
How Message Queues Actually Work
(4 Minutes) | When to Use Them, The Tradeoffs to Watch Out For, and How to Avoid Common Pitfalls


Make AI Smart on Huge Codebases
Presented by Augment Code

When your project grows to millions of lines, many AI assistants falter. Augment Code’s context engine is built for scale—indexing dependencies, reducing latency, and surfacing relevant code—even across large, modular systems.
Message Queues Clearly Explained
Calling an API is simple, you send a request and get a response.
Running a message queue is not.
It introduces a broker, persistence, acknowledgments, retries, and dead-letter queues. That’s extra moving parts, and they all need to be monitored, tuned, and maintained.
Yet in the right context, that complexity pays off: queues make the difference between a system that collapses under spikes and one that absorbs them gracefully.
What Queues Address
Synchronous calls couple services tightly. If a downstream is slow or down, your request path stalls.
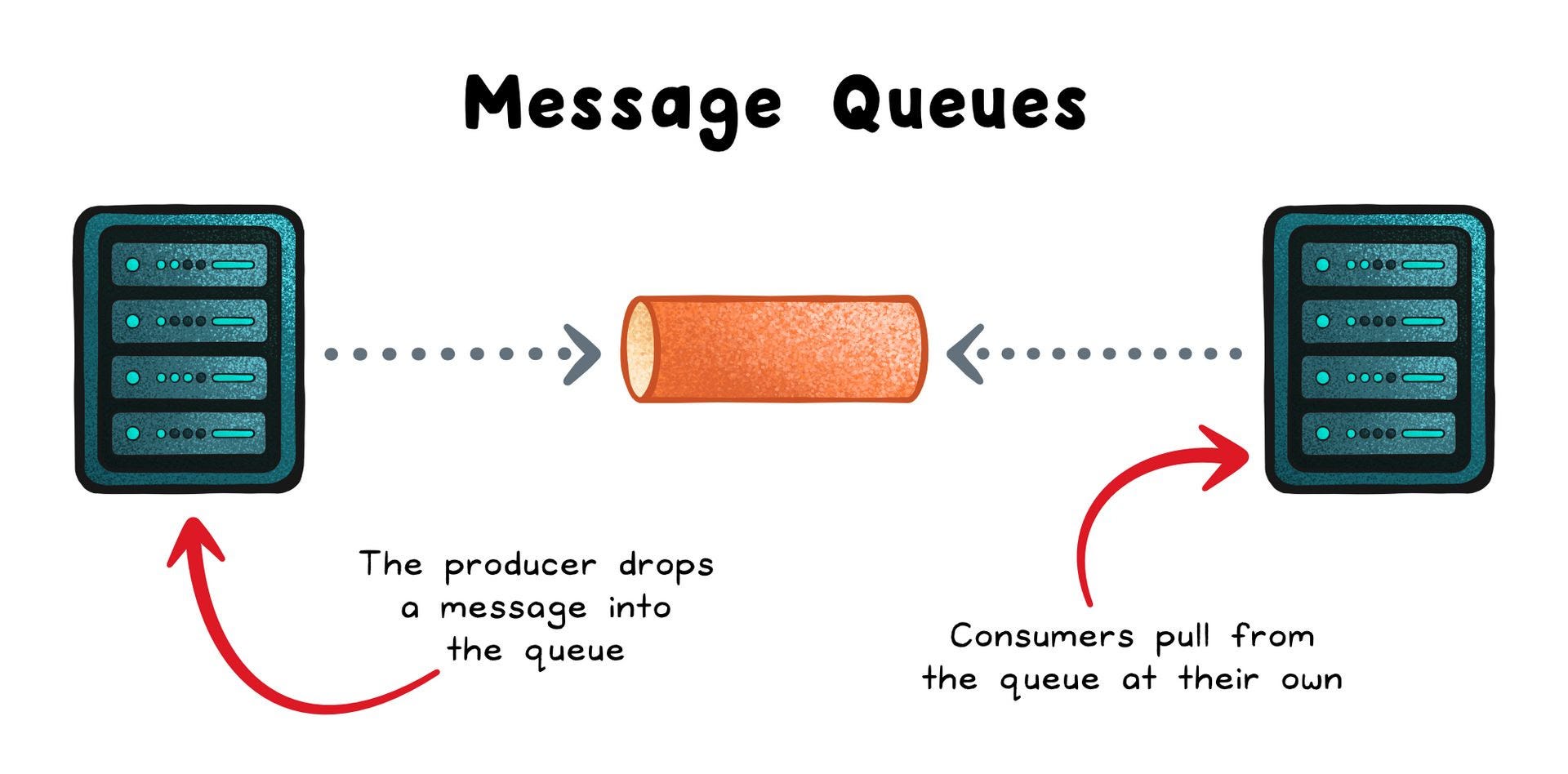
A message queue inserts a buffer between producers (senders) and consumers (workers), so work is recorded now and processed later.
Producers publish messages and return immediately; consumers pull when ready, acknowledge on success, and the broker deletes the message.
That simple pattern delivers decoupling, load smoothing, and fault tolerance because work isn’t lost when a component hiccups.
Advantages
Decoupling services → Producers and consumers don’t need to run at the same time, making failures and upgrades easier to isolate.
Load smoothing → Spikes in traffic are absorbed by the queue, protecting slower databases or APIs.
Asynchronous processing → Long-running tasks move to the background so the user-facing path stays fast.
Horizontal scaling → Add more consumers to process messages in parallel without touching the producers.
Fault tolerance → Persistent queues ensure work isn’t lost, and retries keep messages moving until they succeed.
Flexible patterns → Support for delayed jobs, priority queues, and publish/subscribe lets one tool cover many workflows.
Trade-offs
Added complexity → Brokers, acknowledgments, retries, and monitoring introduce new moving parts to manage.
Latency and eventual consistency → Messages take time to move through the queue, so results aren’t immediate.
Duplicate and out-of-order delivery → At-least-once delivery means consumers must be idempotent and handle replays.
Operational overhead → Queues require capacity planning, monitoring, and failover strategies, just like any database.
Overengineering risk → For simple, low-volume apps, the cost of running a queue may outweigh the benefits.
How It Works
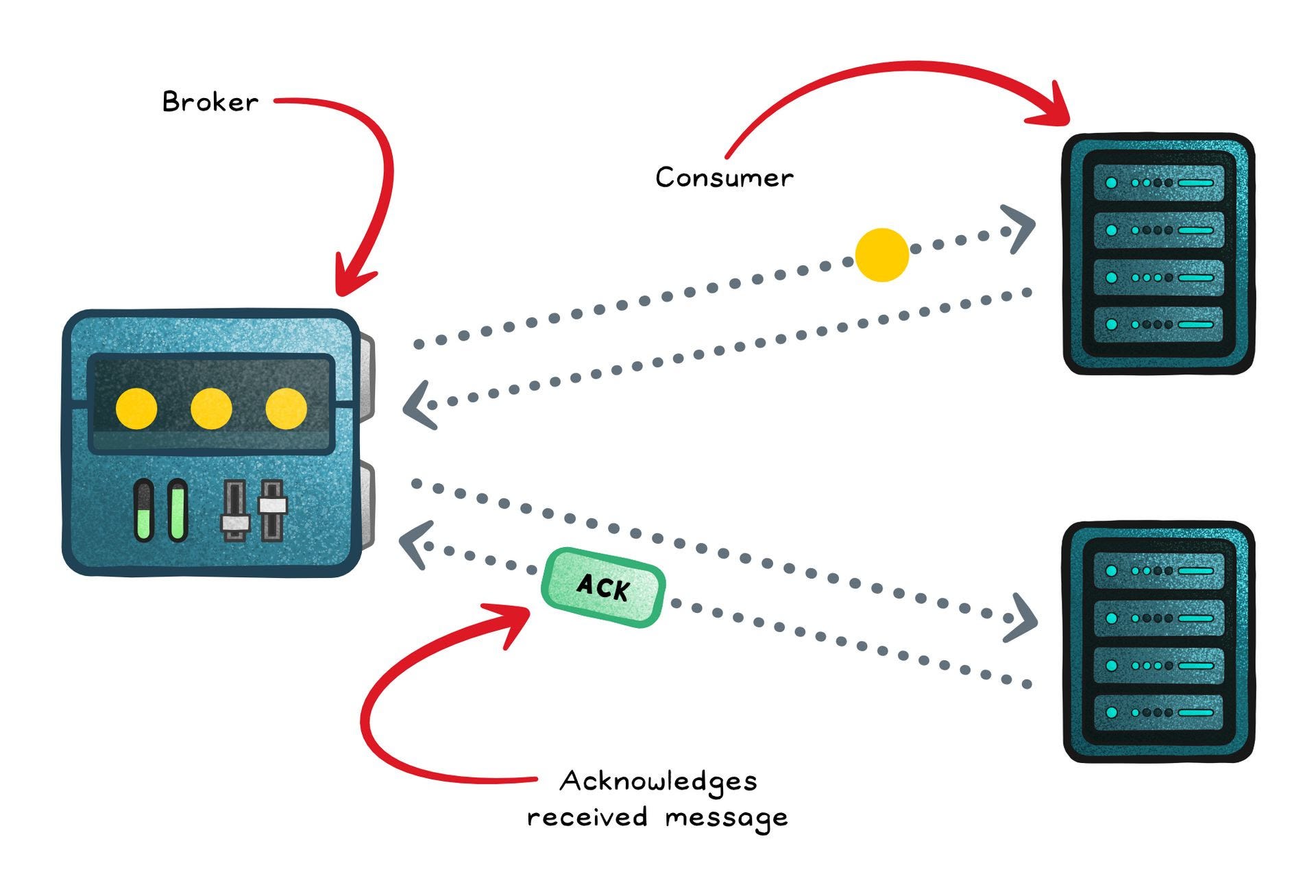
First, a producer sends a message; often this is a server triggered by a user action, which publishes a message into the queue.
A broker (e.g RabbitMQ, SQS) then stores the message and enforces delivery rules (FIFO, priority, delay).
Consumers process each message and then send an acknowledgment (ACK). Once the broker receives the ACK, it safely removes the message from the queue.
If the consumer fails before sending an ACK (for example, it crashes mid-task) the broker keeps the message and redelivers it later, ensuring that work is not lost. This is great for durability, but it means your handlers must be idempotent (safe to run twice).
To scale the system, multiple consumers can be added. The broker ensures that every message goes to exactly one consumer, which spreads the load across them automatically.
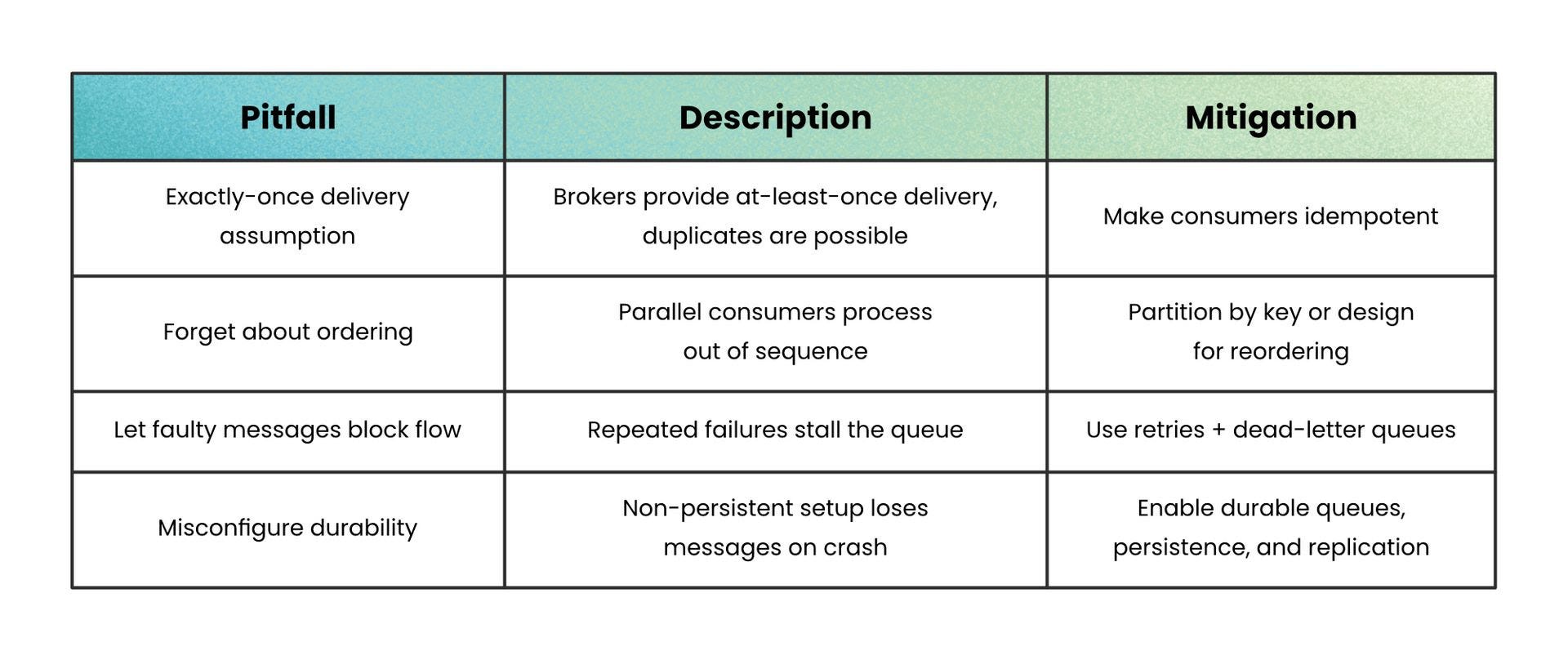
Common Pitfalls and How to Avoid Them
Assume exactly-once delivery → Most brokers provide at-least-once delivery, so duplicates are possible.
Avoid it by making consumers idempotent (safe to process the same message twice).
Forget about ordering → Parallel consumers can process messages out of sequence.
Avoid it by partitioning by a key (e.g. user ID) if strict order matters, or designing workflows that tolerate reordering.
Let faulty messages block progress → A message that always fails can stall the queue.
Avoid it by configuring retries with exponential backoff and routing repeated failures to a dead-letter queue (DLQ).
Misconfigure durability → If messages aren’t persisted to disk, a broker crash can wipe them out.
Avoid it by enabling durable queues, persistent messages, and replication where available.
Wrapping Up
The hard part isn’t learning how a queue works, it’s deciding when to use one.
If you need background processing, burst handling, or fault tolerance, a queue is a great choice.
If you need instant consistency, simplicity, or strict ordering, consider something else.
Reliable systems come from choosing the right tool for the problem, not the most popular one.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox:
Your explanation is plain and simple to understand. Thanks for writing.