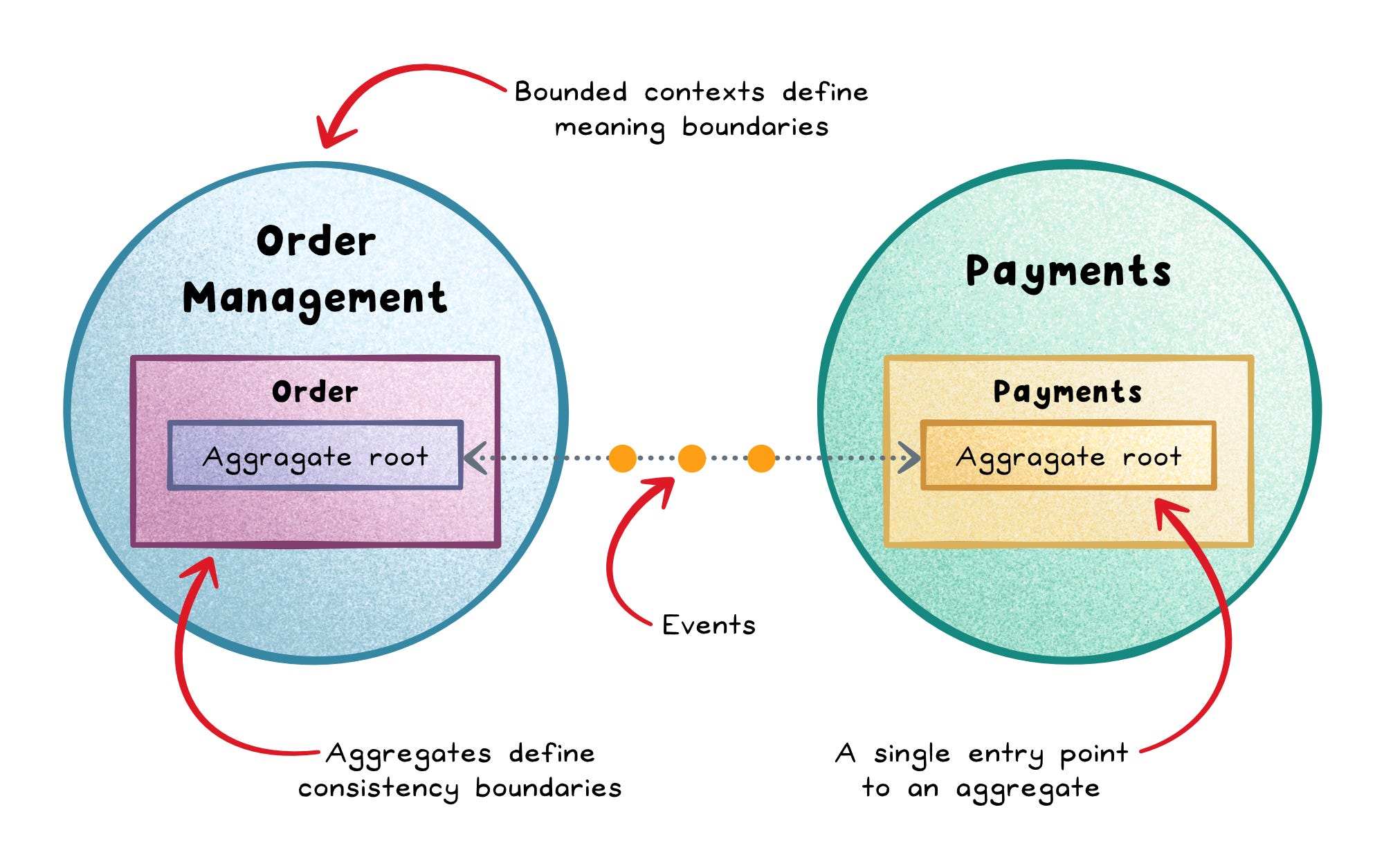
An aggregate is a cluster of domain objects treated as one consistency boundary, controlled by an aggregate root.
Outside code talks to the root, not the internal parts, so business rules stay centralized and enforceable.
Pros:
Fewer consistency bugs → Invariants live in one place, not duplicated across services and controllers.
Clear transaction boundaries → Updates don’t cross aggregate boundaries, which simplifies correctness.
Better maintainability → Code reads like “business operations,” because that’s what the aggregate exposes.
Cons:
You must choose boundaries carefully → Oversized aggregates become bottlenecks; undersized ones leak invariants.
Cross-aggregate workflows need orchestration → Some workflows become event-driven or application-layer-led by necessity.
5) Decouple workflows with Domain Events + keep persistence out with Repositories
A domain event captures something meaningful that happened in the domain, usually named in past tense like OrderPlaced or PaymentCompleted.
Inside one context it models a business fact; when published outward it often becomes an integration event used to coordinate other contexts.
That’s how you let Inventory react to OrderPlaced without letting Inventory reach into Order’s internal model.
A repository is a domain-facing interface for loading and saving aggregates (e.g. OrderRepository.save(order)), hiding database details from the domain layer.
Pros:
Lower coupling → Events let systems react without turning everything into direct dependencies.
Cleaner domain model → Repositories keep persistence concerns out of business logic.
Easier evolution → You can change databases or infrastructure with less impact on the core model.
Cons:
Event-driven complexity → Failures can surface later, and you have to think carefully about cross-context consistency.
More upfront work → Modeling + workshops can feel slow early on, because you’re buying long-term clarity.
When to choose DDD
DDD pays off most when understanding the domain is the hard part, not just the technical build.
Use these decision checks:
Domain complexity is high → You have lots of rules, exceptions, and nuanced workflows, so modeling reduces chaos.
The domain is core to business value → You invest because correctness and flexibility create advantage.
Many teams touch the system → Context boundaries help teams move independently because contracts stay explicit.
The system will live for years → A strong model acts like documentation because it preserves business knowledge in code.
When NOT to use DDD
DDD struggles when the problem is simple.
If your app is mostly CRUD, it adds layers and coordination you don’t need.
If you cannot get sustained access to domain experts, DDD becomes guesswork. And guesswork hardens into code faster than you think.
And if the project is short-lived or low-impact, the modeling cost rarely returns value.
Final thoughts
You don’t adopt DDD by adding patterns.
You adopt it by removing ambiguity.
Start with language, because words drive everything else. Split contexts before you share a model “for convenience.” Keep invariants inside aggregates, not scattered across services. Use events when the business thinks in milestones and outcomes.
If understanding breaks before performance does, DDD is the right tool.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, clear, and visual system design breakdowns straight to your inbox:
Great article! The way it presents the framework with its pros and cons is really well done. A few more examples would take it to the next level.
Love this article, and it comes at a perfect time as I’ve been digging into DDD a bit recently. Investing early in domain modeling is underrated. Skipping it often leads to tight coupling that’s painful to unwind later.