
gRPC Clearly Explained
(4 minutes) | What gRPC actually is, and the real reasons teams adopt it beyond “it’s faster”.


From Similarity to Relevance in Vector Search
Presented by MongoDB

MongoDB Atlas Vector Search now supports lexical prefilters, letting teams apply analyzed text filters (like fuzzy search and phrase matching) or geo constraints before vector similarity runs. The result is higher relevance, lower latency, and more reliable RAG and search at scale.
gRPC: What It Is and Why Teams Use It
Most teams reach for REST by habit.
It works, it’s everywhere, and every tool knows how to talk HTTP+JSON.
But once you have dozens of microservices calling each other thousands of times per request, REST can quietly become the bottleneck.
That’s where gRPC shows up with a very different model: “call a function on another service as if it were local,” and make it fast.
What gRPC (and RPC) really is
Before gRPC, there’s RPC.
Remote Procedure Call (RPC) is a model where you call a function that runs on another machine, but it feels local to the caller.
You call a method, pass arguments, and get a result back. The network exists, but it’s intentionally hidden so developers can think in terms of functions instead of sockets and packets.
gRPC is a modern, open-source RPC framework released by Google in 2015. It takes the RPC idea and standardizes how services define methods, exchange data, and communicate efficiently over the network.
Two building blocks drive almost everything you feel in practice:
HTTP/2 → The transport protocol. It keeps a long-lived connection and supports multiplexed streams.
Protocol Buffers (Protobuf) → The data format. It’s a compact binary serialization with a schema (a defined shape).
Together, these turn “call a service” into a strongly typed operation instead of a loosely structured document exchange.
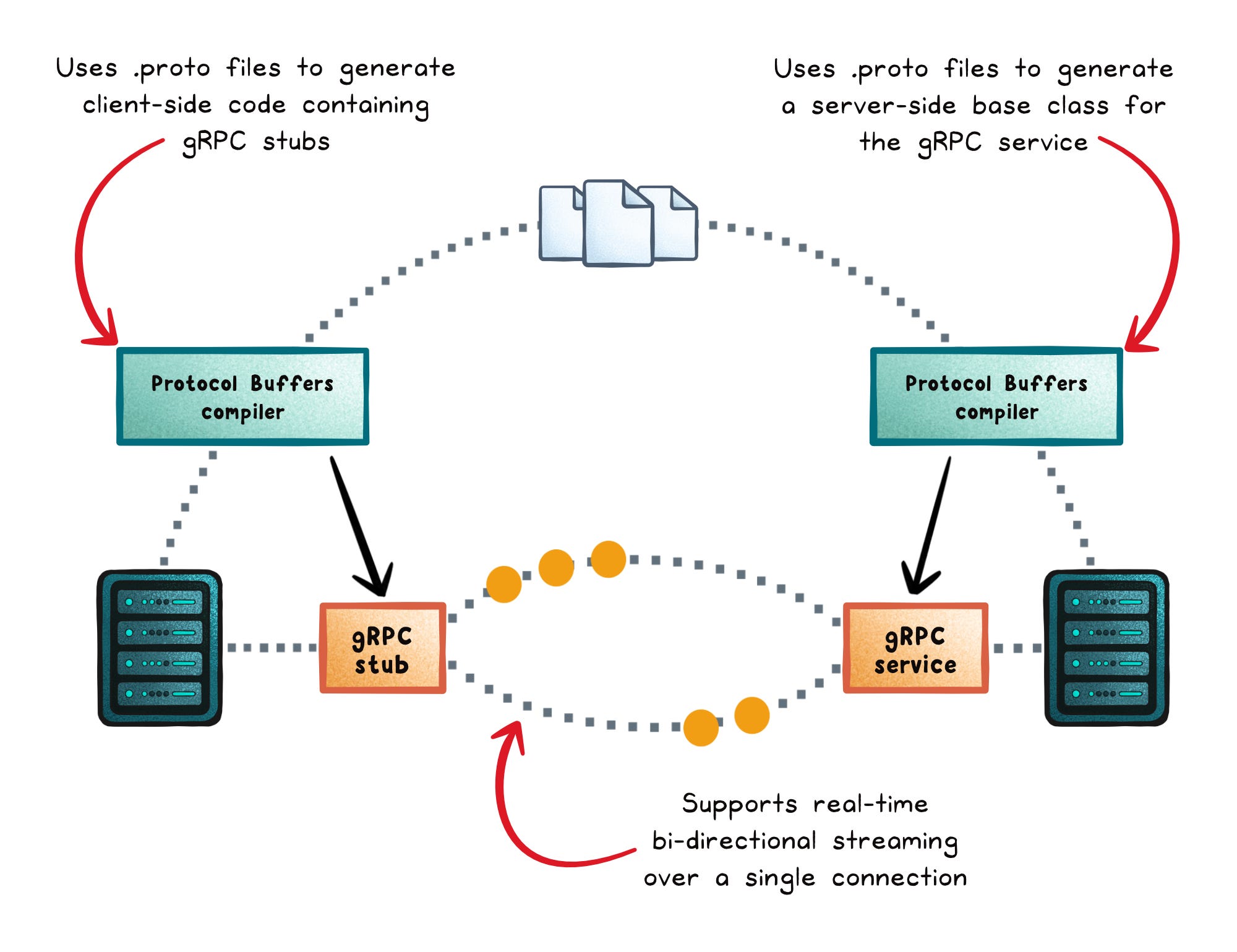
How gRPC actually works
gRPC starts with a service definition. You describe your API in a .proto file by defining services (methods) and messages (request and response shapes).
This file is the contract. Both client and server are built from it.
From that contract, gRPC generates code:
Client stubs → Methods you call like local functions.
Server interfaces → Methods you implement with your business logic.
When a client calls a gRPC method, the flow is straightforward:
Serialize → The request is encoded into Protobuf’s binary format.
Send → The message travels over an existing HTTP/2 stream.
Dispatch → The server routes it to the correct method.
Execute → Your code runs.
Respond → The result is serialized and streamed back.
Because gRPC uses HTTP/2, many calls share one connection and run in parallel. A slow response doesn’t block faster ones behind it, which keeps tail latency under control.
Streaming uses the same mechanism:
Server-streaming → One request, many responses over time.
Client-streaming → Many requests, one final response.
Bidirectional streaming → Both sides send messages independently.
Backpressure is built in. If one side slows down, gRPC slows the stream instead of piling up memory or threads.
The core idea is simple: define a strict contract, generate code from it, and move typed messages efficiently over a shared connection.
Where gRPC pays off
gRPC is a strong fit when you control both ends and you care about efficiency.
High call volume microservices → Lower per-call overhead adds up fast at scale.
Latency-sensitive graphs → Multiplexing + smaller payloads reduces tail latency pressure.
Polyglot stacks → One .proto contract generates stubs across languages, reducing “JSON drift.”
Service mesh environments → gRPC routes cleanly through modern proxies and is common in mesh control-plane protocols.
Tradeoffs you feel immediately
gRPC’s downsides are predictable, and they usually show up early on.
Browser calls are not native → You often need gRPC-Web or a REST/JSON gateway for front-end use.
Debugging is less “curl-friendly” → Binary payloads require tooling like grpcurl or GUI clients with schema access.
Contracts tighten coupling → Clients must update generated code as schemas evolve, so versioning discipline matters.
Infra must support HTTP/2 well → Some proxies and firewalls need explicit support or configuration.
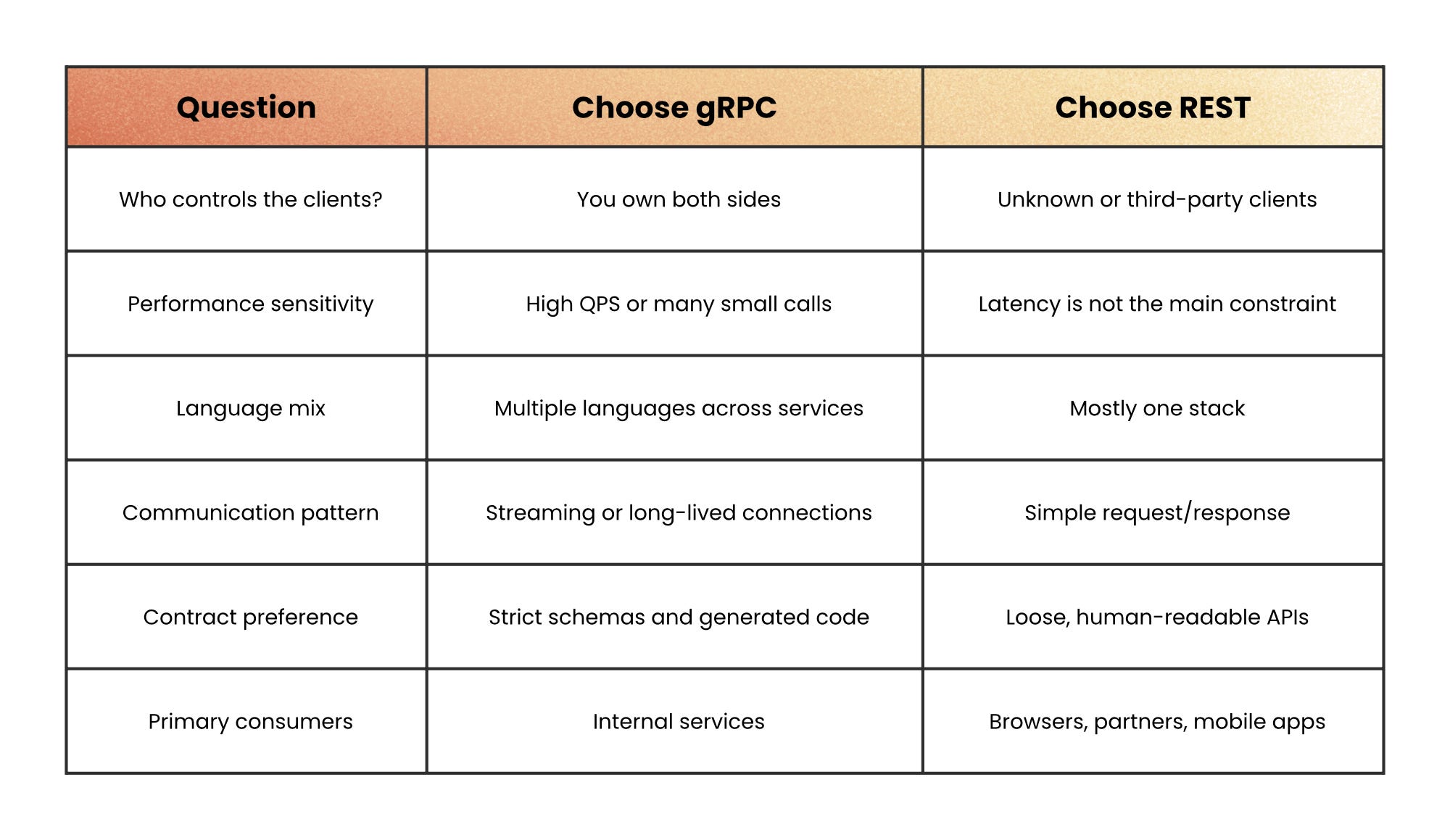
How to Decide: Is gRPC a Fit for Your System?
Use gRPC when most of the following are true:
You control both client and server → Internal microservices inside the same organization.
You’re performance-sensitive → Many small calls per request, or very high QPS between services.
You’re polyglot → Multiple languages across teams and services.
You need streaming → Real-time updates, telemetry, chat, or continuous feeds.
You want strict contracts → You care about compile-time guarantees and explicit schemas.
Stick to REST (or layer a REST gateway in front of gRPC) when:
You expose public APIs to unknown clients.
You want easy browser and curl-based experimentation.
Your main pain is clarity and discoverability, not raw latency or throughput.
In practice, most teams don’t choose one or the other; they split the responsibility.
gRPC inside your network → Service-to-service, behind an API gateway or service mesh.
REST/JSON at the edge → For browsers, partners, and mobile apps that prefer HTTP+JSON.
Recap
gRPC is not “REST but faster.”
It’s a different model: remote procedure calls over HTTP/2, using Protobuf contracts, with first-class support for streaming and strong typing.
That makes it excellent for internal microservices, high-performance backends, and real-time systems; as long as you’re willing to invest in schemas, tooling, and a slightly steeper learning curve.
If you’re hitting the limits of REST inside your system (too many chatty JSON calls, tricky real-time updates, or a messy polyglot codebase) gRPC is worth a serious look.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox:
This is a great description! Can you describe why polyglot environments benefit under gRPC? REST is language and environment agnostic. What detriments does REST introduce that is solved by gRPC’s approach?