
REST vs GraphQL vs gRPC
The tradeoffs behind resource-driven, query-driven, and method-driven APIs.


A Practical Hub for Building AI Systems
Presented by Oracle
Building production AI systems means combining far more than just models. Retrieval pipelines, memory layers, agent orchestration, evaluation workflows, observability, and infrastructure all need to work together. Oracle’s AI Developer Hub brings these concepts into one place through practical architectures, implementation guides, courses, and real engineering examples for modern AI applications.
REST, GraphQL, or gRPC? Choosing the Right Tool for the Job
Your mobile app over-fetches because REST returns the entire resource, even when the screen only needs three fields. Your internal services waste CPU serializing JSON nobody reads. Your front-end team rewrites the same data-fetching glue for every page because the API never lets them ask for exactly what they need.
These look like separate performance problems, but they usually come from the same root cause: using the wrong API style for the interaction.
REST, GraphQL, and gRPC solve different communication problems.
The mistake is treating them as interchangeable.
An API style is really a tradeoff between flexibility, simplicity, efficiency, and control. Once you understand which tradeoff your system actually needs, the decision becomes much clearer.
The core mental model
Before comparing performance, tooling, or syntax, focus on the interaction pattern each API style is designed around.
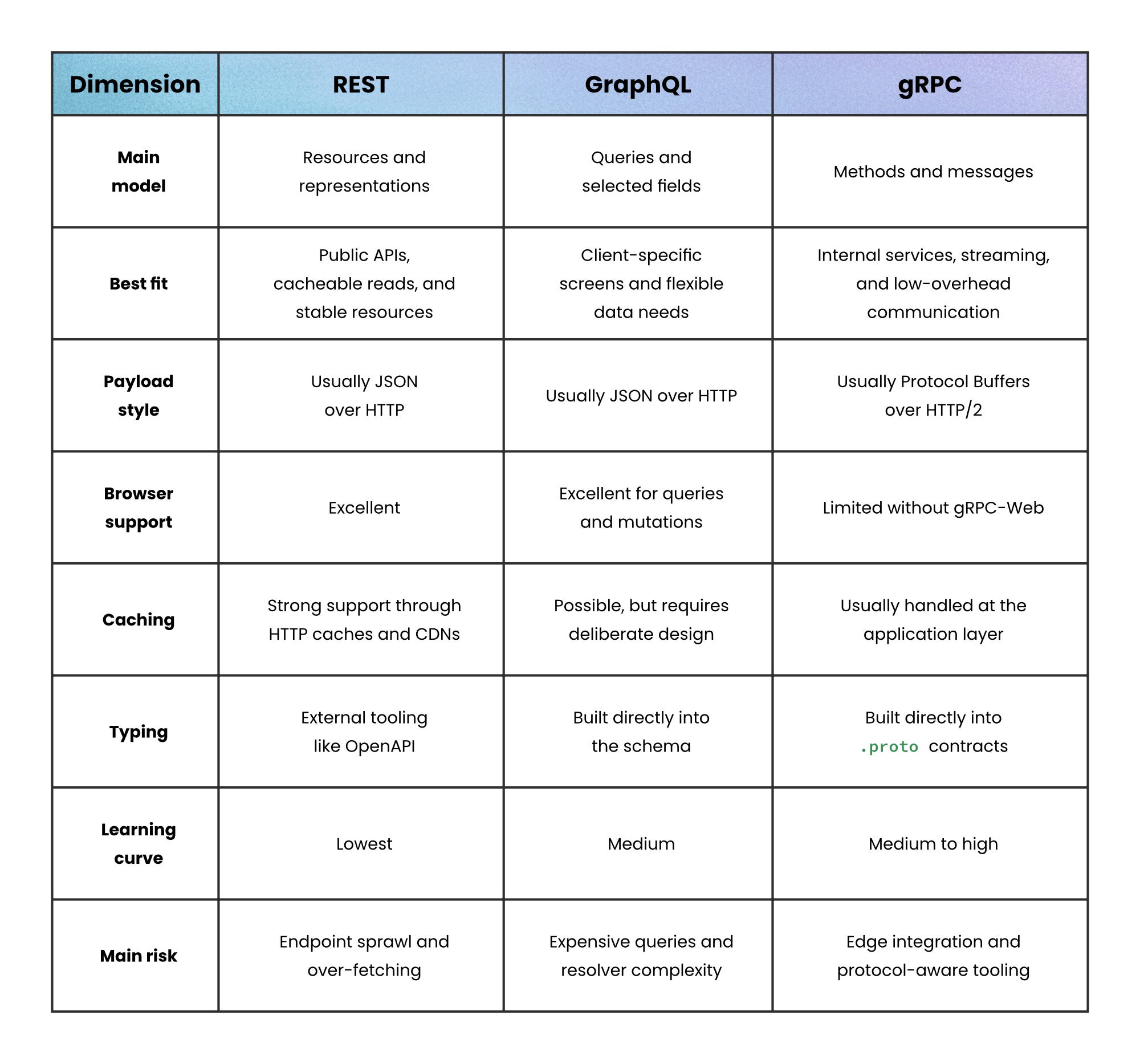
REST → Organizes communication around resources. A resource is a stable thing like a user, product, or order, exposed through URLs that clients fetch, create, update, or delete over HTTP.
GraphQL → Organizes communication around queries. Clients describe the exact shape of data they want, and the server resolves only those fields.
gRPC → Organizes communication around methods. Services expose strongly typed procedures that other services call directly over HTTP/2 using compact binary messages.
That distinction matters more than the syntax itself.
If your system naturally revolves around stable entities like products, accounts, or invoices, REST usually feels predictable and easy to reason about. The API behaves like a catalog where every resource has a clear address and lifecycle.
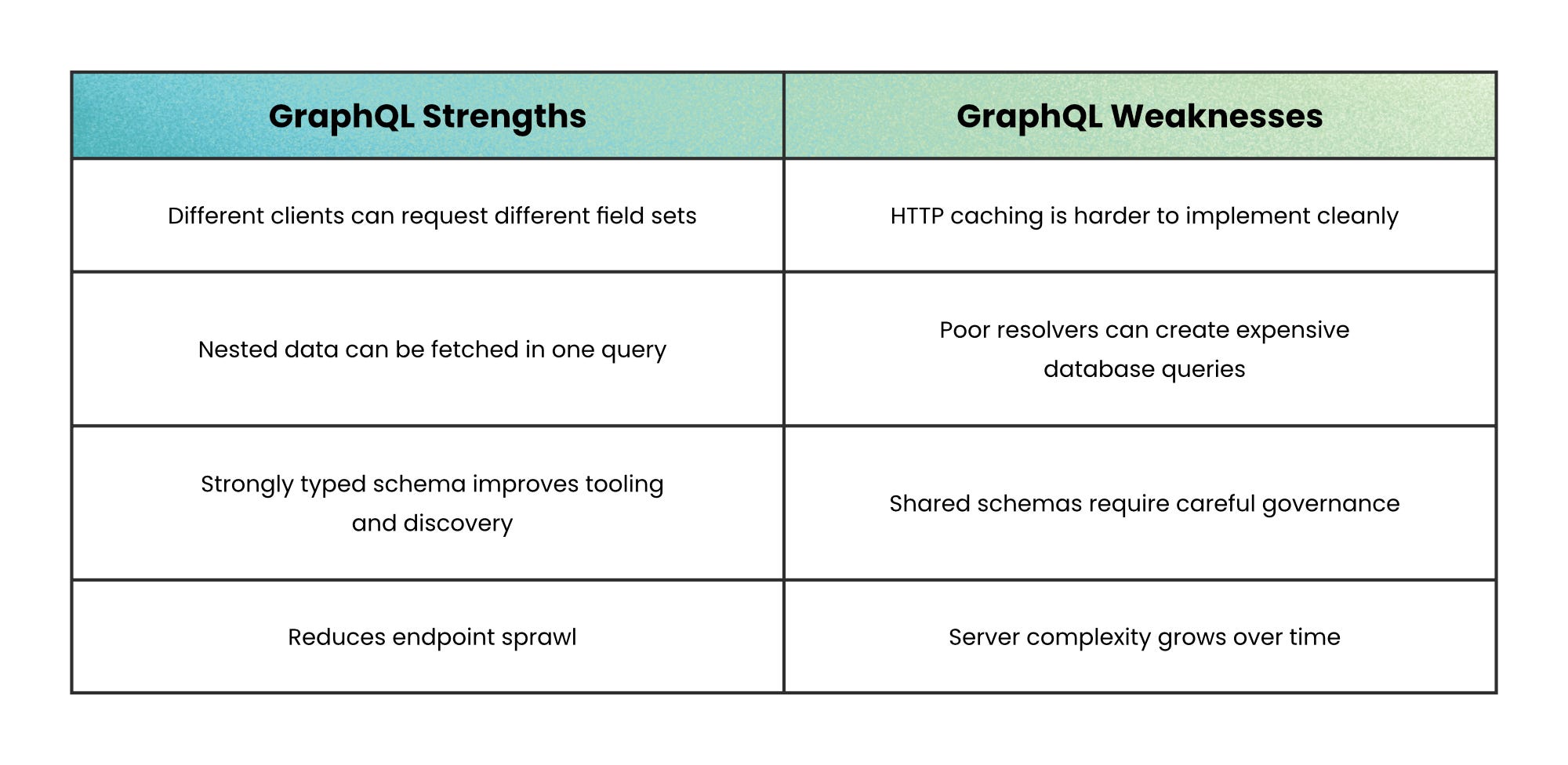
If different clients constantly need different views of the same data, GraphQL reduces the coordination overhead. A mobile app might need five fields while a dashboard needs fifty. Instead of creating endless custom endpoints, clients ask for exactly what they need.
If your biggest bottleneck is service-to-service communication, gRPC optimizes for efficiency. Binary payloads are smaller, contracts are strict, and HTTP/2 keeps connections open instead of repeatedly starting new ones. It behaves less like browsing web pages and more like calling functions across the network.
Once you identify whether your system is resource-driven, query-driven, or method-driven, the tradeoffs become much easier to evaluate.
REST: the default for clear resources and public APIs
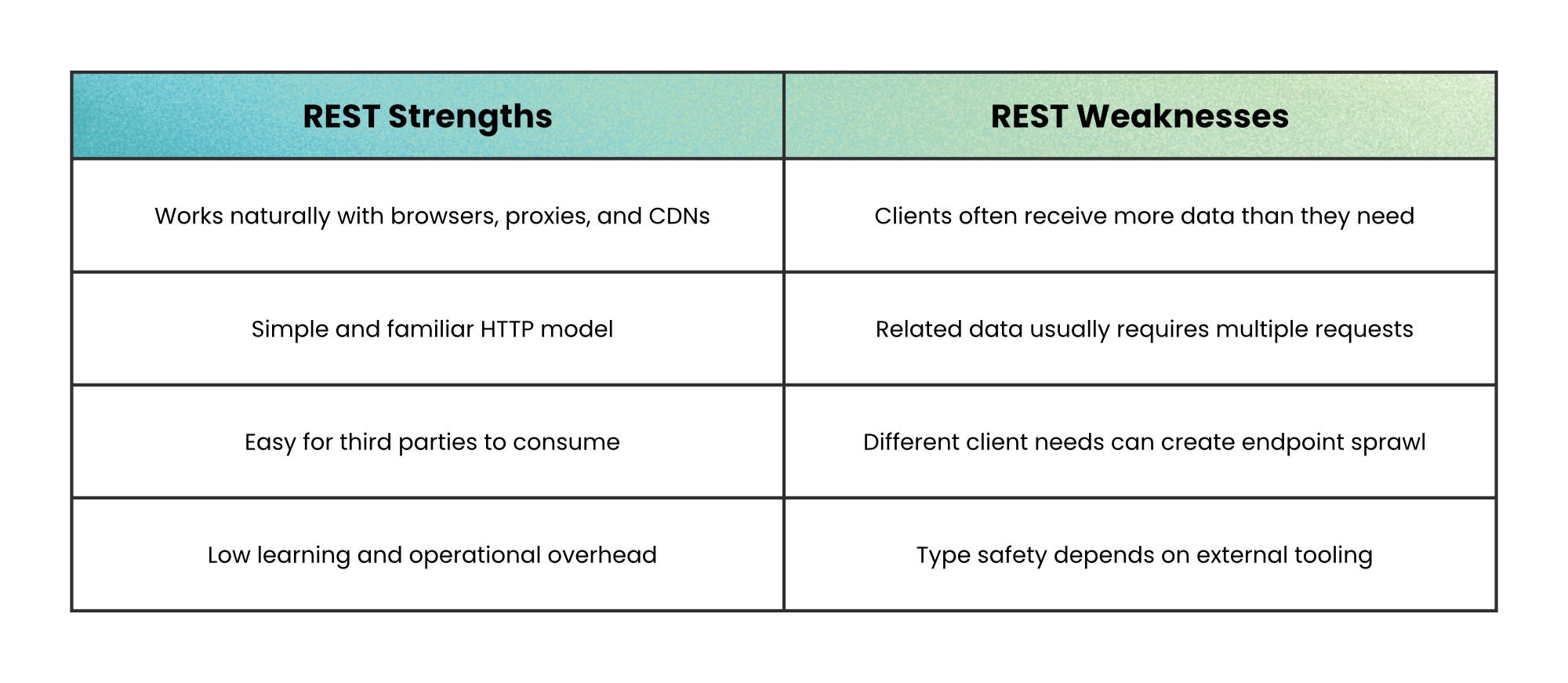
REST works best when your API benefits from standard web behavior.
A product catalog is a good example. Products, categories, prices, and images are stable resources with clear identities. Browsers, CDNs, proxies, and HTTP caches already know how to handle them efficiently.
That simplicity is REST’s biggest advantage. The URL identifies the resource, the HTTP method describes the action, and the status code explains the result.
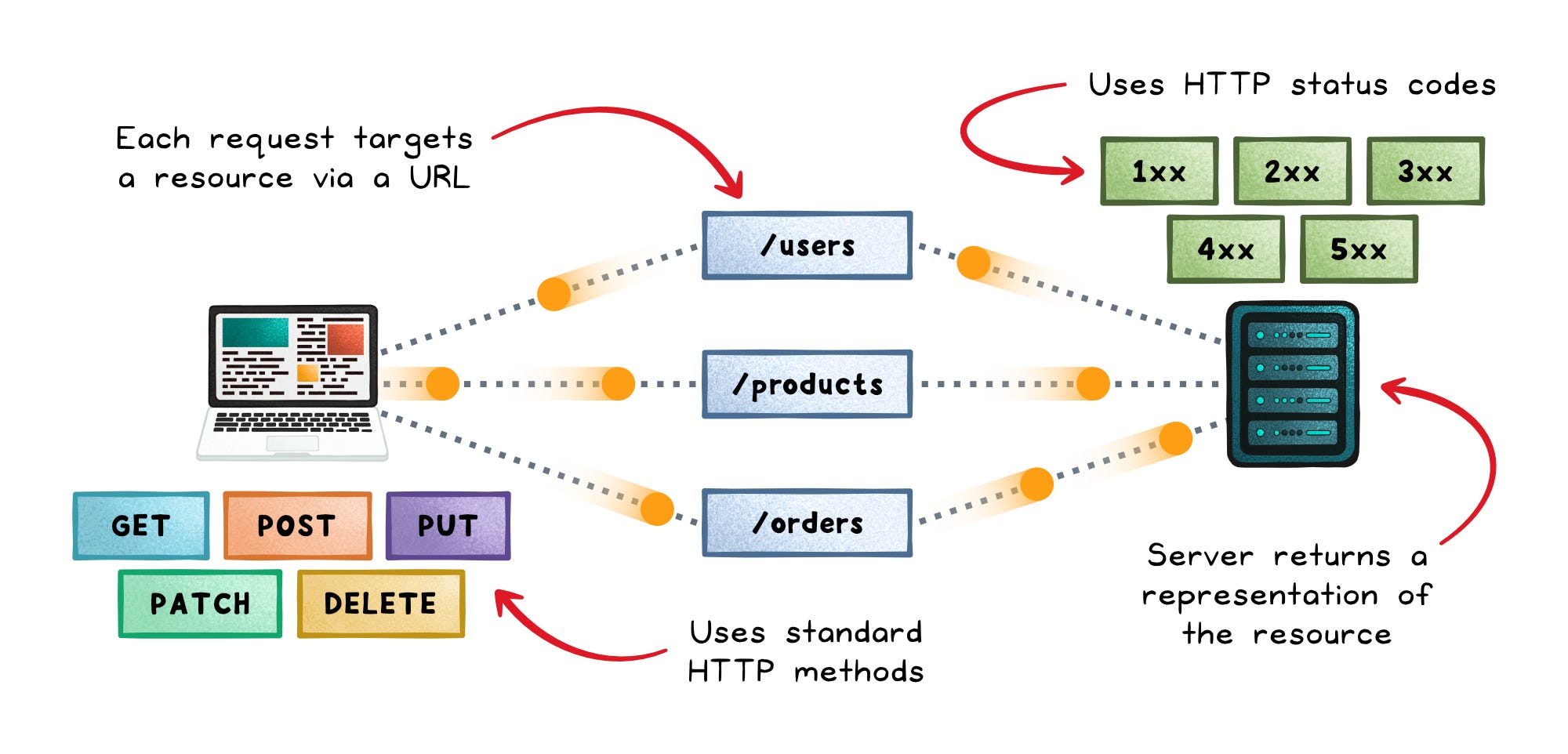
REST gives you:
Browser reach → Standard HTTP works everywhere without special tooling
Cacheability → GET requests work naturally with browsers, proxies, and CDNs
Simplicity → Most developers already understand URLs, headers, and status codes
Public API friendliness → Requests are easy to inspect, test, and debug
The tradeoff is composition.
If a single screen needs products, reviews, recommendations, inventory, and shipping data, REST can turn into multiple round trips. You can create larger endpoints, but clients often receive far more data than they actually use.
Use REST when stability, simplicity, and web infrastructure matter more than fine-grained data control.
GraphQL: the choice for client-shaped data
GraphQL solves a different problem: different clients often need different views of the same data.
A mobile app may only need a product name and price. An admin dashboard may also need inventory, supplier details, and audit history. With REST, you either create many specialized endpoints or return oversized responses that waste bandwidth.
GraphQL lets clients request the exact shape they need.
A view can ask for:
Product name
Price
Inventory status
First three reviews
Nothing more.
The server validates every query against a schema, which is a typed definition of what clients are allowed to request. That schema becomes a shared contract between frontend and backend teams.
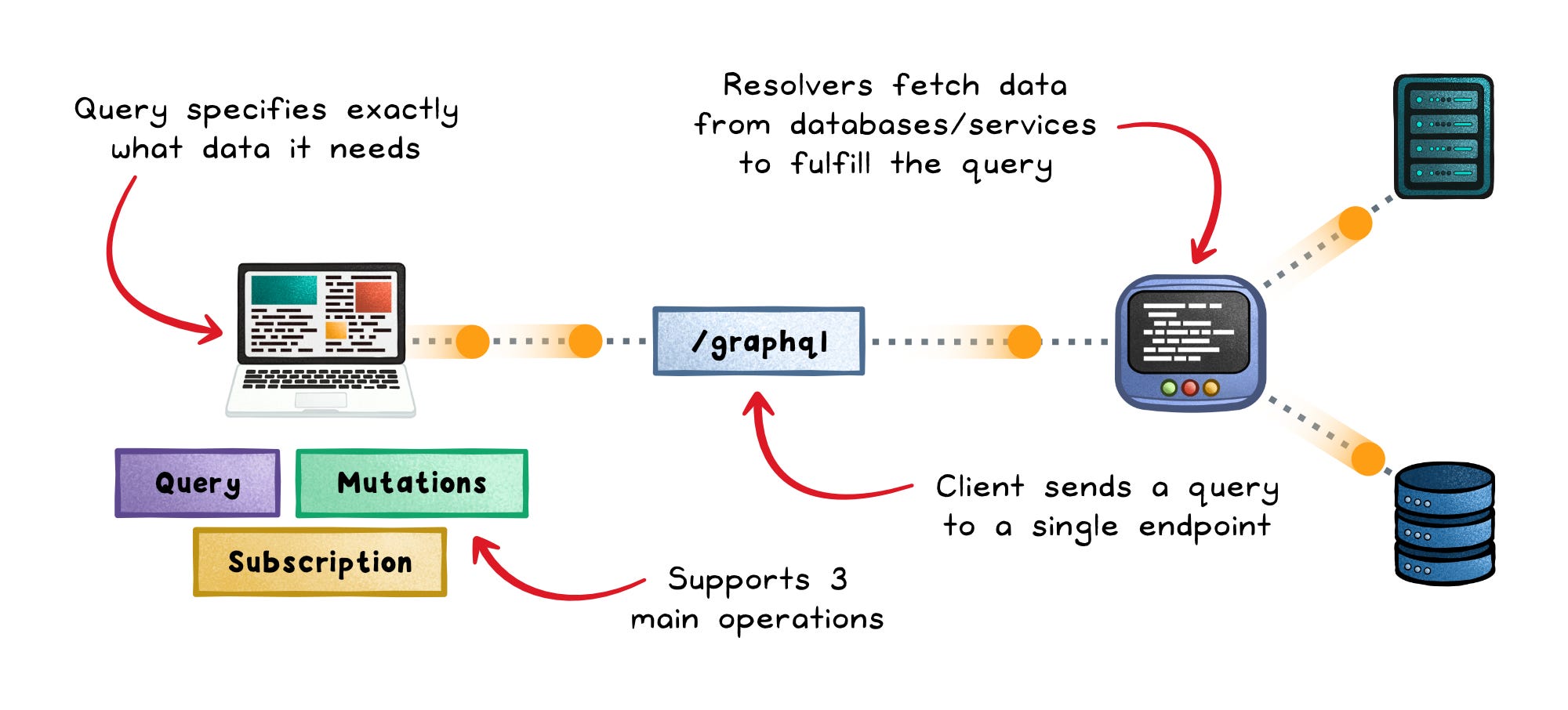
GraphQL gives you:
Flexible field selection → Clients avoid over-fetching and under-fetching
Strong schema → Teams can discover data and generate types automatically
Better composition → One query can gather all data needed for a screen
Frontend independence → Web, mobile, and internal tools can request different shapes
The tradeoff shifts to the server.
Resolvers (responsible for fetching each field) can accidentally trigger large numbers of database calls. A small query can create expensive backend work if you do not control query depth, batching, and caching carefully. Authorization also becomes more complex because many operations flow through a single endpoint.
Use GraphQL when client data needs vary frequently because it reduces endpoint sprawl while keeping the schema consistent.
gRPC: the go-to for efficient service-to-service calls
gRPC works best when both the client and server are controlled by your organization.
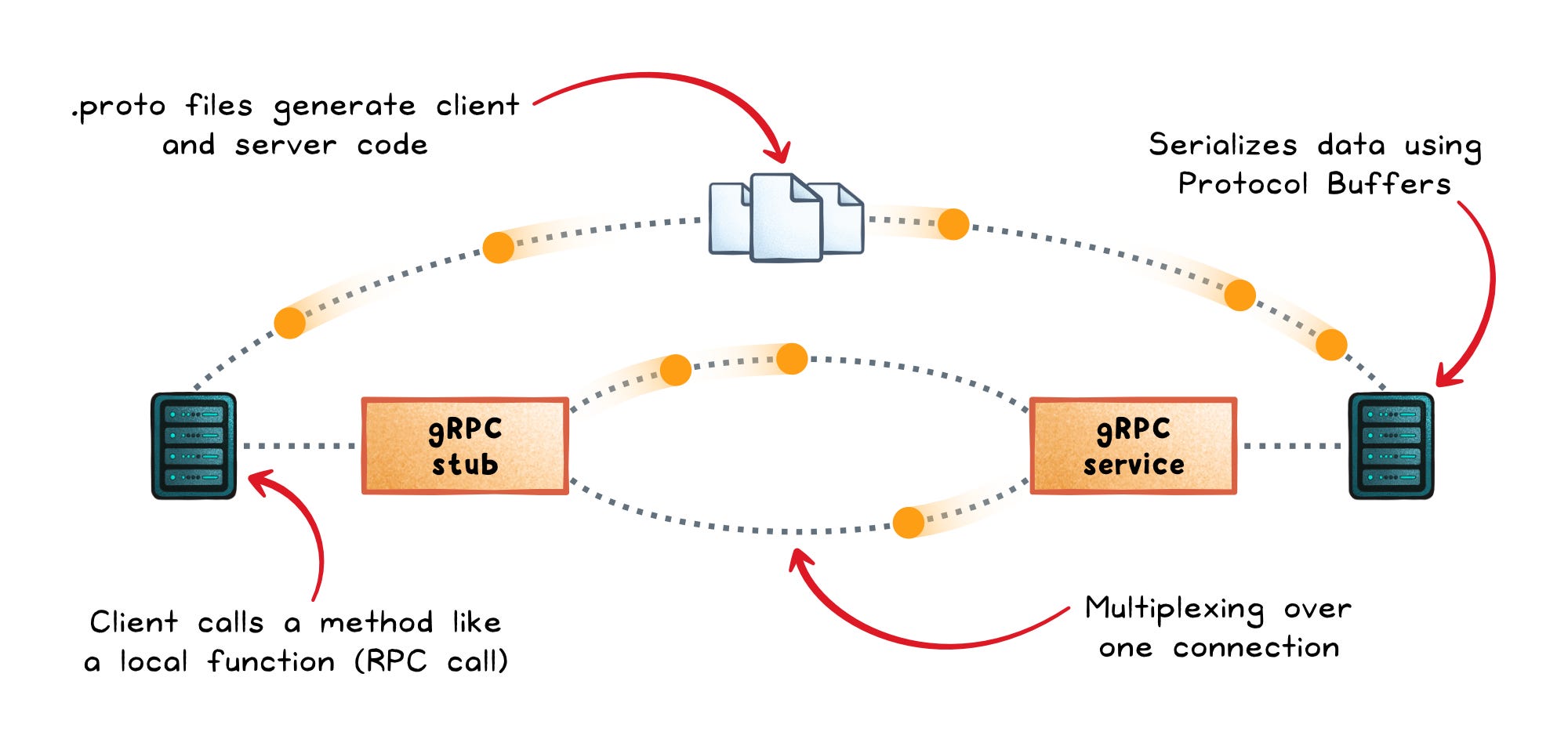
Instead of exposing resources, gRPC exposes services and methods defined in a .proto contract file. Code generation then creates typed clients and servers in different languages, so network calls feel more like local function calls.
That model fits distributed systems well.
A checkout service may need to call pricing, inventory, fraud, shipping, and tax services in milliseconds. Those calls need low overhead, strong contracts, retries, deadlines, and sometimes real-time streaming.
gRPC gives you:
Strong contracts →
.protofiles define services and message formats clearlyEfficient payloads → Binary messages are smaller and faster than JSON
HTTP/2 support → Multiplexing and persistent connections reduce network overhead
Streaming support → Services can stream data in one or both directions
Better service controls → Deadlines, retries, and health checks fit internal systems naturally
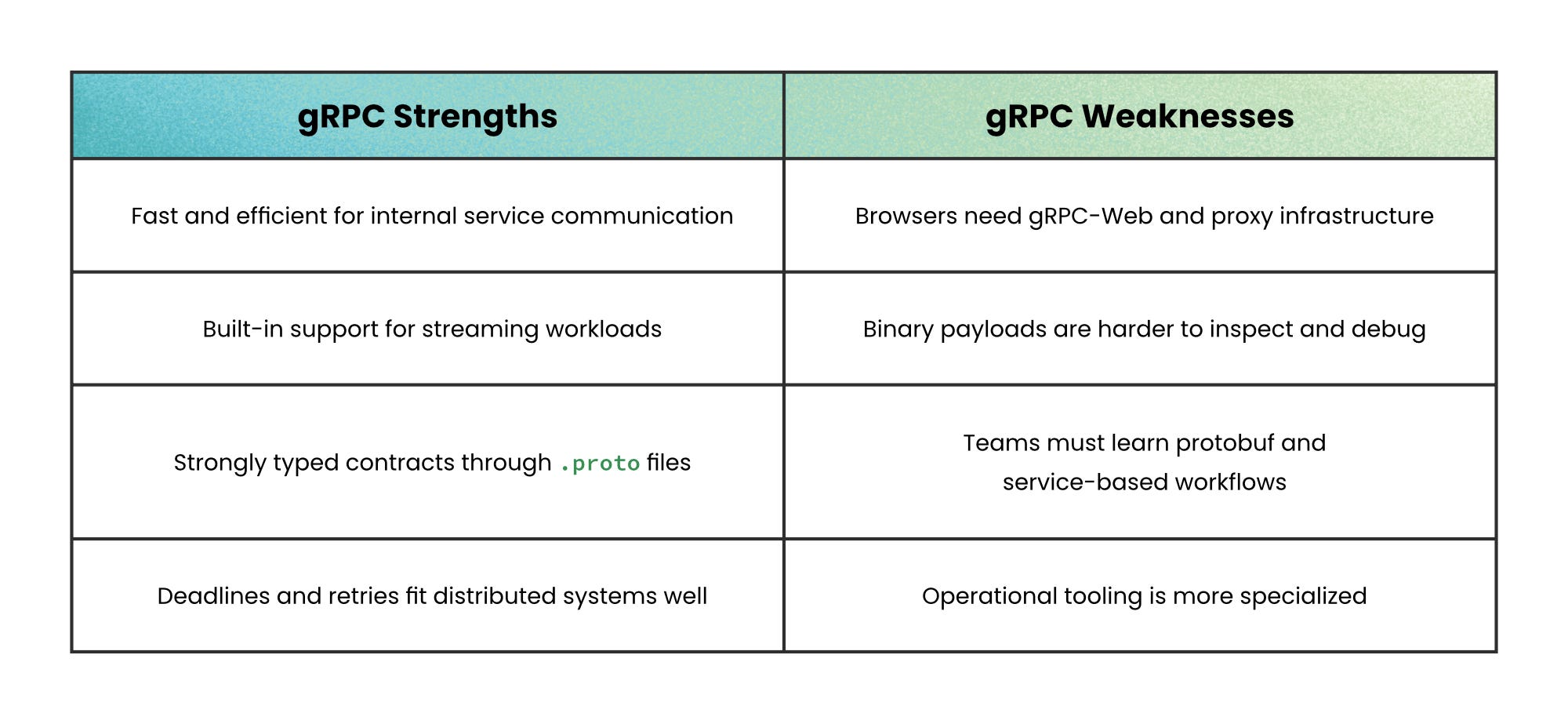
The tradeoff is browser compatibility.
Browsers work naturally with plain HTTP and JSON, but gRPC usually needs gRPC-Web and a proxy layer at the edge. That complexity is often acceptable internally, but it creates friction for public-facing APIs.
Use gRPC for internal service communication because controlled environments benefit most from typed contracts and efficient transport.
Side-by-side comparison
When not to use each
Every API style has cases where it becomes the wrong abstraction.
Avoid REST when clients constantly need data from many related resources in a single screen. Multiple round trips add latency quickly, especially on mobile networks. Teams often respond by building oversized aggregation endpoints, which slowly weakens REST’s clean resource model.
Avoid GraphQL when your API is small, stable, and public-facing. Schema governance, query optimization, resolver efficiency, and access control all add operational overhead. If a handful of REST endpoints already solves the problem cleanly, GraphQL can introduce unnecessary complexity.
Avoid gRPC when browsers or third parties are your primary consumers. gRPC-Web works, but it requires extra proxy infrastructure and specialized tooling. For public web APIs, REST or GraphQL is usually the simpler choice.
The pattern most systems end up using
Most production systems do not choose a single API style. They choose boundaries.
A common pattern is:
REST or GraphQL at the edge → Where browsers, mobile apps, and third parties interact
gRPC internally → Where services benefit from fast transport, typed contracts, retries, and streaming
For example, a product catalog may expose a REST API that CDNs cache aggressively. A mobile app may query a GraphQL layer to fetch only the fields needed for a screen. Behind that layer, internal services communicate through gRPC using compact protobuf messages and deadline-aware calls.
The architecture works because each technology sits where its strengths matter most.
The trap isn’t choosing the wrong one. It’s choosing one and using it everywhere. Most systems benefit from treating these as complementary layers, not competing philosophies.
👋 If you found this useful → Like + Restack to help others learn system design.