
Hashing vs Encryption vs Tokenization
(5 minutes) | One question decides which one you should use...


Reproducible Dev Environments That Work Everywhere
Presented by Flox
Flox lets teams define development environments once and run them consistently across local environments, CI pipelines, and production systems. By capturing dependencies, tools, and environment variables in a single manifest, teams can eliminate environment drift and ship software more reliably.
Hashing vs Encryption vs Tokenization: How to Pick the Right Tool
Most security vulnerabilities aren’t caused by weak algorithms.
They come from using the right tool in the wrong situation.
Encrypting what should be hashed, or hashing what should be tokenized, doesn’t trigger an alarm; it just quietly erodes your defenses while everything appears to be working fine.
Hashing, encryption, and tokenization all transform sensitive data, but they answer completely different questions. Knowing which question you’re asking is the whole game.
The core question: what are you trying to protect?
Before picking a tool, answer one question:
Do you need to recover the original value?
If no → hashing is likely the right fit.
If yes, and the goal is confidentiality → use encryption.
If yes, but the goal is limiting where sensitive data spreads → use tokenization.
Each technique maps cleanly to a different security objective:
Hashing → Integrity and verification
Encryption → Confidentiality with controlled access
Tokenization → Exposure reduction across systems
They overlap in underlying mechanisms. They do not overlap in purpose.
Hashing
A cryptographic hash function takes input of any size and produces a fixed-length output called a digest. Change a single character, and the output changes completely.
It is intentionally one-way: you cannot feasibly recover the original input from the digest.
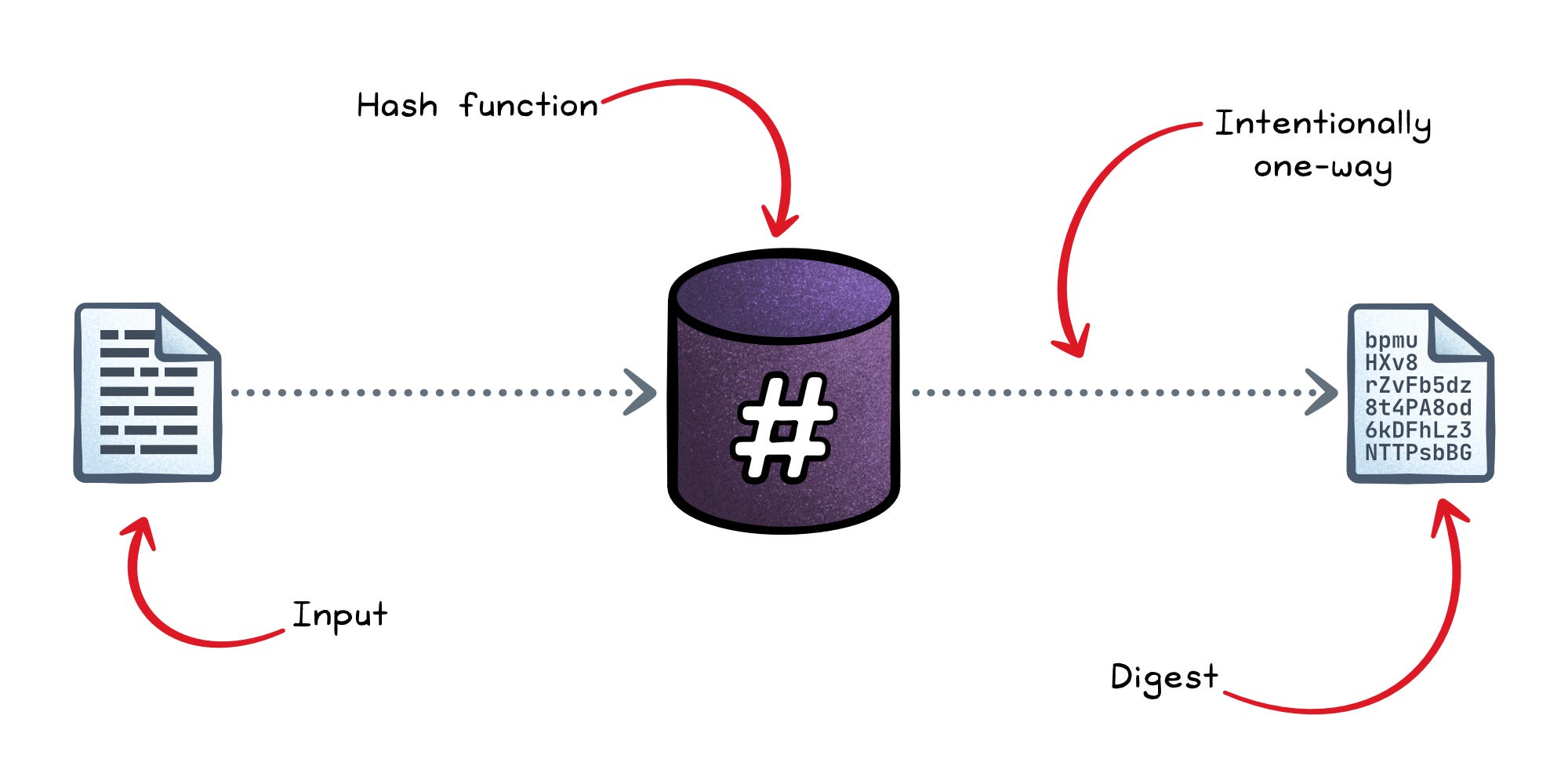
Hashing is built for integrity:
Verifying file downloads
Detecting message tampering
Supporting digital signatures
Storing passwords (with specialized constructions)
But hashing has a subtlety most developers miss: not all hashing is the same.
Unkeyed hash (e.g. SHA-256) → Confirm that data hasn’t changed, but only through a trusted channel. An attacker who controls both the file and its published digest can swap both.
Keyed hash (e.g. HMAC) → Use a shared secret to authenticate data against an active attacker. Required when you need integrity and authenticity.
Password hashing (e.g. Argon2, scrypt, bcrypt) → A specialized case. Deliberately slow and memory-hard to make brute-force attacks expensive after a database breach. Never use SHA-256 for passwords.
The most common failure here is using a fast, unkeyed hash as a stand-in for authentication.
It isn’t.
What hashing cannot do:
It cannot provide confidentiality.
It cannot restore data.
It does not automatically provide authentication unless keyed.
If you need the original value later, hashing is the wrong tool.
Encryption
Encryption transforms plaintext into ciphertext using a key. Only someone with the right key can reverse it.
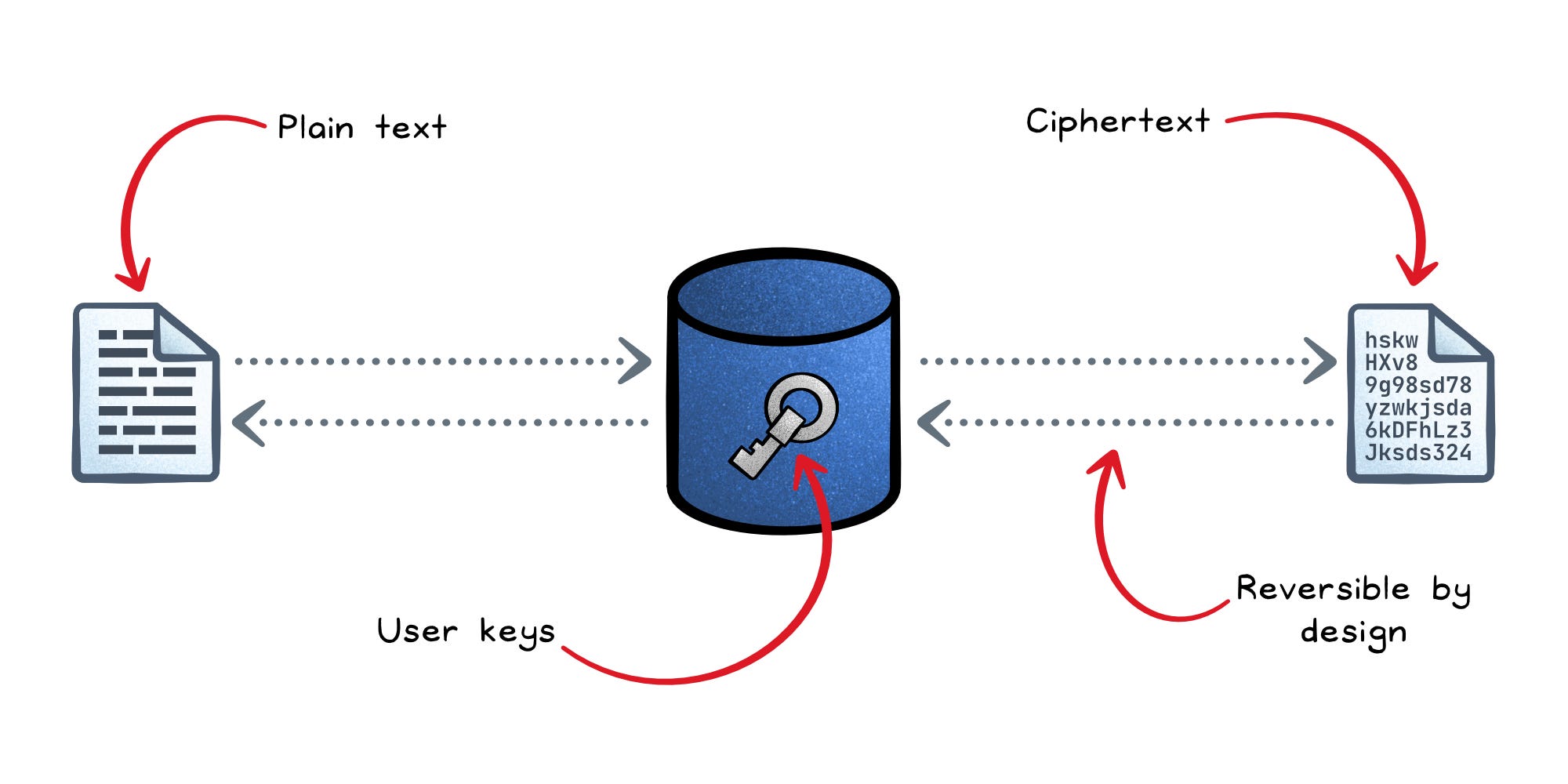
Unlike hashing, encryption is reversible by design.
This makes it the right tool for confidentiality:
Data in transit (TLS)
Data at rest (disk/database encryption)
Secure messaging
Secure storage
Modern encryption comes in two main shapes:
Symmetric encryption (AES) → The same key encrypts and decrypts. Fast and designed for bulk data.
Asymmetric encryption (RSA, ECC) → Public key encrypts, private key decrypts. Slower, used primarily for key exchange and signatures, not bulk data.
Real systems almost always use hybrid encryption: symmetric encryption for the data itself, asymmetric encryption to securely exchange the symmetric key. TLS works exactly this way.
There’s one critical nuance: confidentiality is not the same as integrity.
Today, encryption without integrity is considered incomplete. Authenticated Encryption with Associated Data (AEAD), such as AES-GCM, protects both:
Confidentiality → Attackers can’t read it.
Integrity/authenticity → Attackers can’t modify it undetected .
Older designs that are encrypted without authentication can be manipulated by an attacker who never sees the plaintext. This is why AEAD is now strongly preferred.
What encryption optimizes for:
Controlled access to original data
Strong confidentiality guarantees
Regulatory recognition (GDPR, HIPAA references encryption explicitly)
But encryption introduces a heavy dependency:
Key management.
Key lifecycle, rotation, storage (often HSM-backed), and cryptoperiod policies become first-class concerns.
Encryption protects content. It does not reduce how widely that content spreads.
Tokenization
Tokenization replaces a sensitive value with a surrogate “token”. The token carries no exploitable meaning on its own.
For example, in payment systems a PAN (Primary Account Number) becomes a token and downstream systems store the token, not the card number.
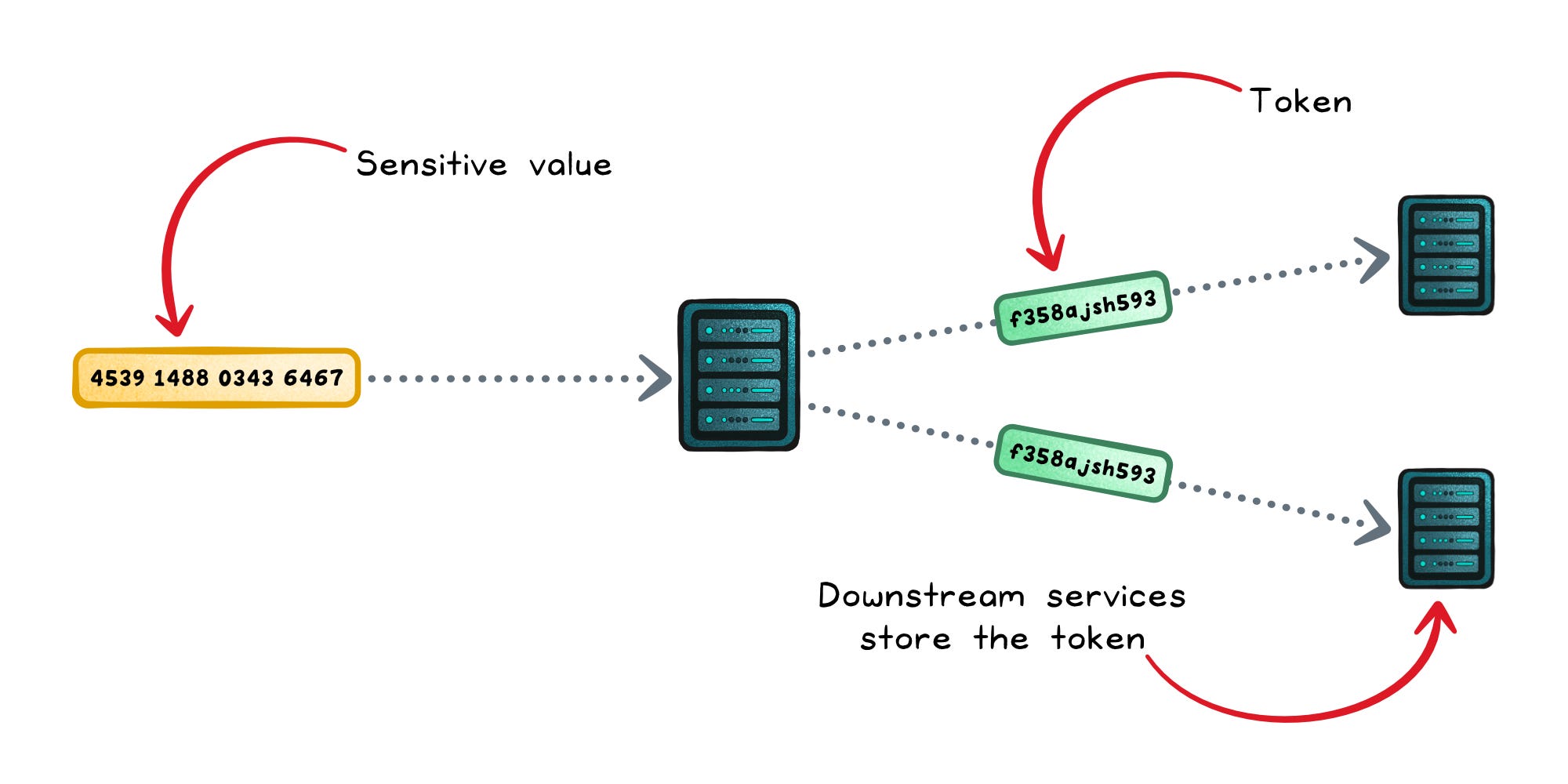
The difference from encryption is architectural:
Encryption protects data.
Tokenization limits exposure of data across systems.
Encryption is the answer to “how do we hide this data?”. Tokenization is the answer to “how do we stop this data from spreading?”.
There are three main implementations:
Vault-based tokenization → A random token is generated and stored alongside the original value in a protected database (the vault). De-tokenization means querying the vault. Simple to reason about, but the vault becomes your highest-value attack target.
Vaultless (cryptographic) tokenization → The token is generated using format-preserving encryption. No vault needed, but key management becomes critical.
Irreversible tokenization → Tokens are never designed to be reversed. Used when you only need to validate or reference a record, not recover the original value.
Tokenization earns its place in regulated environments because it limits where sensitive data lives.
Side-by-side comparison
Hashing, encryption, and tokenization all transform data, but they protect it in very different ways.
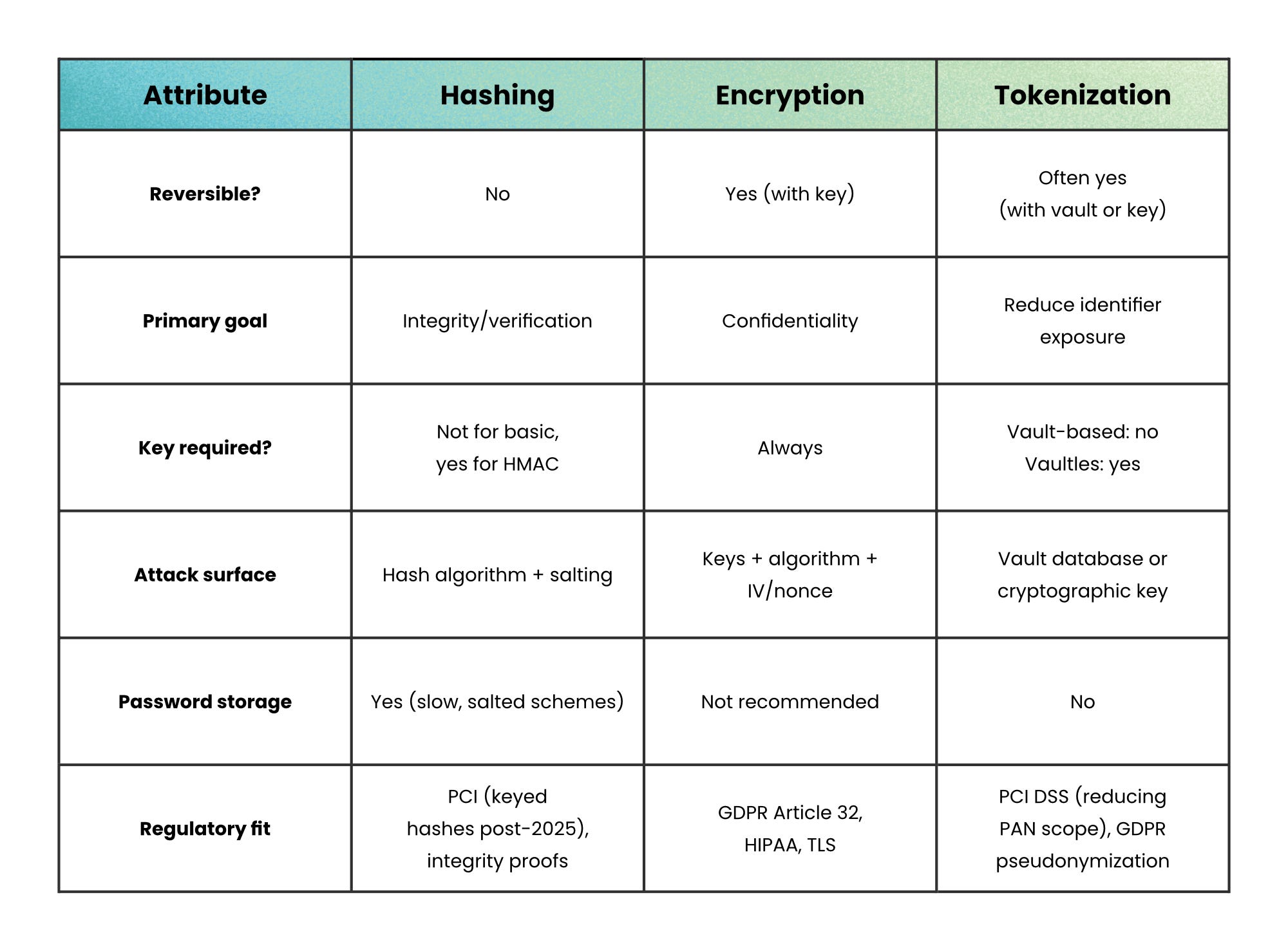
When not to use each
Knowing when not to reach for a tool is as important as knowing when to use it.
Don’t use hashing when:
You need to retrieve the original value. A hash is a one-way door.
You’re protecting a password with a fast algorithm like SHA-256. Use bcrypt, scrypt, or Argon2 instead, because speed is the enemy of password security.
You’re treating an unkeyed hash as a MAC. It isn’t, and extension attacks will prove it.
Don’t use encryption when:
You never need to read the original value back. Hashing is simpler and removes the key-management burden.
You’re trying to limit data spread across services. Encrypting a PAN and sending the ciphertext everywhere just moves the problem; tokenization removes it.
Don’t use tokenization when:
Your system is small and doesn’t have a serious compliance or data-minimization requirement. Running a vault adds availability dependencies and operational overhead that may not be justified.
You need the original value to be queryable for range scans or analytics joins. Tokenization scatters values in ways that break ordering and aggregation.
Recap
Hashing, encryption, and tokenization aren’t variations of the same idea; they’re answers to different questions.
Hash when you need to verify. Encrypt when you need to retrieve. Tokenize when you need to contain.
Get the question wrong and the technique doesn’t fail loudly; it just quietly protects the wrong thing.
The algorithm is rarely the problem. The choice usually is.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, clear, and visual system design breakdowns straight to your inbox:
I found this topic to be a useful reminder.
Subscribed!
Checkout my posts related to Identity Security/IAM.
Great blog
Good insights
Nice structure