
Redis Clearly Explained
How Redis works under the hood, where it fits in the stack, where it shines, and when NOT to use it.


Just a Computer. On the Internet. Instantly.
Presented by exe.dev
Sometimes you just need a machine on the internet. One that keeps running when your laptop sleeps, runs your cron jobs, and is accessible when others need it. Exe.dev gives you exactly that. A real VM with persistent disk, built-in HTTPS, and secure access out of the box. No auth setup, no config files, no infrastructure overhead. Spin one up with a single command and start building. It stays live and ready to share.
Redis Clearly Explained
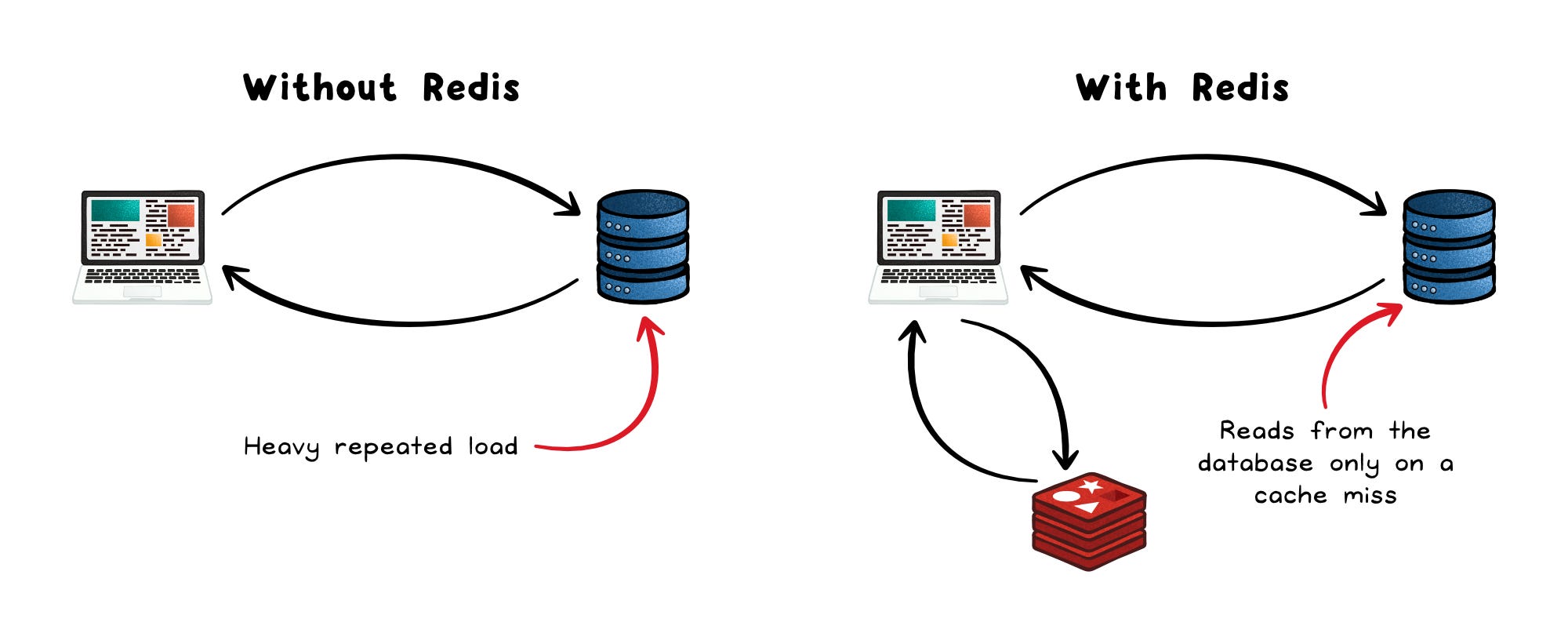
Your database is fast. Your queries are optimized. Your indexes are in place. And yet, under real load, the system still slows down.
The problem often isn’t the database itself. It’s that you’re asking it to answer the same questions, over and over, thousands of times a second.
This is where Redis starts to matter.
It shows up at the edge: handling sessions, caching responses, tracking limits, moving messages. Quietly taking pressure off everything else.
How Redis works under the hood
Redis stores everything in RAM as key–value pairs, but the values are not limited to plain strings. It supports a rich set of data structures:
Strings → Simple values; used for counters, flags, and cached results.
Hashes → Field-value maps; ideal for user profiles and session data.
Lists → Ordered sequences; used for queues and recent activity feeds.
Sets / Sorted Sets → Unique element collections with optional scoring; used for leaderboards and tag systems.
Each structure comes with optimized commands. Instead of fetching data and processing it in your app, Redis lets you operate directly on the data.
That’s the difference between:
“Get everything, then sort it”
vs“Ask Redis for the top 10 directly”
Execution model
Redis uses a single-threaded event loop, meaning one command executes at a time.
This sounds limiting, but it avoids locking and keeps operations atomic. In practice, it handles massive throughput because the work per operation is small and predictable.
Persistence (optional but important)
Even though Redis is in-memory, it can persist data:
RDB snapshots → Periodic full saves
AOF logs → Append every write operation
You choose how durable you want it to be. Faster setups risk losing recent data; safer setups add overhead.
Where Redis actually shines
Redis is not a general-purpose database replacement. It’s a performance layer that solves specific problems extremely well.
1. Caching
The most common use case is caching expensive reads.
The application checks Redis first; on a hit, data returns in microseconds; on a miss, the app queries the primary database and populates Redis for next time.
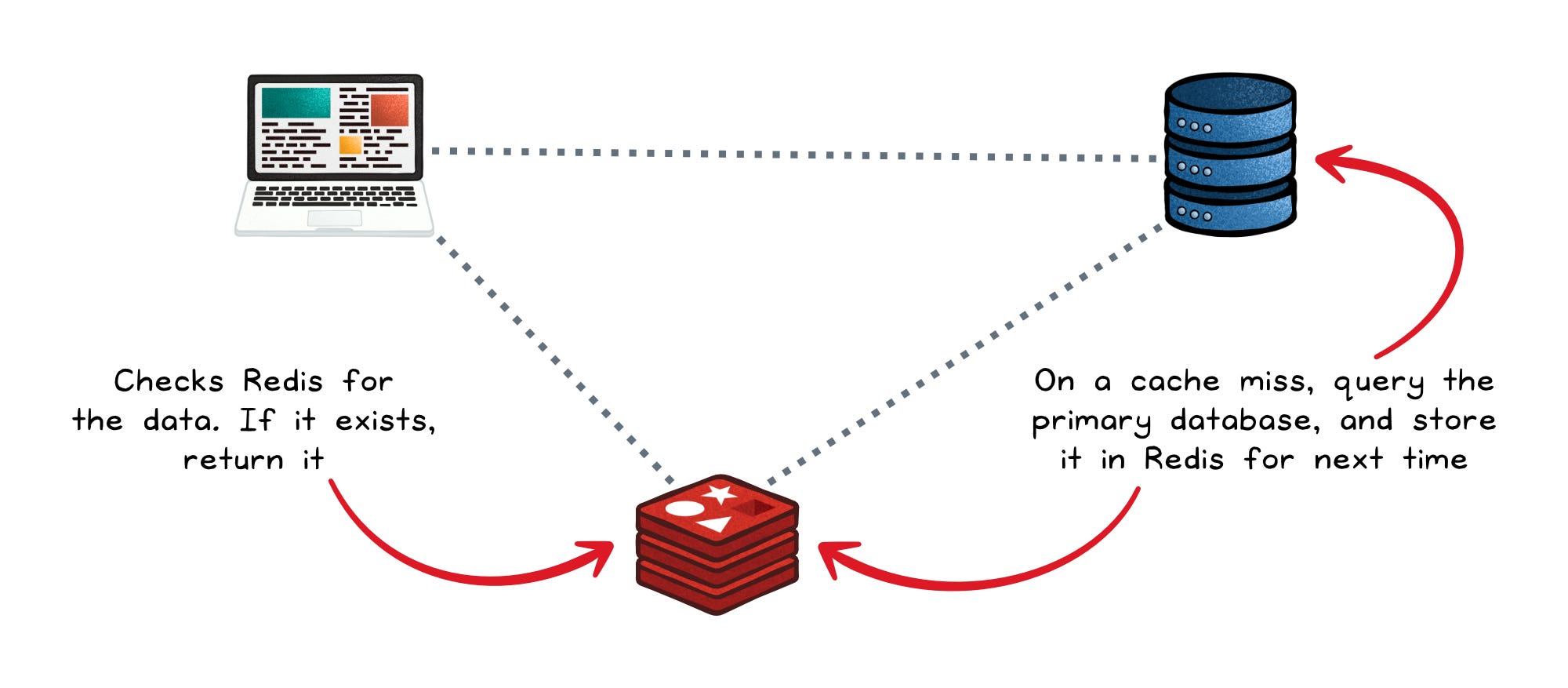
The primary database stays as the source of truth, Redis handles the hot path.
This works especially well for expensive query results, API responses, rendered HTML fragments, or any data that is read far more often than it changes.
Faster responses → Microseconds instead of milliseconds
Lower DB load → Fewer repeated queries
Better scalability → Handles spikes smoothly
This pattern alone can reduce database traffic dramatically.
2. Session storage
User sessions need fast reads and writes across every request.
Redis fits because:
Low latency → No delay on every request
Time-to-live support → Sessions expire automatically
High throughput → Handles large user bases
Instead of storing sessions in a database, Redis keeps them close to the application.
3. Rate limiting
Redis makes rate limiting simple through atomic operations.
Each request increments a counter per user, there’s a set expiration per counter (e.g. 10 minutes), requests are rejected after a threshold is reached.
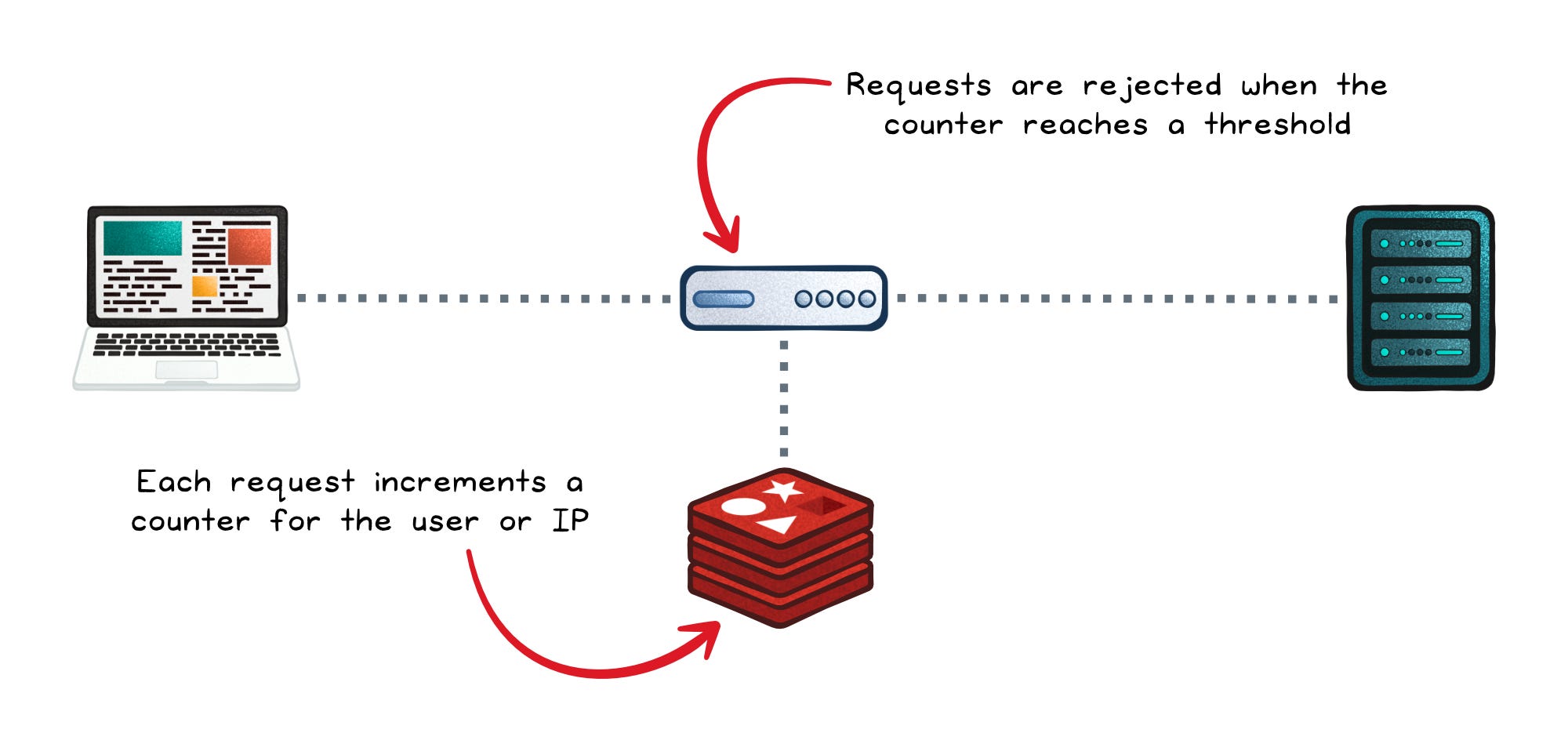
Because these are atomic in-memory operations, they add almost no overhead to the request path. This is why Redis is often used behind API gateways.
4. Pub/Sub and queues
Redis has a built-in publish/subscribe mechanism: one service publishes to a channel; all subscribers receive the message in real time.
For more durable workloads, Redis Lists support simple FIFO queues, and Redis Streams add consumer groups and persistence for cases where message durability matters.
It’s simple, fast, and good enough for many workloads before you need heavier tools.
Benefits vs trade-offs
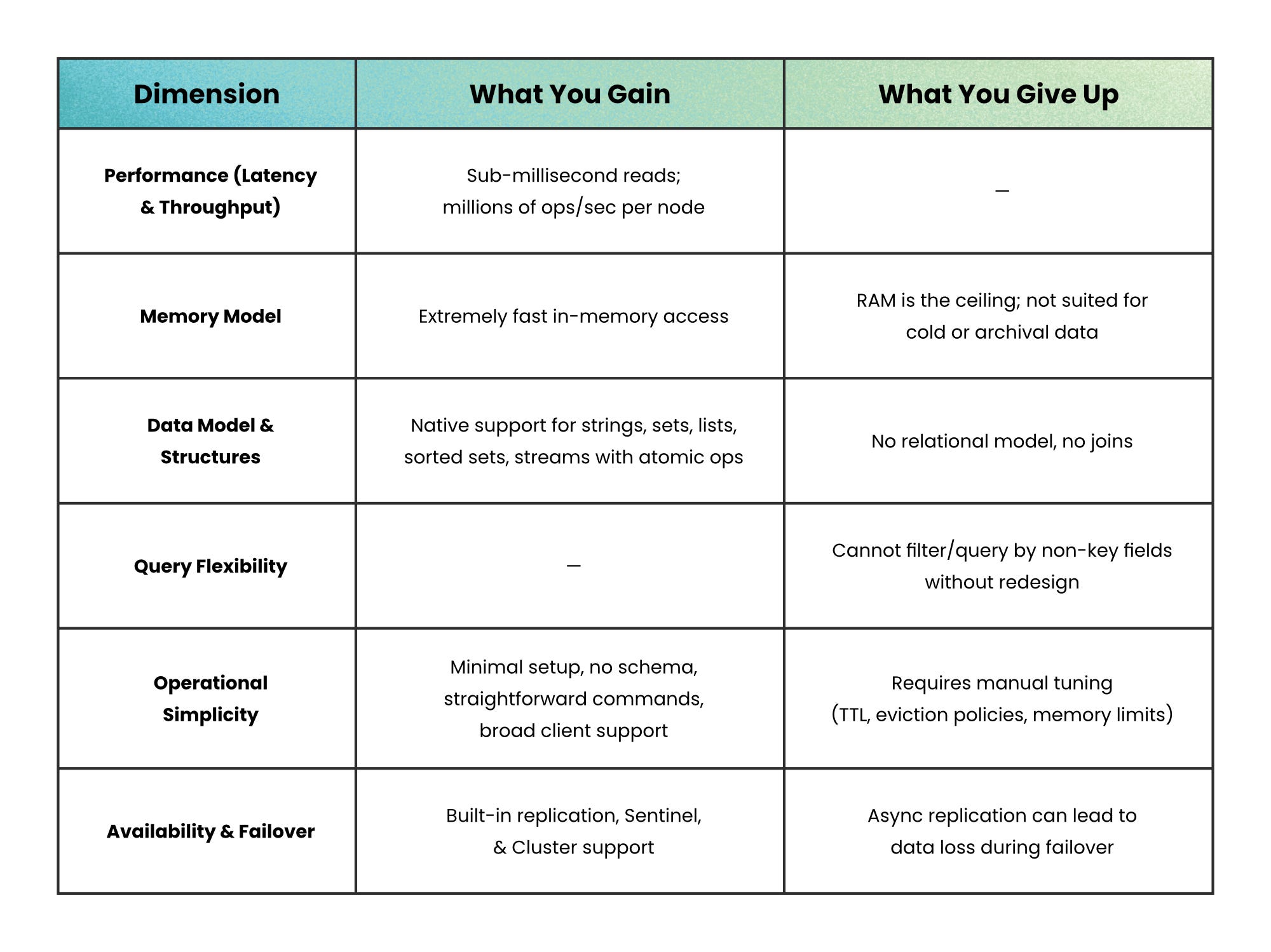
Where Redis fits in the stack
Redis complements a primary database.
In microservices architectures, Redis plays a second role as a shared fast datastore: a central session store that all frontends hit, a rate limiter that all API gateways respect, or a lightweight message broker that connects services without the overhead of a full queue system like Kafka or RabbitMQ.
Cloud providers offer managed Redis services (AWS ElastiCache, Azure Cache for Redis, and Google Cloud Memorystore) that handle provisioning, scaling, and failover automatically. This makes slotting Redis into an existing stack straightforward, without managing infrastructure directly.
When not to use Redis
Redis is not the right tool when:
Your dataset is large and cold → RAM is expensive per GB. Storing a 10TB archive in Redis would cost a fortune. Use a disk-based store and cache only the hot subset in Redis.
You need complex queries → “Find all users from Region A who purchased Product B in the last 30 days” requires a relational database. Redis retrieves by key; it does not scan or join.
You need strong durability → If losing even a few seconds of writes is unacceptable (financial transactions, medical records), Redis’s persistence model needs careful configuration, and a fully ACID-compliant database is the safer option.
Your workload is stateless and simple → For systems that don’t cache, don’t need sessions, and don’t need messaging, adding Redis introduces operational complexity without a proportional benefit.
The takeaway
Redis is best understood as a performance multiplier, not a database replacement.
It doesn’t try to solve everything. It solves a narrow set of problems extremely well: caching, sessions, rate limiting, lightweight messaging.
And that’s exactly why it’s everywhere.
Used correctly, Redis turns slow paths into fast ones and fragile systems into responsive ones.
Used blindly, it becomes an expensive, leaky abstraction.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
where is the book?
Straight to the point