
Essential Caching Strategies for Optimal Performance
(4 Minutes) | Caching Strategies You Should Know


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Your data, fully managed and ready to scale
Presented by Render

Render’s fully managed Postgres and Key-Value datastores give you enterprise-grade performance without the maintenance burden. Spinning up a new database or cache takes minutes, and scaling is built in.
Need high availability, read replicas, or point-in-time recovery for Postgres? It’s all baked in.
Using Redis for caching or background jobs? Render handles that too—with the same reliable, production-ready setup.
Whether you’re powering AI features, handling background processing, or just keeping your app fast, Render lets you focus on building—while they handle the rest.
Caching Strategies: A Comparative Overview
In the current world of big data and high-speed applications, performance is a prominent consideration for any development team.
Caching is one of the most used techniques to boost performance due to its simplicity and wide range of use cases.
With caching, data is copied and stored in locations that are quick to access such as on the browser or a CDN.
A core part of any caching strategy is how data is updated and evicted from the cache. There are several approaches to choose from, each with distinct use cases.
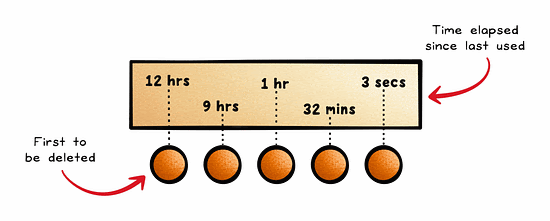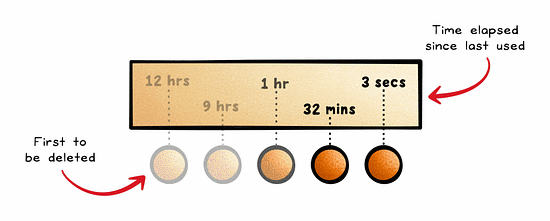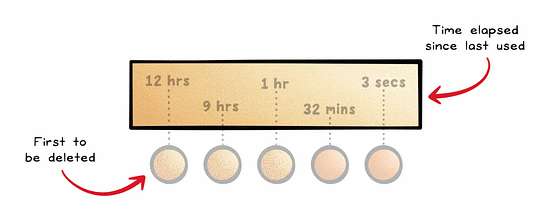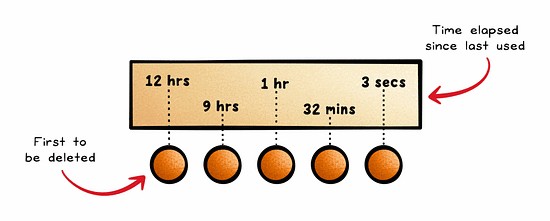
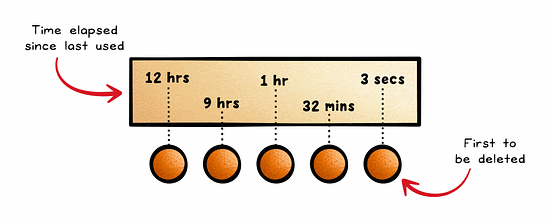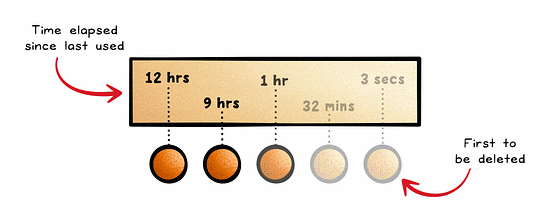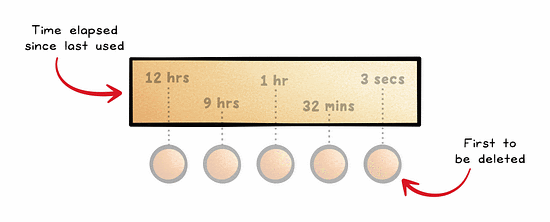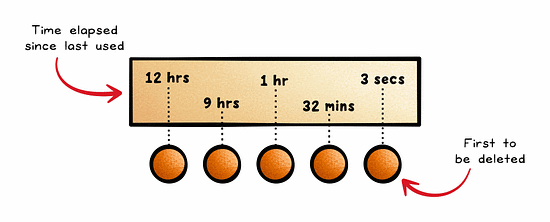
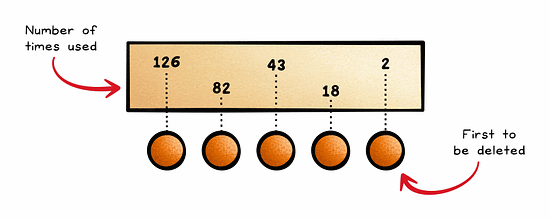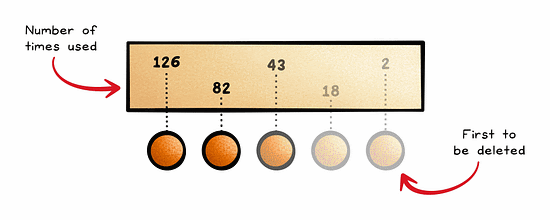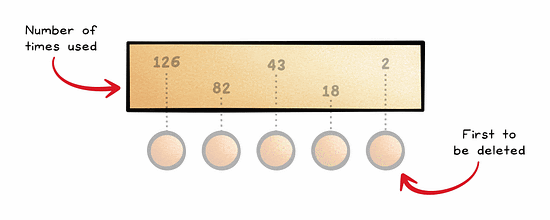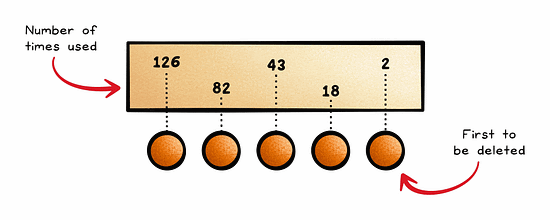
Least Recently Used (LRU) is an approach to cache management that frees up space for new data by removing data that has not been accessed or utilized for the longest period of time.
It assumes that recently accessed data will be needed again soon.
This is quite a common approach and is often used in browsers, CDNs, and operating systems.
Most Recently Used (MRU) is the opposite of LRU, where the most recently used data is removed first.
MRU tends not to be used often. However, it can be useful in tightly scoped use cases where recently accessed data is unlikely to be reused—such as certain streaming pipelines or stack-based workflows.
Least Frequently Used (LFU) removes data that is used the least.
Although it is a more accurate approach than LRU, it requires a mechanism to keep count of how often data is accessed, which adds complexity.
LFU also has the risk of keeping outdated data in the cache.
For these reasons, it is often used in combination with other strategies such as LRU.
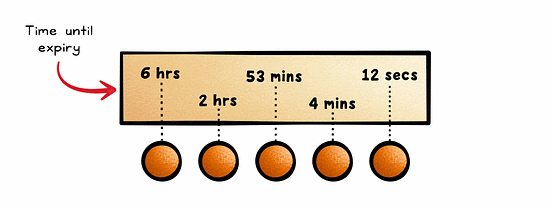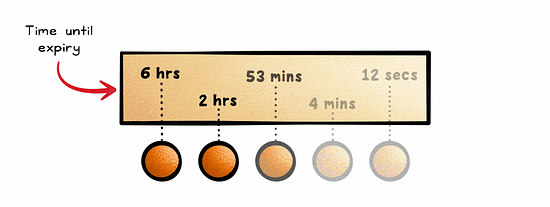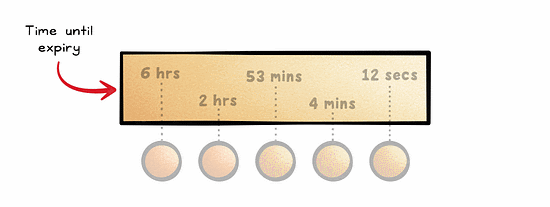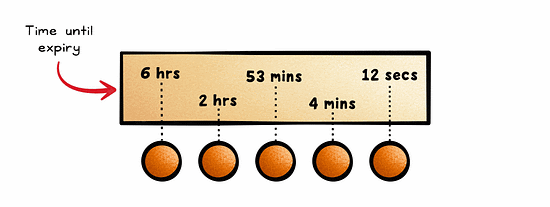
With Time-To-Live (TTL), data is kept in the cache for a pre-defined period of time.
This is ideal for cases where the current state of data is only valid for a certain period of time, such as session data.
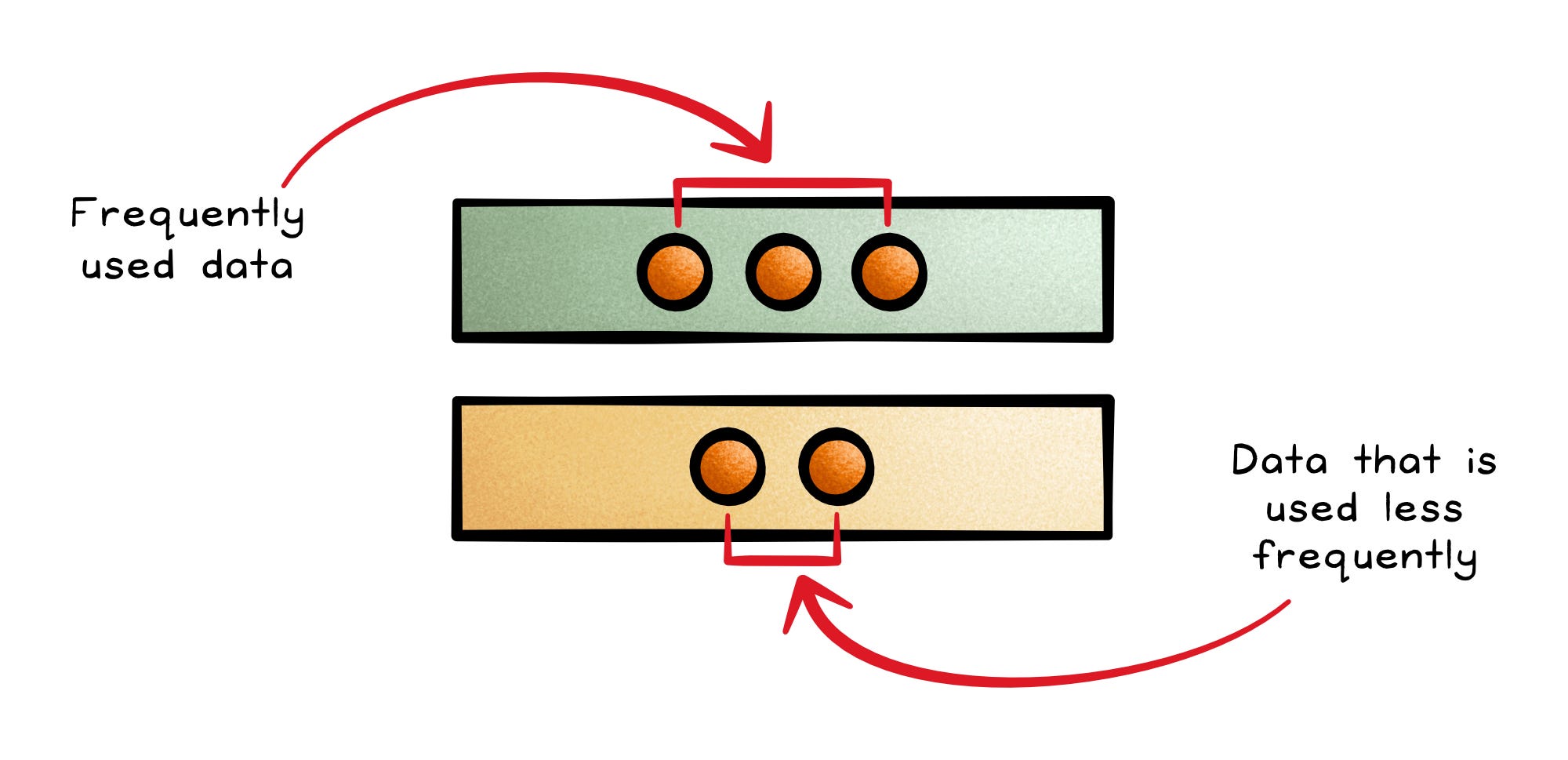
Two-tiered caching provides a more complex approach that strikes a balance between speed and cost. In this design, data is split up between a first and second tier.
This first tier is a smaller, faster, and often more expensive caching tier that stores frequently used data.
The second tier is a larger, slower, and less expensive tier that stores data that is used less frequently.
The five strategies mentioned above are the most popular approaches to caching. There are other notable mentions, such as the following:
First In, First Out (FIFO): The oldest data is deleted first.
Random Replacement (RR): Randomly selects data to be deleted.
Adaptive Replacement Cache (ARC): Uses a self-tuning algorithm that tracks recency and frequency to determine which data to delete first.
There’s no one-size-fits-all solution. The best caching strategy depends on your system’s access patterns, update frequency, latency requirements, and cost constraints. Understanding and combining multiple strategies often leads to the most optimal performance.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: