
Design for Failure: What Every Engineer Should Know About Circuit Breakers
(3 Minutes) | How to Engineer Systems That Fail Gracefully, Not Catastrophically


Every PagerDuty Paid Plan Now Includes Full Incident Management
Presented by PagerDuty
Most teams fix incidents. The best teams learn from them.
I’ve worked with teams that resolved incidents in minutes, then made the same mistake a month later. Most teams are great at fixing things, but terrible at learning from them.
Why? Because their post-incident reflection was broken. Either post-incident reviews never happened, or they happened too late, with documentation scattered across 17 different Slack threads, and no follow-through.
The best-in-class way to go about this is to use a comprehensive incident management tool like PagerDuty. Their AI-powered post-incident reviews make learning from incidents much easier.
Design for Failure: Understanding the Circuit Breaker Pattern
In distributed systems, failure is not a rare event—it’s inevitable.
The Circuit Breaker Pattern is one of the most effective tools for building systems that degrade gracefully instead of collapsing under pressure.
Inspired by electrical circuit breakers, this design pattern acts as a safeguard between services.
When a dependent service becomes unstable due to timeouts, exceptions, or latency spikes, the circuit breaker “trips,” preventing further calls and allowing the system to recover before failures cascade.
Why It Matters
In a microservices architecture, a single failing service can trigger a full-system outage. The circuit breaker addresses this by isolating failures, keeping the rest of your system responsive.
Imagine a checkout service relying on a third-party payment gateway.
Without a circuit breaker, threads pile up, queues overflow, and your entire service grinds to a halt.
With a circuit breaker, the system detects repeated failures, trips the breaker, and returns fallback responses, preventing a local issue from becoming a system-wide failure.
How It Works: The Three States
The circuit breaker operates as a three-state model:
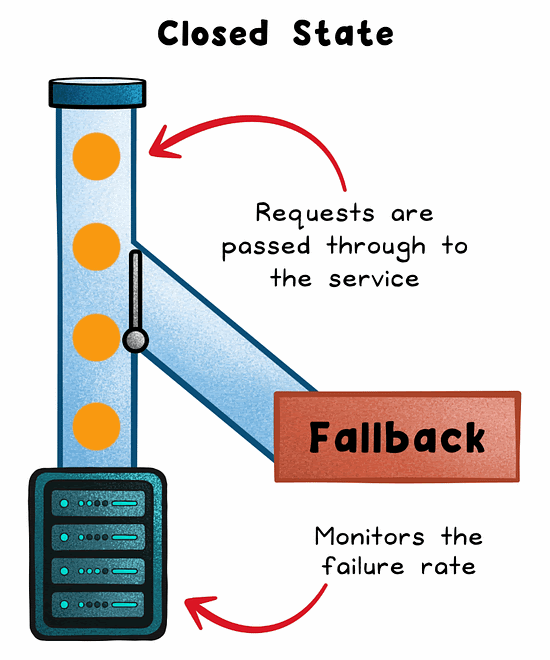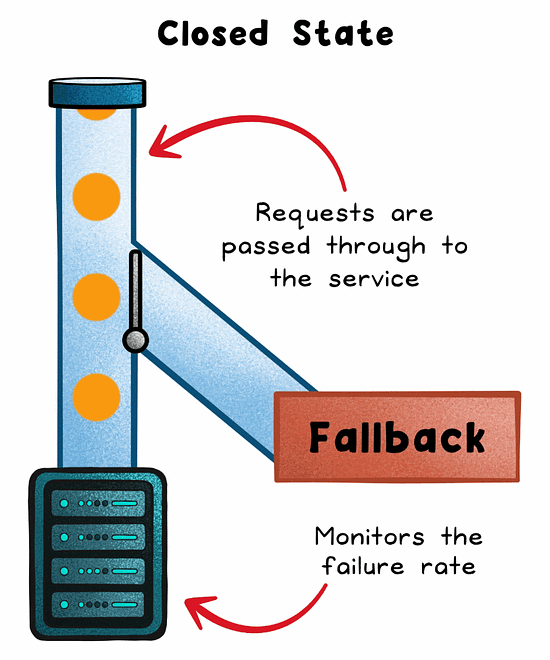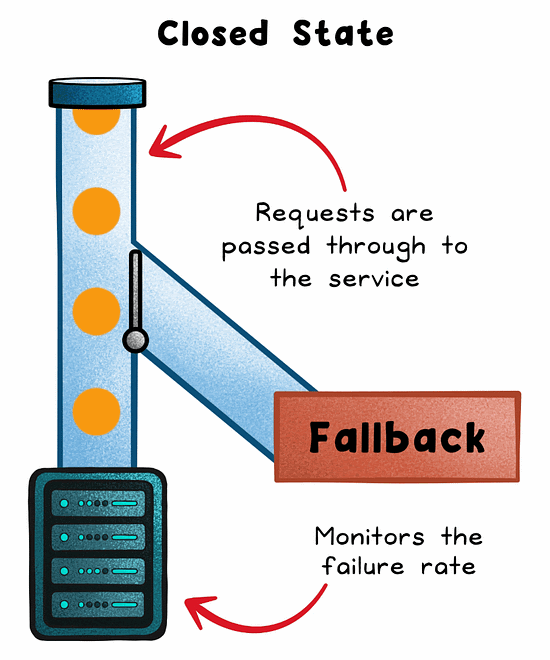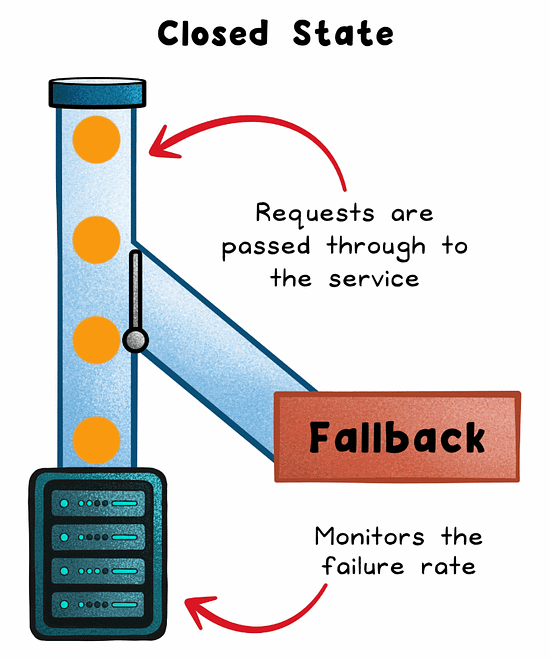
Closed
Normal operation. All requests pass through and failures are monitored.
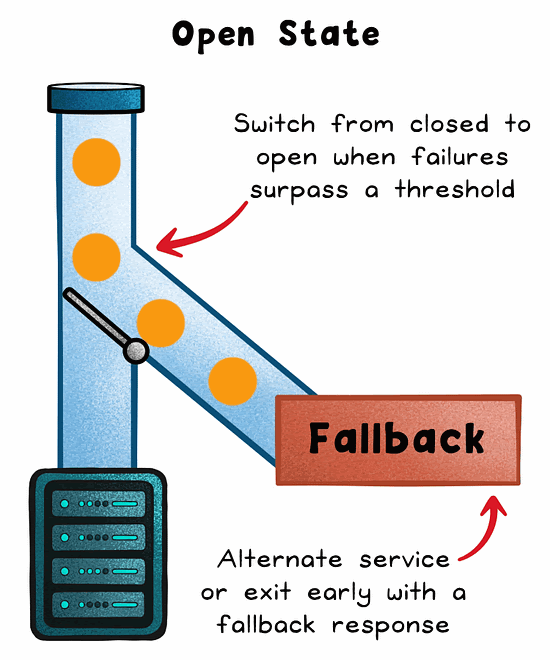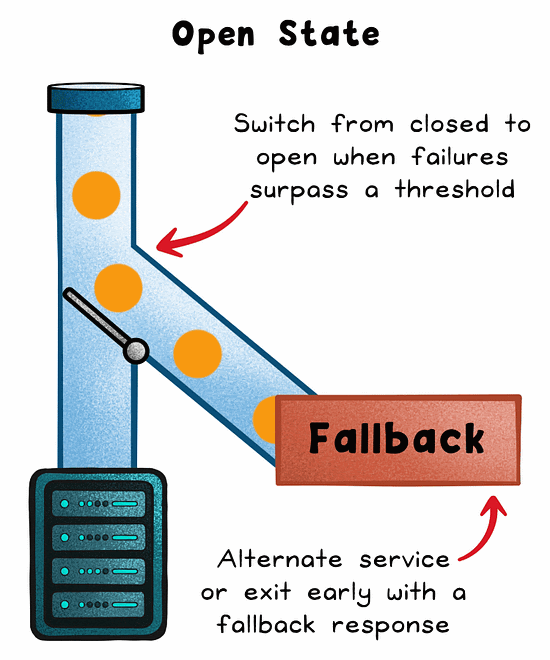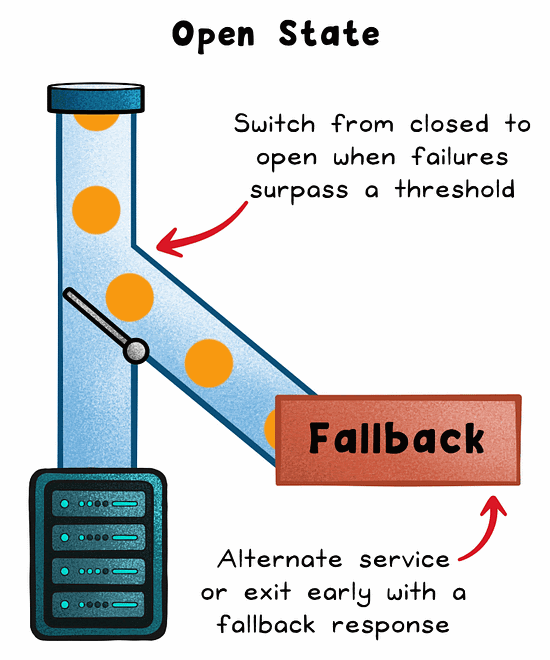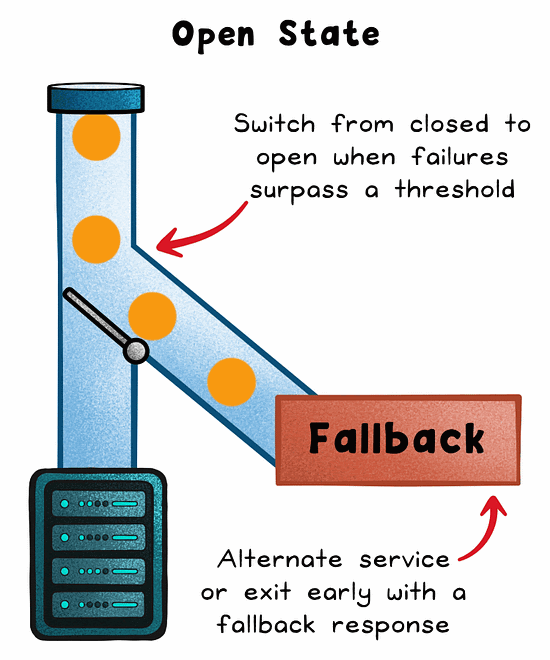
Open
When failures exceed a threshold, the circuit trips. No requests are forwarded to the failing service. The system returns a fallback or error immediately.
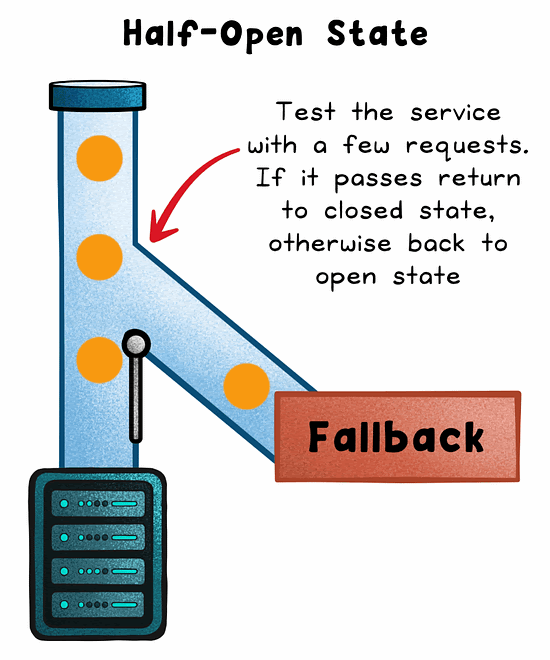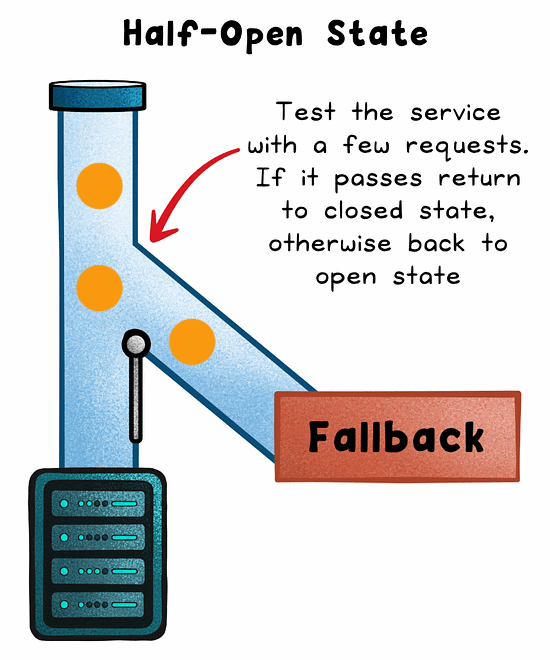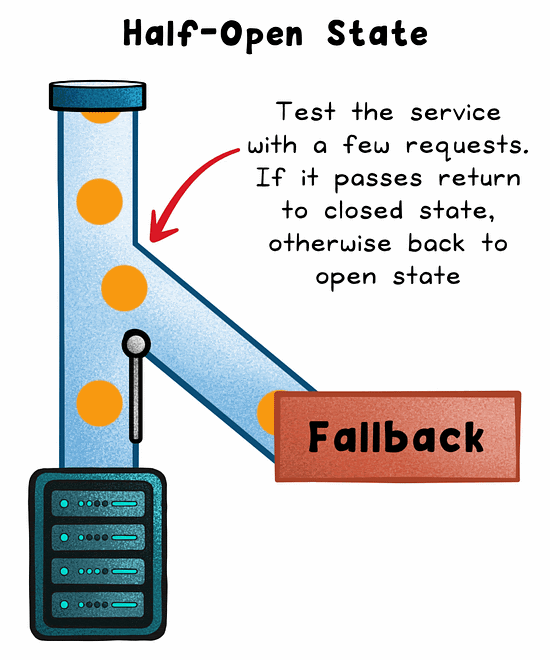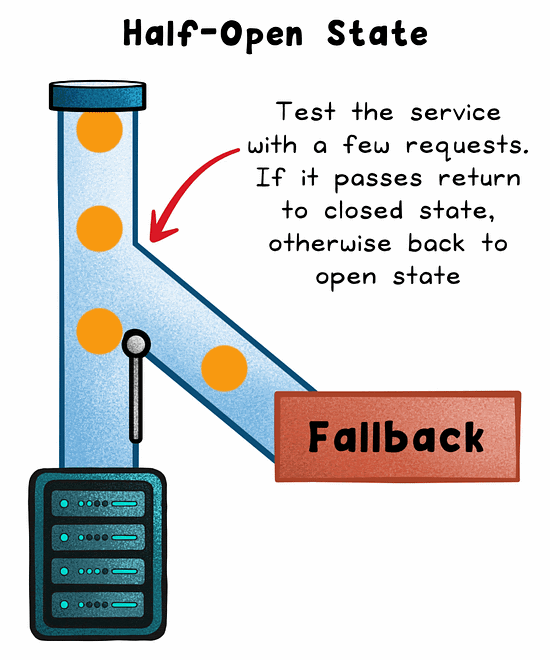
Half-Open
After a cool-down period, a few trial requests are allowed through. If they succeed, the circuit closes. If not, it reopens.
This model helps prevent retry storms, thread exhaustion, and resource contention. All of which can amplify failure instead of containing it.
Best Practices for Implementation
To implement circuit breakers effectively:
Set failure thresholds carefully – Tune based on real traffic patterns and error rates.
Use exponential backoff with jitter – Avoid flooding the recovering service with synchronized retries.
Design meaningful fallbacks – Whether it’s cached data or degraded functionality, the goal is graceful degradation.
Monitor and alert – Instrument your circuit breakers. A circuit that stays open for too long signals a persistent issue.
Be selective – Not every service needs a circuit breaker. Use them for critical dependencies that could impact system-wide reliability.
Configure thresholds thoughtfully – Setting them too low can cause the circuit to trip unnecessarily, cutting off healthy services and introducing more instability.
Popular tools include Polly (.NET), Resilience4j (Java), and Istio for service-level circuit breaking in cloud-native environments.
Final Takeaway
The circuit breaker pattern isn’t just about avoiding outages. It’s about designing with failure in mind.
By containing failure instead of letting it spread, it helps systems recover faster, stay available longer, and earn user trust, even when things go wrong.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: