
REST APIs Properly Explained
(4 minutes) | Constraints, trade-offs, when not to use it, and more


Unblocked: Context That Saves You Time and Tokens
Presented by Unblocked
Stop babysitting your coding agents. Unblocked gives them the organizational knowledge to generate mergeable code without the back and forth. It pulls context from across your engineering stack, resolves conflicts, and cuts the rework cycle by delivering only what agents need for the task at hand.
REST APIs Principles Explained Clearly
What makes an API RESTful?
If your first thought is “resources and CRUD,” you’re missing half the picture.
REST is an architectural style with specific constraints, and most APIs only follow a subset. Knowing the full model helps you design better interfaces; and know when to choose something else.
What is REST
REST (Representational State Transfer) is an architectural style for distributed systems. It’s not a protocol, not “just JSON,” and not a synonym for “HTTP API.”
To be truly RESTful, a system follows six constraints:
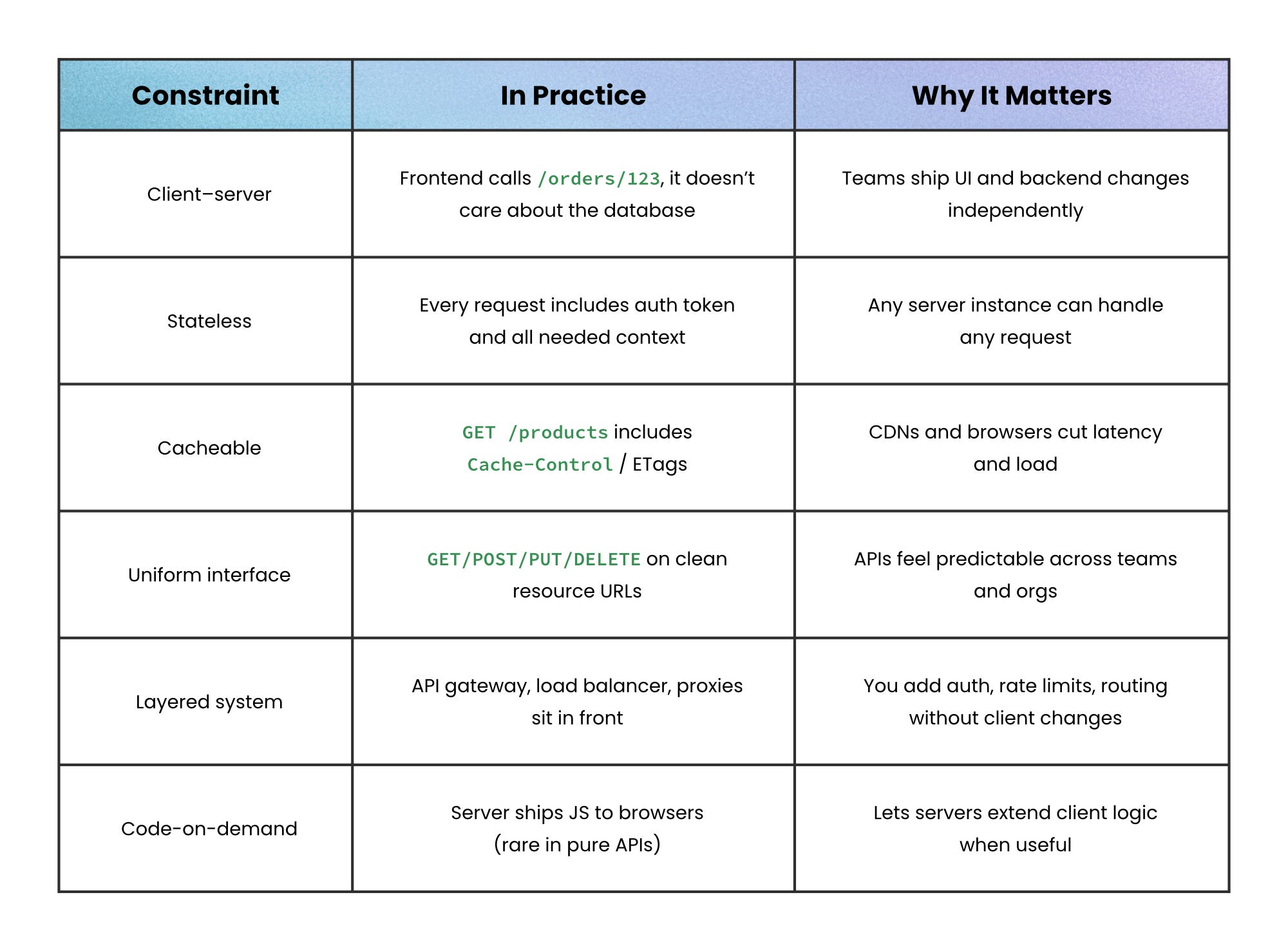
Client–server separation → UI and data/service concerns are split so each can evolve independently
Stateless interactions → Every request carries the full context; the server stores no client session
Cacheable responses → Responses say whether they can be cached, so intermediaries can safely reuse them
Uniform interface → Resources have URIs; standard HTTP methods and status codes describe operations. In strict REST, the interface is also driven by hypermedia (HATEOAS), though most APIs don’t fully implement this.
Layered system → Clients can’t tell if they talk to the origin server, a gateway, or a proxy in the middle
Code-on-demand (optional) → Servers may send executable code (like JS) to extend client behavior
These rules sound theoretical, but they explain why REST scales, why it’s easy to debug, and why you can throw a CDN or API gateway in front without rewriting your app.
The REST constraints, de-jargoned
Here’s how the core constraints translate into day-to-day API design:
Think of REST as the web’s “grammar” for talking about resources. Once you learn it for one API, others feel familiar because they follow the same structure.
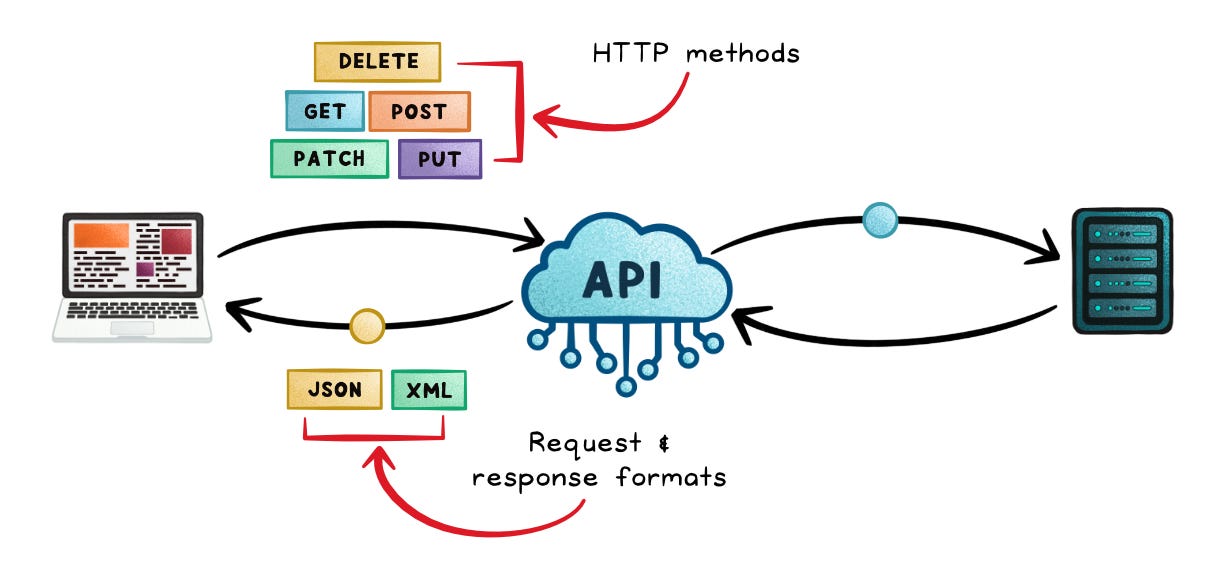
How a REST API actually works
A REST API is basically: resources + URIs + HTTP semantics.
Resources → Domain nouns like
users,orders,products,employeesURIs → Stable paths:
/products,/products/42,/customers/123/ordersMethods → Map closely to CRUD:
GET→ ReadPOST→ CreatePUT/PATCH→ UpdateDELETE→ Remove
Add to that:
Representations → Usually JSON documents that describe the resource state
Status codes → Shared language for outcomes (
200 OK,201 Created,404 Not Found,500 Internal Server Error)Caching →
GETendpoints designed to be safely cached at browser, proxy, or CDN layers
For example: in an e-commerce API, GET /products lists items, GET /products/123 shows one product, POST /orders creates an order, and GET /customers/123/orders lists a customer’s history. Internally, the server can switch databases or split into microservices, but as long as those URIs and contracts stay stable, clients don’t care.
Why REST became the default
REST won not because it’s perfect, but because the trade-offs line up well with how most applications work.
Simple to learn → You can poke at a REST API with a browser or
curlbecause it’s just HTTPInteroperable → Any language, framework, or device that can speak HTTP can be a client
Scalable → Stateless servers are easy to scale horizontally behind a load balancer
Fast enough → Built-in HTTP caching plus lightweight JSON is plenty for most CRUD-style workloads
Decoupled → Backend teams can refactor internals or swap infrastructure without breaking clients
Great tooling → OpenAPI, Postman, language SDK generators, gateways, and observability stacks all “speak REST”
If your domain is resource-centric (products, posts, users, tickets) and most operations are CRUD-ish, REST is usually the path of least resistance.
Where REST starts to creak
REST’s weaknesses show up once your data needs get more complex or more demanding than “list + detail”:
Over-fetching → Clients get big objects when they only needed a few fields
Under-fetching → Clients chain multiple calls (
user, thenorders, thenrecommendations) to render one screenChattiness → Many small HTTP requests stack up latency, especially on mobile networks
Loose contracts → JSON shapes are enforced by convention and docs, not by the protocol itself
Versioning pain → Breaking changes often mean
/v2endpoints or awkward backwards compatibilityReal-time gaps → REST is request–response; you need WebSockets or SSE for live updates
These aren’t fatal flaws, but they’re signals that you might need something in addition to REST.
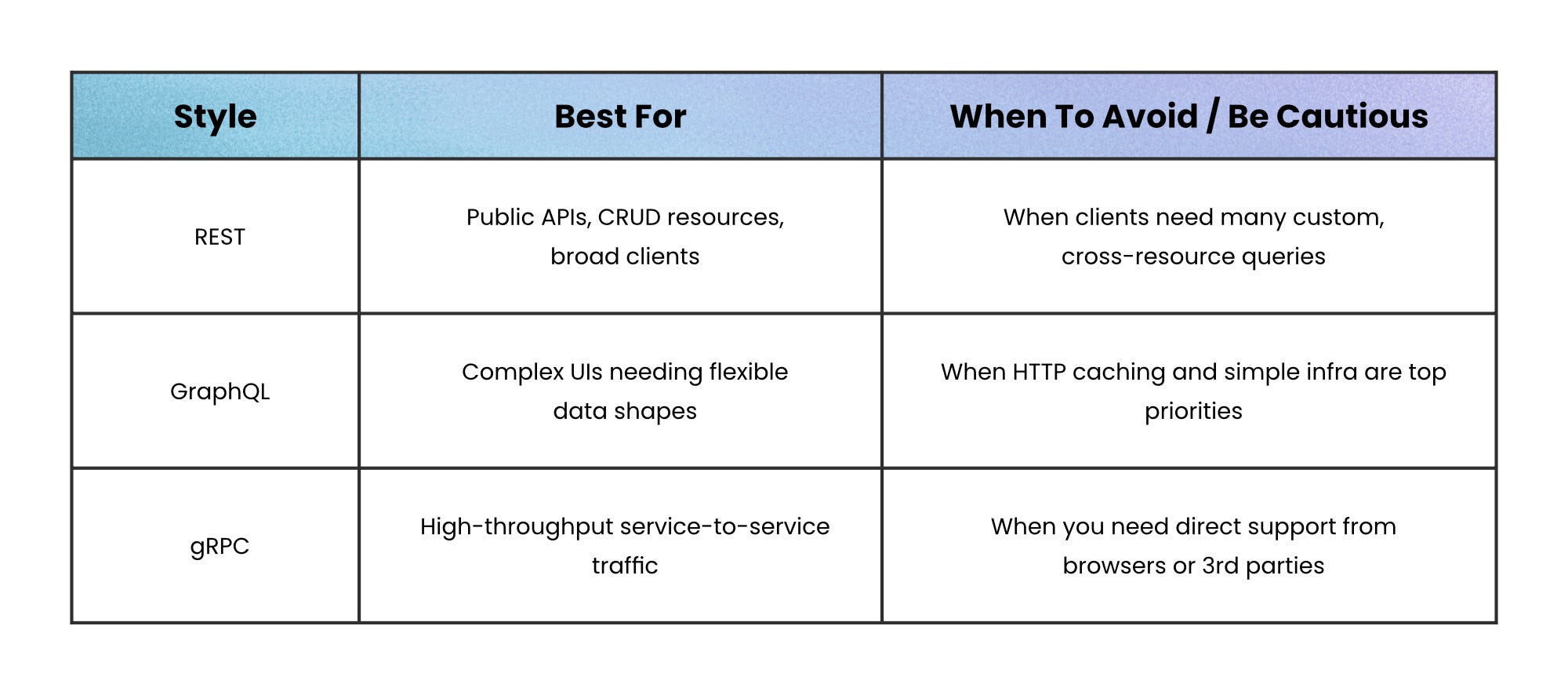
REST vs GraphQL vs gRPC: choosing wisely
You don’t have to pick a single style for everything. Use them where they fit best:
A good rule of thumb:
Start with REST → because it’s simple, well-understood, and easy to expose externally
Add GraphQL → when specific clients juggle too many REST calls or need tailored payloads
Use gRPC → inside your backend when performance, streaming, or strong typing is critical
When not to use REST
Avoid pure REST as the main interface when:
Your main goal is to query complex data, not manage individual resources.
Your services call each other thousands of times per second and every millisecond and byte counts
Your clients need live streams of updates, not occasional snapshots
In these cases, REST can still play a supporting role (for management, control, or external access), but it shouldn’t carry the whole workload.
Recap
REST is more than JSON over HTTP. It’s a set of constraints that, when followed, give you APIs that are simple, scalable, cacheable, and widely compatible.
Understand those principles and you can do three important things: design cleaner APIs, recognize when a “REST API” isn’t really RESTful, and know when to reach for GraphQL or gRPC instead.
That’s the difference between copying patterns and making deliberate architectural choices.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Well written and well explained.
Great article! Simple and precise.