- Level Up Coding
- Posts
- LUC #27: Breaking Down Clean Architecture — Core Ideas, Benefits, Drawbacks, and Use Cases
LUC #27: Breaking Down Clean Architecture — Core Ideas, Benefits, Drawbacks, and Use Cases
Plus, database indexing explained, load balancer vs reverse proxy, and data structures we encounter every day
Level Up Coding
November 09, 2023
Welcome back to another edition of Level Up Coding’s newsletter.
In today’s issue:
Navigating Complexity with Elegance: The Clean Architecture Approach
Database Indexing Explained (Recap)
Load Balancer vs Reverse Proxy (Recap)
Read time: 8 minutes
A big thank you to our partner Postman who keeps this newsletter free to the reader.
Postman launched a very useful new feature—Live Insights. You can now see in-depth insights about your production APIs, streamlining the debugging process. API endpoints are automatically updated and monitored in real-time. Check it out here.
Navigating Complexity with Elegance: The Clean Architecture Approach
The software development landscape is riddled with challenges that can often stem from how systems are structured.
Inadequate architecture leads to code that is not only difficult to understand and maintain but also susceptible to a host of problems as requirements evolve.
Clean Architecture, is a popular software design approach, created by Uncle Bob (Robert C. Martin), designed to tackle disorganization and enhance the maintainability and scalability of software. It offers a prescriptive approach to create systems with interchangeable components, focusing on maintainability, flexibility, and encapsulation of business logic.
The Anatomy of Clean Architecture
At its core, Clean Architecture is domain-centric, elevating the importance of the business logic—the "Domain"—above all else. It's a methodology that structures code to revolve around this crucial element, ensuring that other system components are orchestrated to bolster and not baffle the domain's purpose.
Visually, Clean Architecture can be represented by a series of concentric circles, with each circle symbolizing a distinct layer of software responsibility, delineating clear boundaries between different aspects of the system.

1) Entities Layer - In this innermost layer resides enterprise-wide business rules. Entities encapsulate the most general and high-level rules. They are the least likely to change when something external changes. For example, you would expect these business rules to be the same regardless of the application's interface or database.
2) Use Cases Layer - A layer outwards, we find the use cases. This layer contains application-specific business rules. It encapsulates and implements all of the use cases of the system. These use cases orchestrate the flow of data to and from the entities, and direct those entities to use their enterprise-wide business rules to achieve the goals of the use case.
3) Interface Adapters Layer - This layer is composed of adapters that convert data from the format most convenient for use cases and entities to the format most convenient for some external agency such as a database or the web. It is also here that data is presented to the user and actions from the user are interpreted into a format that the use case and entities layers can understand. Controllers, presenters, gateways, and repositories are components typically found in this layer.
4) Frameworks and Drivers Layer - Finally, at the perimeter, we have the frameworks and drivers. This outermost layer is where the details of how the application interacts with the outside world are implemented, including frameworks and tools for databases, web servers, external libraries, and other technologies that the application depends on. The frameworks and drivers should be made as interchangeable as possible, ensuring that changes in this layer have minimal impact on the inner layers.
As per the dependency rule, the inner layers cannot be aware of anything about the outer layers. Each inner circle is more abstract and higher-level than the outer circle it is encompassed by. This ensures that the core business logic is decoupled from external frameworks and interfaces, which promotes a more maintainable and scalable software structure.
The Merits and Pitfalls of Clean Architecture
The benefits of Clean Architecture are numerous, effectively addressing many concerns of software design:
🟢 Separation of concerns: By dividing the system into layers, Clean Architecture ensures that changes in one part do not affect others.
🟢 Loose coupling: Through its dependency rule, this architecture allows for easier interchangeability and integration of components.
🟢 Dependency inversion: Central to its philosophy, dependencies are inverted to rely on abstractions rather than concrete implementations, promoting flexibility.
🟢 Maintainability: The clear boundaries and rules make the system easier to sustain and evolve.
🟢 Testability: The decoupling of components and adherence to The Single Responsibility Principle make testing straightforward.
🟢 Modularity: It creates a plug-and-play environment, where modules can be developed and tested in isolation before being integrated into the system.
However, like any architectural style, it comes with its own set of challenges. The structured approach providing the benefits mentioned above can also lead to trade-offs that need careful consideration such as the following:
🔴 Increased Complexity: The very layers that provide structure can introduce complexity, especially in smaller projects where such rigorous segregation might be overkill.
🔴 Potential Rigidity: Following the rules can sometimes lead to a rigid system, making it difficult to adapt to certain types of changes.
🔴 Demand for Upfront Design: It requires a good deal of foresight and planning, which can be a demanding process.
Where Clean Architecture Shines Best
Adopting Clean Architecture works best in scenarios that align with its fundamental objectives; manageability, maintainability, and scalability.
This approach to software design complements Domain-Driven Design by encapsulating core business logic within central layers, fostering a model that mirrors real-world business scenarios.
For enterprise applications, Clean Architecture offers a scalable and organized structure that can handle complex integrations and business processes while maintaining system integrity.
When solving complex business logic, it simplifies complexity by isolating it in the inner layers, promoting clear logic flows and decision-making paths within the codebase.
Clean Architecture is also a great choice for Building highly testable projects. The separation of concerns ensures that components are easily testable in isolation, enhancing the robustness and reliability of the software.
For long-lived systems with expected changes in technology, this approach future-proofs systems by allowing technological components to be swapped or upgraded with minimal impact on the core business logic, ideal for systems that evolve over time.
Wrapping It Up
Clean Architecture is a thoughtful approach to software design, sharing similarities with other layered architectures but setting itself apart with its emphasis on the domain. It's an architecture that advocates for modularity, testability, and a clear separation of concerns, which, despite its potential for complexity, offers a robust template for building flexible and maintainable systems.
Ultimately, Clean Architecture is not a silver bullet. It's a disciplined blueprint that can significantly enhance the way software is developed, provided it's applied wisely. Like any architectural style, its effectiveness depends on the specific needs and situation of the project.
Database Indexing Explained (Recap)
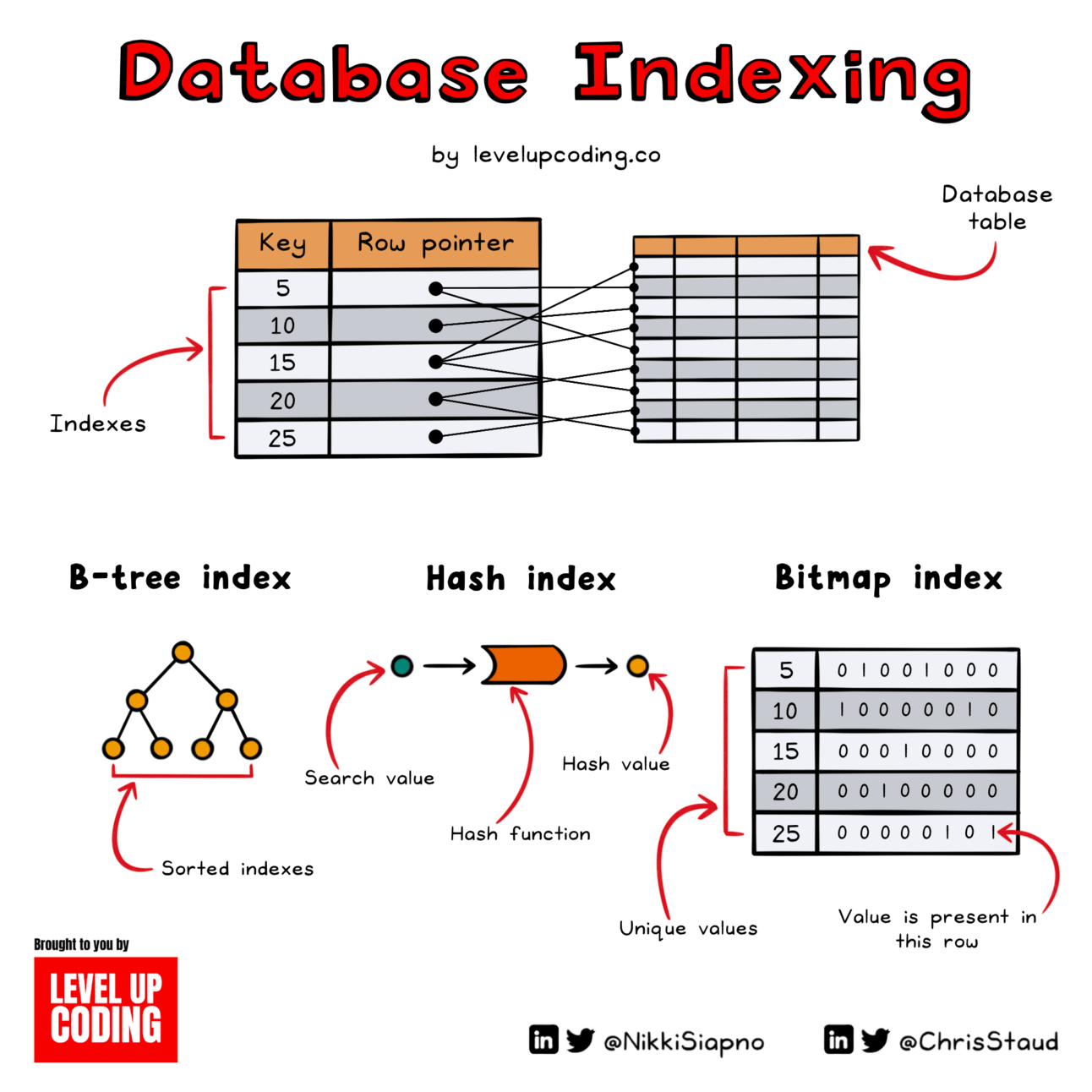
A database index is a lot like the index on the back of a book. It saves you time and energy by allowing you to easily find what you're looking for without having to flick through every page.
Database indexes work the same way. An index is a key-value pair where the key is used to search for data instead of the corresponding indexed column(s), and the value is a pointer to the relevant row(s) in the table.
To get the most out of your database, you should use the right index type for the job.
🔶 B-tree - one of the most commonly used indexing structures where keys are hierarchically sorted.
🔶 Hash index - best used when you are searching for an exact value match. The key component of a hash index is the hash function.
🔶 Bitmap Index - very effective in handling complex queries where multiple columns are used.
🔶 Composite Index - may be used when multiple columns are often used in a WHERE clause together.
Indexing can be a double-edged sword. It significantly speeds up queries, but it also takes up storage space and adds overhead to operations.
Load Balancer vs Reverse Proxy (Recap)
Load balancers are concerned with routing client requests across multiple servers to distribute load and prevent bottlenecks. This helps maximize throughput, reduce response time, and optimize resource use.
A reverse proxy is a server that sits between external clients and internal applications. While reverse proxies can distribute load as a load balancer would, they provide advanced features like SSL termination, caching, and security. Reverse proxies are more concerned with limiting and safeguarding server access.
Whilst load balancers and reverse proxies possess distinct functionalities, in practice the lines can blur, as many tools act as both a load balancer and reverse proxy.

Data Structures Real-world Examples
Data structures are the building blocks of software, helping to organize and store information efficiently. They are not just theoretical concepts; they are used in many applications that we interact with daily. Understanding how and where to use these data structures is a fundamental skill for any software engineer to create effective and efficient solutions.
Below are some examples:
🔷 List: Online shopping cart — an ordered collection of items with the ability to access items at specific positions.
🔷 Linked List: Browser history — enables quick and efficient traversal backward and forward through the history.
🔷 Hash Table: Caching — Many caching algorithms, like in web browsers and content delivery systems, use hash tables to quickly look up values based on a key.
🔷 Stack: Undo functionality — Last In, First Out (LIFO) the last element added is the first one to be removed.
🔷 Queue: Printer queue — follows the First In, First Out (FIFO) principle, print jobs are processed in the order they are received.
🔷 Graph: Social media network — helps in suggesting new friends, finding mutual connections, and disseminating posts through the network.
🔷 Matrix: Pathfinding — utilizes a two-dimensional array to represent a grid and determine the shortest path from one point to another.
🔷 Tree: File system — trees are hierarchical in nature, mirroring the organizational structure of directories and subdirectories. Many file systems are represented as trees with directories as nodes.
🔷 Heap: Priority queue — efficiently ensures that the element with the highest priority is always readily accessible.

That wraps up this week’s issue of Level Up Coding’s newsletter!
Join us again next week where we’ll explore how SSO works, caching strategies, and the main components of Docker.