
Architecting High-Throughput Real-Time Data Pipelines
(5 Minutes) | Break Into Real-Time Data Pipelines


Get our Architecture Patterns Playbook for FREE on newsletter signup:
Presented by Kestra

Kestra is an open-source orchestration tool that we've used and loved. And now there's a new release that makes it even more AI and automation-friendly.
New No-Code experience for easier workflow creation, empowering even non-coders to build sophisticated pipelines.
Streamlined log management via the Log Shipper to optimize your AI/ML workflows.
Plug-ins from HuggingFace and AWS that incorporate LLM-based capabilities into your Kestra workflows.
Check out these updates and more in this detailed blog release from Kestra.
Architecting High-Throughput Real-Time Data Pipelines
From improving user experience to business intelligence, through to self-driving vehicles, and everything in between. The rewards and needs for harnessing data in real-time continue to grow.
The solution? Real-time data pipelines.
But architecting them is no easy feat.
It’s a complex, evolving, and rewarding engineering challenge that will continue to grow in demand as the world continues to demand real-time functionality.
Let’s dive in!
Understanding Real-time Data Pipelines
Real-time data pipelines are systems designed to ingest, process, and analyze data instantaneously.
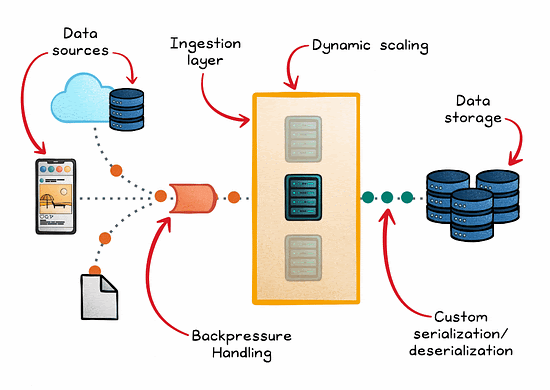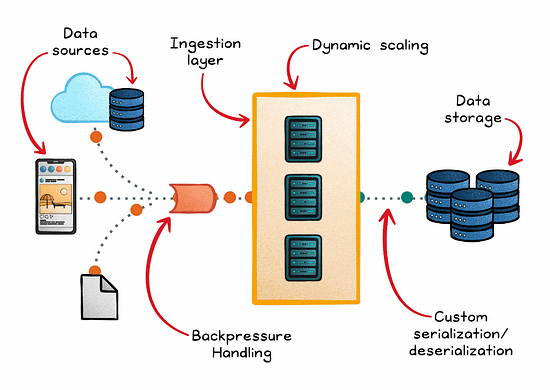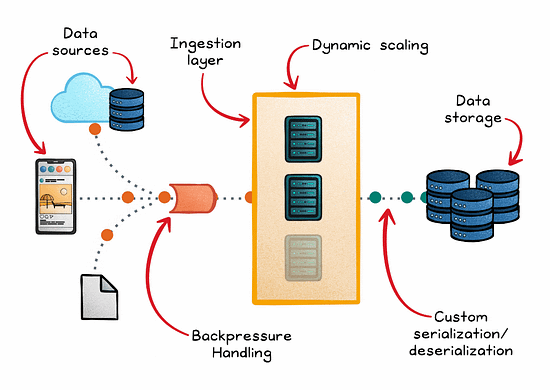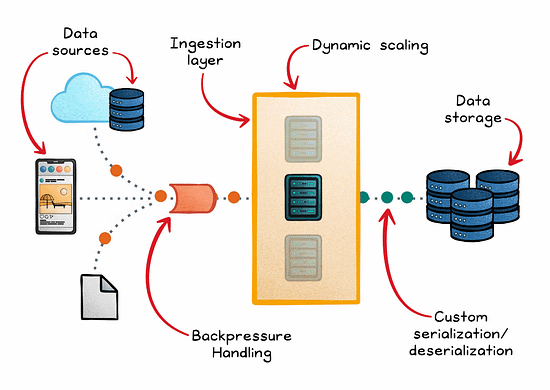
These pipelines consist of several key components:
Data sources where information originates
Ingestion engines that capture and transport the data
Stream processors that analyze the data in real time
Storage systems where the processed data is held for subsequent use or analysis
Real-time pipelines are perfect for scenarios that demand quick decision-making and responsiveness.
Advanced Concepts in Real-time Data Pipelines
As data volume and velocity increase, systems must be designed for both speed and dependability to provide accurate real-time analysis.
Accurate real-time analytics require an understanding of the distinction between event time (when an event actually occurs) and processing time (when the system processes it).
Modern frameworks like Apache Flink use watermarks to track event time in out-of-order data streams, improving accuracy.
Managing backpressure is also critical in preventing system overloads when processing rates slow down. In addition to rate limiting and load shedding, buffering strategies (such as Kafka partitions) and reactive systems like Akka Streams can help handle surges.
The choice between exactly-once semantics and at-least-once delivery has profound implications for system design and reliability.
Exactly-once semantics ensure that each data element is processed a single time, eliminating the risks of duplication.
In contrast, at-least-once delivery guarantees that no data is lost but may lead to processing the same data multiple times, potentially creating duplicates.
Checkpointing and idempotent writes can help enforce exactly-once semantics in stream processing frameworks.
Balancing these trade-offs is key for designing systems that not only meet the immediate analytical needs but also adhere to long-term reliability and accuracy standards.
Challenges in Scaling High-Throughput Systems
Scaling high-throughput real-time systems presents a unique set of challenges.
Systems may be strained by the sheer velocity, volume, variety, and variations of data (the four Vs). Therefore, robust solutions are needed to maintain speed, reliability, and maintainability.
Central to these challenges is state management.
As systems scale and data continuously flows, managing changing state without hampering performance is crucial.
It's a complex task to maintain an accurate, consistent state across a distributed system, yet it's essential for ensuring real-time responses remain relevant and correct.
Dynamic load balancing is a key consideration. Adjusting resource allocation in real-time to meet fluctuating demands and prevent any single node from becoming a bottleneck requires sophisticated strategies. Techniques like sharding, partitioning, and Kubernetes-based autoscaling help distribute workloads efficiently.
Since real-time systems are often deployed in distributed environments, fault tolerance and fast failure recovery are critical attributes.
Fault tolerance ensures the system keeps running even when parts fail. Techniques like leader election and self-healing clusters improve resilience.
Fast failure recovery minimizes downtime and restores the system quickly. State snapshots in Apache Flink and replay mechanisms in Kafka help achieve this.
Comparative Analysis of Data Processing Frameworks
Selecting an appropriate framework is very important for enhancing both the performance and dependability of your data pipeline.
Apache Kafka is best for log aggregation and event streaming. Kafka Streams and ksqlDB add real-time transformation capabilities.
Apache Pulsar is high-throughput like Kafka, but with tiered storage and multi-tenancy support, making it ideal for complex distributed systems.
Apache Flink stands out for event-time processing and stateful analytics. Offers robust exactly-once semantics and checkpointing for mission-critical workloads.
The above is simply a brief comparison of the open-source Apache suite. There are many other technology options available.
What is important is understanding the trade-offs and matching the framework to your specific needs to build an efficient and scalable real-time data pipeline.
Optimization Techniques for Peak Performance
Optimizing for high throughput requires a multifaceted approach.
One essential technique is dynamic scaling, which automatically adjusts computing resources in response to real-time demand. This ensures the system remains efficient under varying loads.
Efficient memory management, including garbage collection tuning in JVM-based systems like Kafka and Flink, helps prevent performance bottlenecks.
Additionally, custom serialization/deserialization methods streamline data handling, significantly speeding up transmission and processing.
Employing these advanced techniques effectively streamlines operations, significantly boosting performance and system resilience.
Emerging Technologies and Future Directions
The landscape of real-time data processing is continually evolving.
Edge computing is revolutionizing data processing capabilities by bringing computation closer to the data source, drastically reducing latency.
Serverless architectures are also transforming the scene by enabling more agile and cost-effective scaling of data processing resources.
AI and machine learning are automating and refining real-time analytics, making data processing systems more responsive and intelligent.
Wrapping it Up
Architecting high-throughput real-time data pipelines is a complex yet rewarding challenge.
It requires a deep understanding of the theoretical aspects, a strong understanding of system requirements, and practical considerations of modern data processing technologies.
Building and maintaining data pipelines is only likely to become more common in the future as the demand for real-time functionality for businesses and products continues to grow.
Knowing how data pipelines work, understanding key considerations for designing them, and being able to recognize and translate how they tie into business solutions is often a valuable skill for an engineer depending on their role.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: