


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Presented by Postman
📣 Postman has a special online event. They’re showing how to build APIs visually. Secure your seat before they run out.
Presented by Kickresume
Crafting a great resume is challenging, Kickresume makes it easy and quick. Five million successful job seekers can’t be wrong.
ELT Demystified: From Raw Data to Powerful Insights
“Data is the new oil” — Clive Humby
This has become a common saying in modern times and is particularly relevant in the context of tech-driven businesses.
Data management and business intelligence are growing fields that have huge impacts on businesses. Being able to leverage insights from data helps move companies away from bad decisions and towards good or profitable decisions.
And that’s where the ELT process comes into play.
The ELT process is fundamental in structuring a data pipeline that enables businesses to harvest diverse data, load it into storage, and transform it in-place for insightful analysis.
As software engineers in a data-driven world, understanding the nuances of ELT is not just beneficial but essential for architecting scalable and efficient data systems. This guide breaks down ELT.
The Components of ELT
Extract
Extraction is the critical first step in the ELT process, involving pulling data from various sources.
This step determines the quality and scope of the data available for analysis.
Common data sources include databases, APIs, flat files, and third-party systems.
The diversity of sources introduces complexity, but it also enriches the data.
Some of the key challenges at this initial phase include ensuring data quality, handling large volumes efficiently, and dealing with diverse data formats.
Load
In the loading phase, raw data is stored in a data warehouse, typically a cloud-based solution such as Snowflake, Google BigQuery, or AWS Redshift.
The major shift from traditional ETL is that, in ELT, data is loaded into the warehouse first, without transformations. This allows us to preserve raw data and gain flexibility in when and how transformations are applied. This enables downstream use cases like historical comparisons, machine learning feature extraction, and more.
During loading, schema management and partitioning strategies should be considered to ensure the data warehouse is optimized for query performance and scalability.
Monitoring data ingestion performance and resource utilization is key to keeping costs predictable in cloud environments.
Transform
In the final phase, data is transformed using the high-performance computing power of modern data warehouses, which can process large volumes of data in place.
Transformations include not only data cleaning but also more complex operations like:
Data aggregation: summarizing data, such as calculating totals or averages across datasets.
Normalization/denormalization: restructuring data for analytical use, depending on the query needs.
Feature engineering: creating new features from existing data for machine learning models.
Business logic application: applying business-specific rules or calculations to the data (e.g., categorizing customer segments).
SQL and proprietary transformation tools within the warehouse are used to handle these operations efficiently.
With modern cloud-based data warehouses, the flexibility to transform data post-loading supports different analytical workloads—such as batch processing, real-time analytics, or machine learning pipelines.
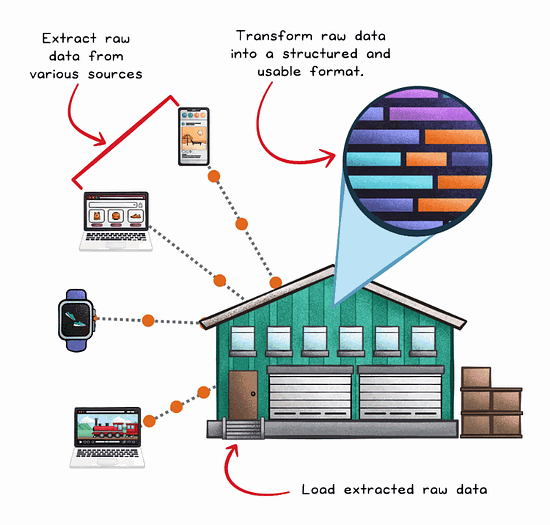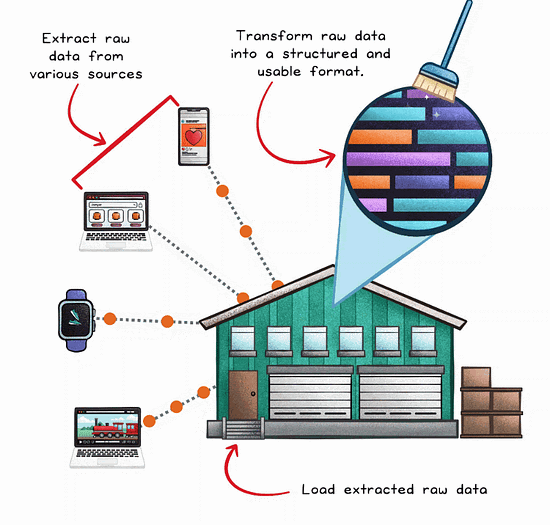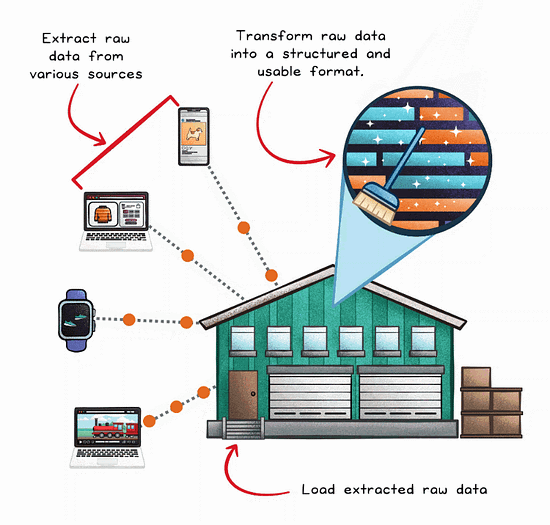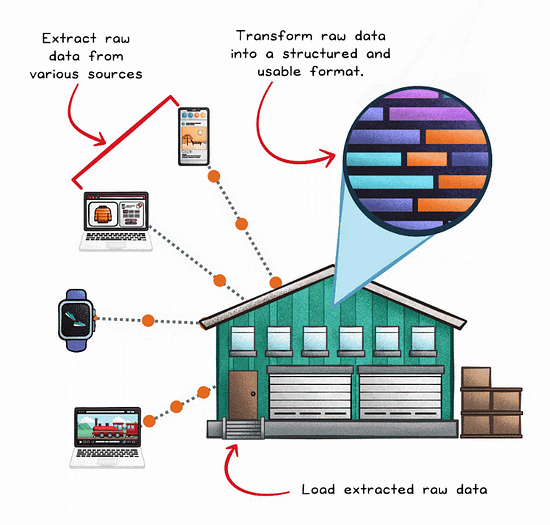
The ELT Process Flow
ELT decouples the transformation process from the extraction and loading stages.
By decoupling transformations from extraction and loading, ELT allows organizations to scale their pipelines more effectively, adapting to changes in requirements without reloading or reprocessing data unnecessarily.
For example, a company analyzing customer buying patterns might consolidate sales data from multiple channels using ELT. The disparate raw data is extracted and loaded into the data warehouse. When analysis is required, transformations, such as aggregating total sales per customer or creating customer segments, are performed to prepare and enrich the data for the specific use case. This flexibility allows us to run transformations tailored to the business needs without altering the original data.
ELT Tools and Technologies
ELT benefits from a wide array of tools and technologies, with cloud-based platforms like Snowflake, AWS Redshift, and Google BigQuery leading the way.
These tools excel at handling large volumes of data and performing in-warehouse transformations at scale.
They leverage the elastic nature of cloud infrastructure, enabling businesses to scale resources on demand and store vast amounts of raw data cost-effectively.
With built-in support for parallel processing, they optimize performance for large-scale transformations, such as batch processing or real-time analytics.
Selecting the right tool requires balancing considerations like data security, transformation speed, integration with existing systems, and cloud infrastructure costs. We also need to evaluate specific warehouse features, such as auto-scaling, clustering, and query optimization, to ensure that the platform can meet their data processing needs efficiently.
Best Practices in ELT
Ensuring data quality from the start is paramount. This involves not just validation during extraction and loading but also building mechanisms that catch issues early during transformations. Consider implementing data profiling tools to detect anomalies and outliers before the transformation phase.
Performance optimization is crucial, especially when working with large datasets. This might involve optimizing SQL queries, effectively managing resources like compute nodes, and using parallel processing and partitioning strategies to handle data transformations efficiently.
Security considerations are also essential. Employ robust measures such as data encryption (both in transit and at rest), access controls, and secure connections. Consider adopting role-based access control (RBAC) to ensure that only authorized users have access to sensitive data.
Regular testing and validation of the ELT pipeline is critical. Automated testing ensures that transformations work correctly and meet data quality standards. Tools like DBT can help by running checks on transformed data and ensuring that all assumptions and business logic are valid.
Wrapping Up
In the information age, data is opportunity.
ELT is a pivotal process for harnessing data.
By understanding and implementing a well-orchestrated ELT process, engineers can empower businesses to make confident, data-driven decisions.
Investing time and resources in properly planning and implementing ELT processes is crucial, as a well-executed strategy not only enhances data handling but also provides a solid foundation for future growth and adaptation.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: