
How LLMs Actually Work
(5 Minutes) | LLMs Clearly Explained


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Your terminal, but smarter
Presented by Amazon Web Services (AWS)

Q Developer CLI agent brings intelligent assistance directly to your command line. Need to generate code, call APIs, or automate repetitive tasks? Just ask. It adapts to your feedback in real-time and handles complex workflows while you sip your coffee. Because the best tools work where you already do.
How LLMs Actually Work
LLMs aren't intelligent. They don't understand your words, and they definitely don’t “think.”
And yet… they can pass bar exams, write essays, and debug code, and evolving the world around us.
Let’s peel back the layers and walk through how LLMs go datasets to generating coherent, context-aware, useful outputs.
1. Learning from Massive Text Datasets
It all starts with data.
LLMs are trained on unimaginably large volumes of text—books, web pages, documentation, forums, and sometimes codebases. This raw text is first cleaned and processed, then tokenized. Tokenisation is the process of breaking down text into chunks that the model can handle—words, subwords, or even individual characters, depending on the tokeniser.
The goal in this phase isn't to "memorize" content, but to learn statistical patterns across tokens. That is, which tokens are likely to follow others in a given context. This forms the basis of a model’s linguistic intuition.
2. Training with Transformers
The magic happens during training.
The transformer architecture—first introduced in 2017—uses a mechanism called self-attention to understand the relationships between tokens, no matter how far apart they are in a sentence or paragraph.
Each layer in a transformer network learns increasingly abstract representations of language. Early layers detect local syntax (eg; adjective-noun pairs), while deeper layers can pick up on meaning, tone, and intent. These patterns are encoded in the model’s weights—massive matrices of numbers optimized iteratively through gradient descent and backpropagation, enabling prediction accuracy.
Training is a multi-week (or multi-month) process requiring clusters of GPUs or TPUs. During this time, the model adjusts billions (or trillions) of parameters to reduce its prediction error over time.
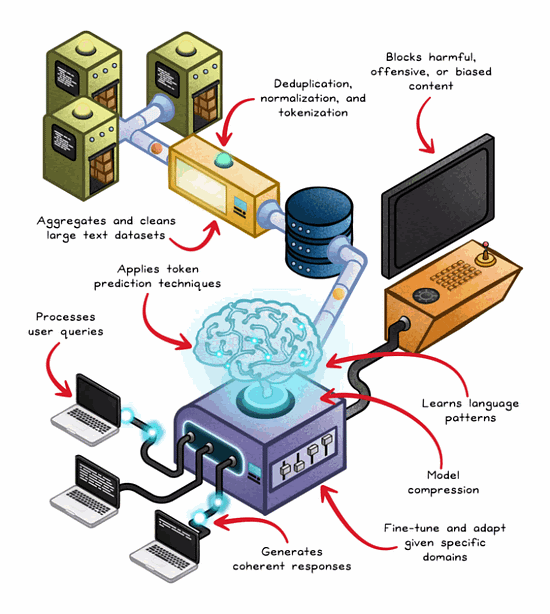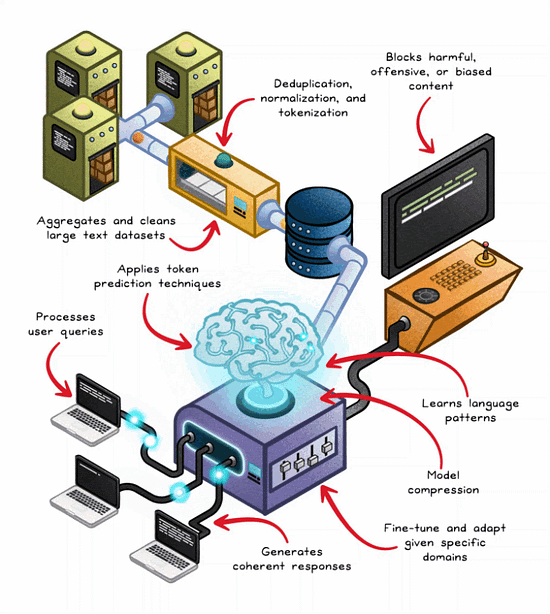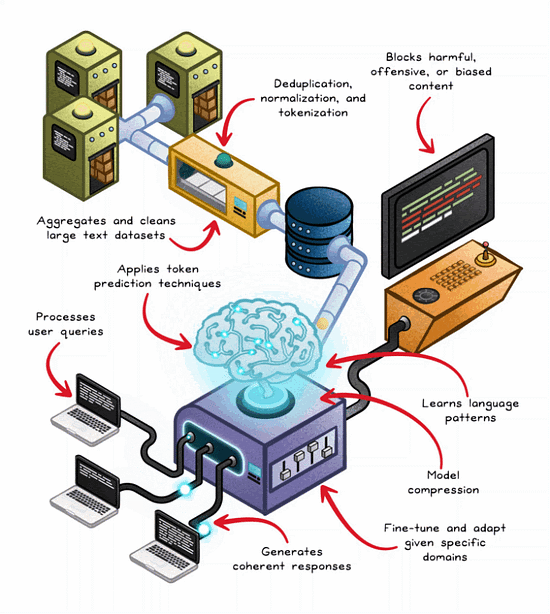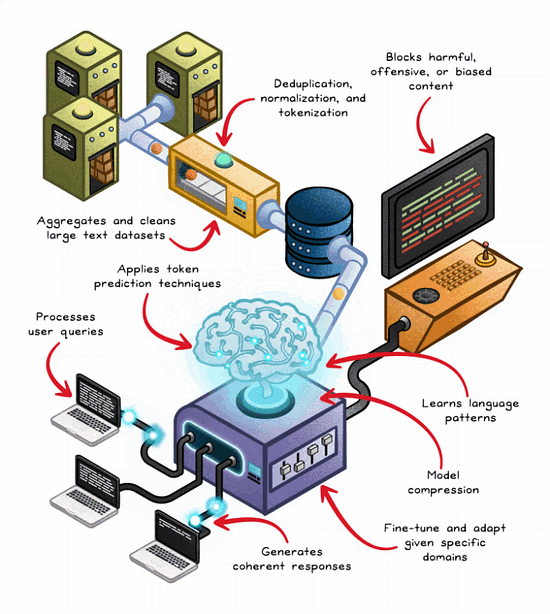
3. Fine-Tuning for Real-World Use
Once trained, the base model is like a raw generalist—it knows language structure, but it hasn’t specialized. Fine-tuning molds it for specific tasks.
This is where techniques like:
Supervised fine-tuning (eg; labeling good vs. bad answers),
Reinforcement Learning from Human Feedback (RLHF) (to align model behavior with human expectations), and
Parameter-efficient methods like LoRA (adapting large models with small additional layers)
…come into play.
These steps drastically improve usability for downstream applications like coding assistants, search agents, and customer support bots. The fine-tuned model can now respond in ways that feel useful rather than just fluent.
4. Generating Responses (with a Memory Boost)
Now the model is ready for inference—generating text based on user prompts.
Under the hood, this is a probability game.
The LLM predicts the next token given the input tokens, iteratively generating until the response is complete. Decoding strategies like beam search, nucleus sampling, and temperature control shape the creativity and determinism of the outputs.
But raw generation isn’t always enough. Modern LLMs often use Retrieval-Augmented Generation (RAG) to enhance factual accuracy. Here, the model first retrieves relevant context from an external knowledge base (like a document store or vector database), then conditions its response on that data.
This gives the illusion of real-time knowledge, without retraining the model.
5. Optimization and Safety Before Deployment
LLMs aren’t deployed raw. They go through post-training filtering to remove biased, harmful, or nonsensical behavior. This is part technical (content filters, moderation heuristics) and part human-in-the-loop QA.
They’re also optimized for real-world constraints:
Quantization reduces precision to save memory,
Pruning removes unnecessary parameters,
Distillation compresses large models into smaller, faster variants.
This makes it feasible to run them efficiently on the cloud—or even on edge devices.
The Challenges
Despite their capabilities, LLMs remain fallible. They:
Hallucinate facts
Inherit biases from training data
Require massive compute budgets
The space is evolving rapidly with techniques that are addressing these issues, such as:
Speculative decoding (to speed up inference)
Hybrid architecture (cloud + on-device deployment)
Tool integration (letting LLMs call APIs or external calculators)
Final Thoughts
LLMs are not magic or sentient, nor do they “understand” in the human sense.
They’re incredible pattern matchers—trained on human language, honed with statistical precision, and wrapped in carefully designed safety nets.
They’re powerful tools that are reshaping how we code, write, learn, and the world of work in general. While all the change can feel daunting, there’s no doubt that LLMs are having massive impact and evolving at an incredible pace.
These powerful tools are reshaping how we code, write, learn, and work, often faster than we anticipate. While rapid technological change can feel daunting, it’s also a remarkable opportunity—one that’s worth understanding deeply and leveraging.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: