
Service Discovery in Distributed Systems Clearly Explained
(5 Minutes) | Client-Side Discovery vs Server-Side Discovery


CodeRabbit: Free AI Code Reviews in CLI
Presented by CodeRabbit

CodeRabbit CLI brings instant code reviews directly to your terminal, seamlessly integrating with Claude Code, Cursor CLI, and other AI coding agents. While they generate code, CodeRabbit ensures it’s production-ready - catching bugs, security issues, and AI hallucinations before they hit your codebase.
Service Discovery in Distributed Systems
In distributed systems, services appear, disappear, and relocate constantly.
If you don’t have a way to track them, your calls will end up in the void.
Service discovery solves this problem by always pointing clients to a healthy, live instance.
The Problem
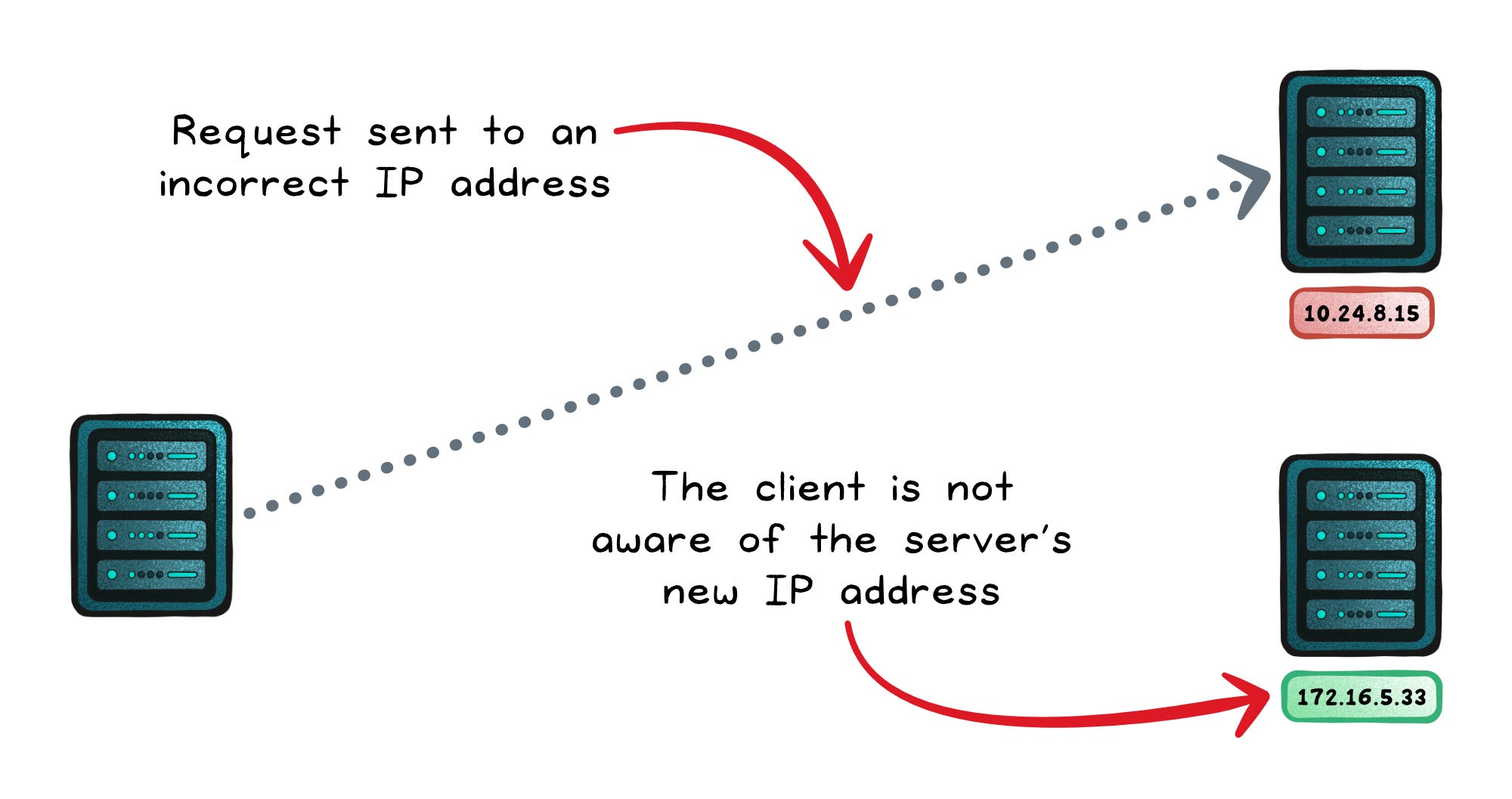
A payments service that worked yesterday on one IP might be gone today. If your application still points to the old address, every request ends in failure.
Now add dozens of microservices, each with multiple replicas, and you have a system where connections break whenever the environment shifts.
Static approaches like hard-coding addresses or juggling config files might hold up in a small setup, but they collapse under the churn of microservices.
What’s needed is a way to always know which instances are alive and how to reach them.
That’s the role of service discovery. Instead of binding calls to fixed addresses, it keeps a live registry of running instances and resolves a simple name like inventory-service into a healthy endpoint at runtime.
The Benefits
Dynamic scaling → New instances register automatically, so traffic flows without manual updates.
Fault tolerance → Dead or unhealthy instances drop out, keeping requests routed to live services.
Load distribution → Requests spread across instances, avoiding overload on a single node.
Location transparency → Clients call by name, not by IP, decoupling deployments from connectivity.
Polyglot support → Any language or framework can participate, as long as it can query the registry.
Faster iteration → Teams deploy services independently without reconfiguring every other client.
Operational consistency → A single naming and lookup system replaces scattered configs.
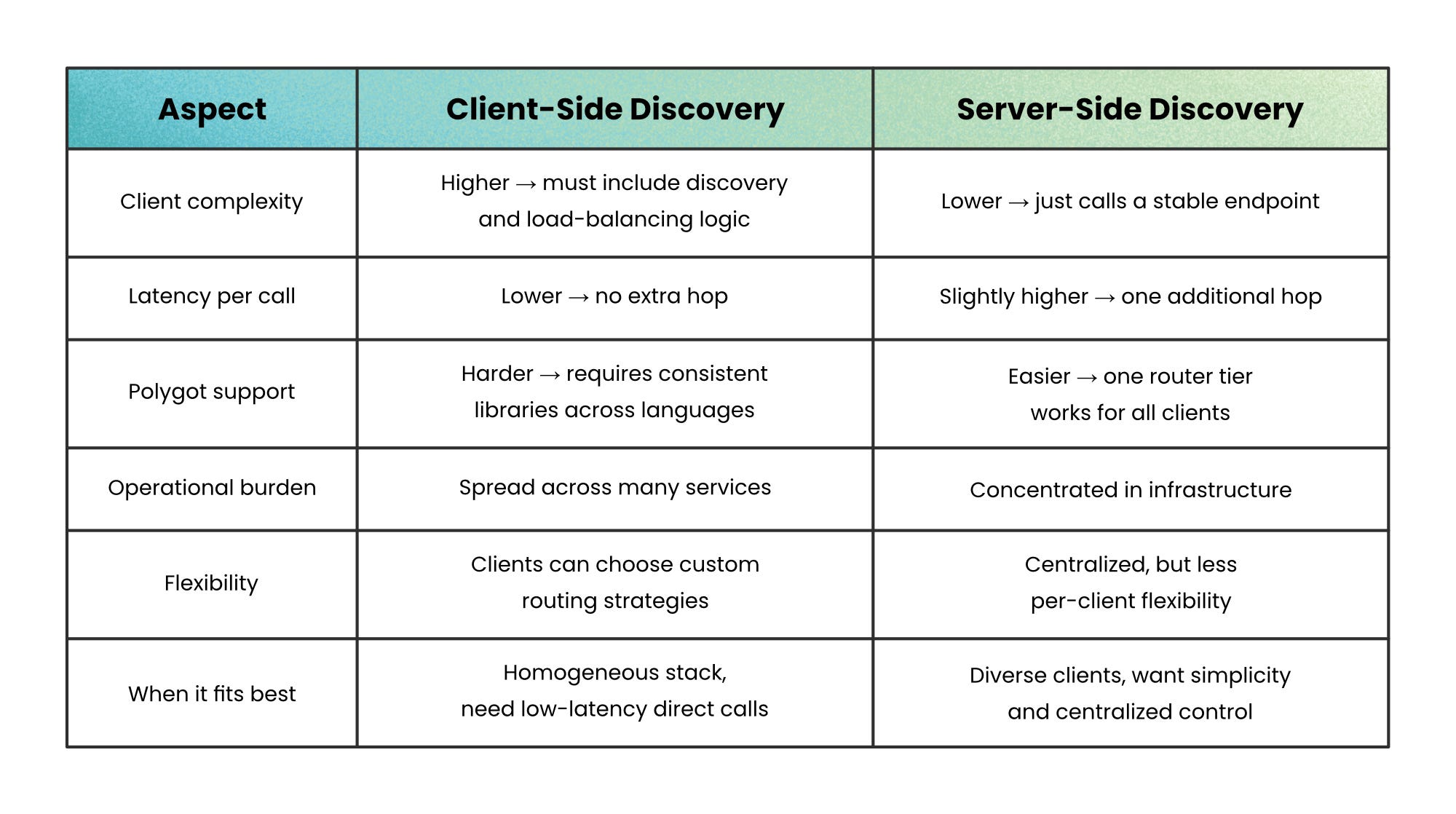
Client-Side Discovery
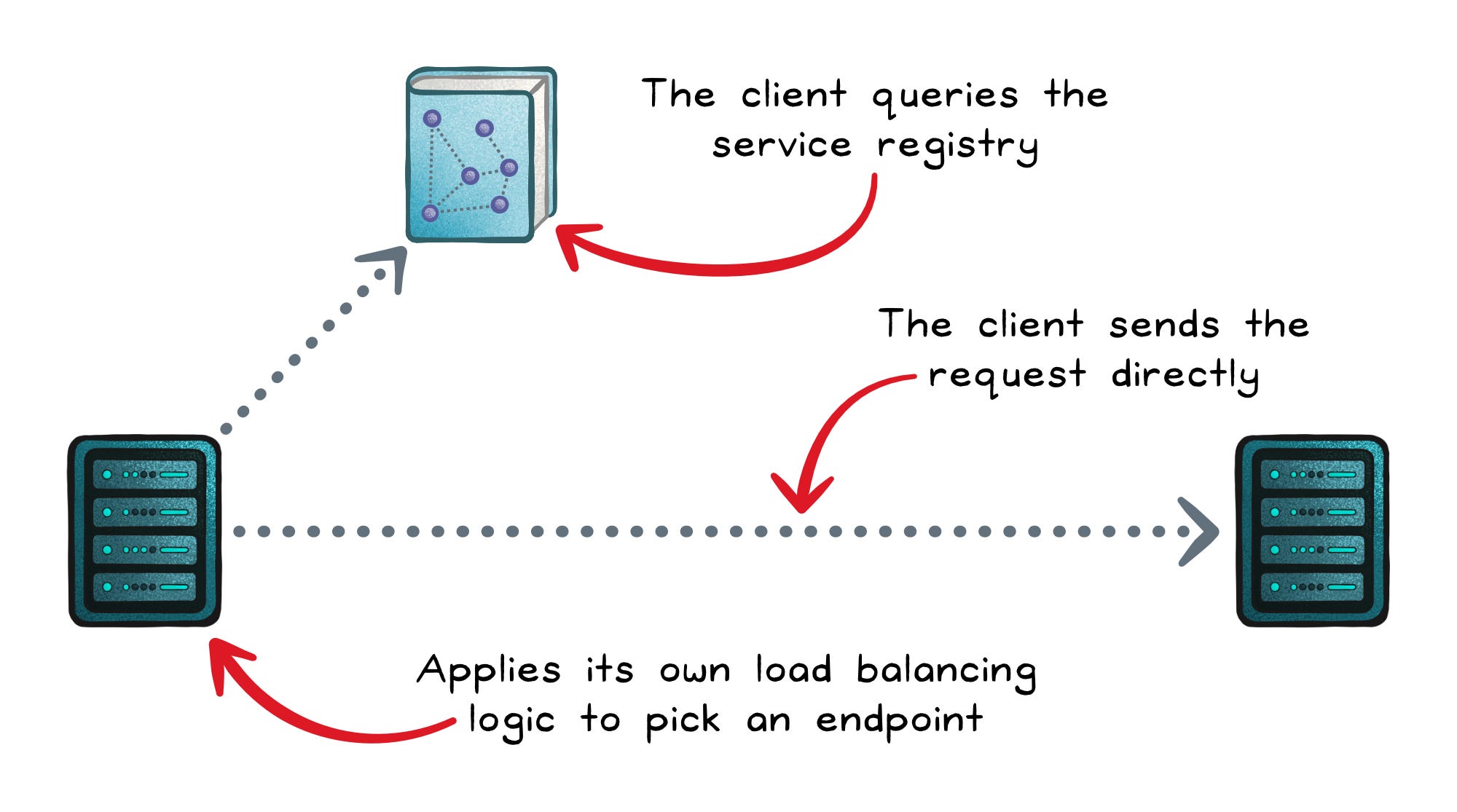
In client-side discovery, the service making the call is responsible for finding a healthy instance of the target service.
The client queries the service registry, receives a list of available endpoints, and then applies its own load balancing logic to pick an endpoint. Once selected, the client sends the request directly, with no middle layer in between.
The Benefits
Lower latency → Requests go straight from client to service without an extra network hop.
Fine-grained control → Clients can choose their own load-balancing strategy or routing rules.
Simpler infrastructure → No central router or proxy to deploy and maintain.
Predictable performance → Each service handles its own lookups, avoiding potential bottlenecks in a shared routing tier.
The Tradeoffs
Added complexity in clients → Every service must include discovery logic or a sidecar, often across multiple languages.
Higher maintenance burden → Polyglot systems require consistent libraries or tooling in each stack.
Tighter coupling → Clients become aware of registry details, making it harder to swap out technologies later.
Risk of duplicated logic → Without careful standardization, different teams may implement discovery inconsistently.
Client-side discovery shines when you value direct connections and low latency, and when your teams can standardize on a shared library or sidecar pattern. But if simplicity in clients or language diversity is a priority, the tradeoffs can outweigh the benefits.
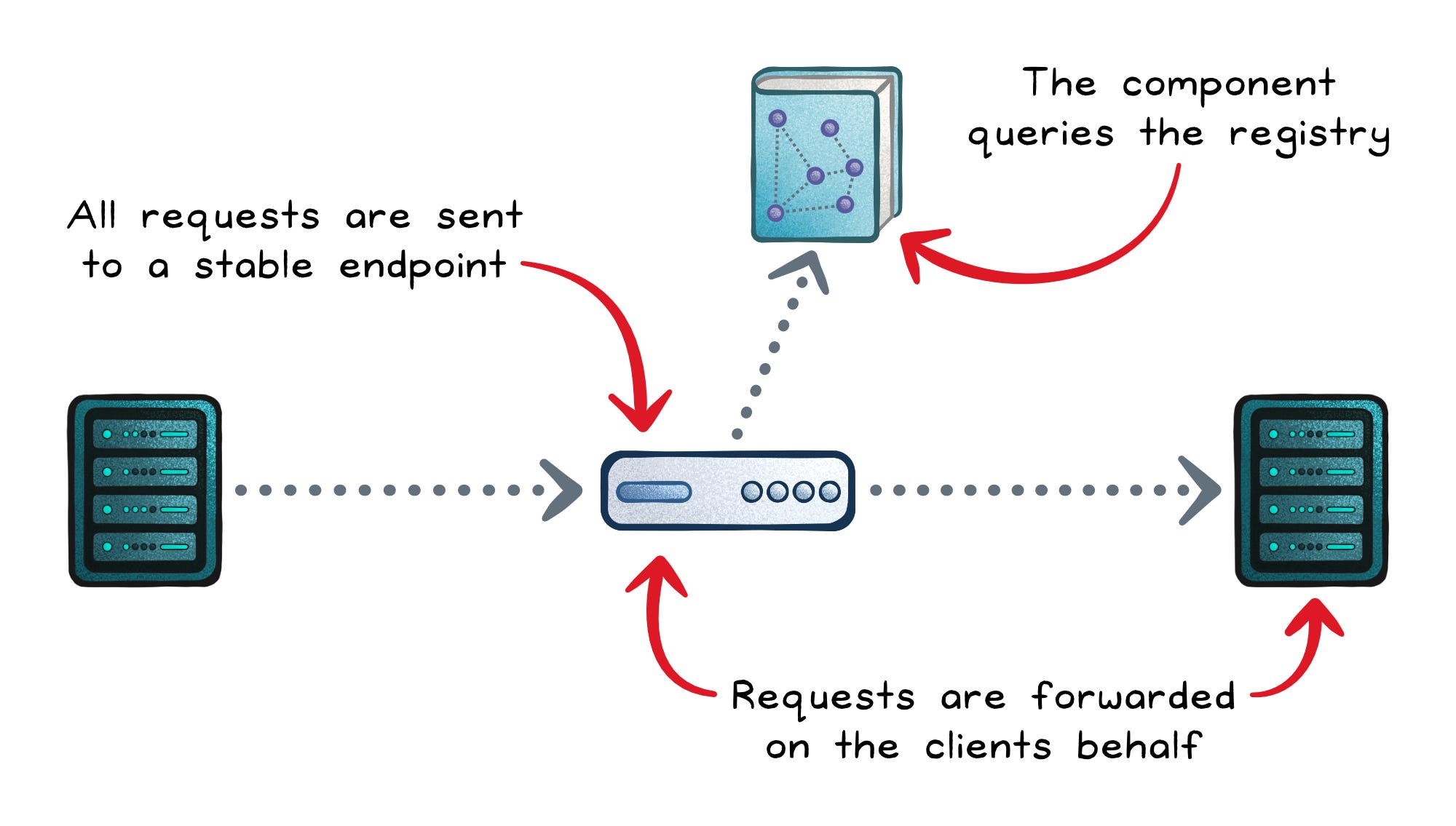
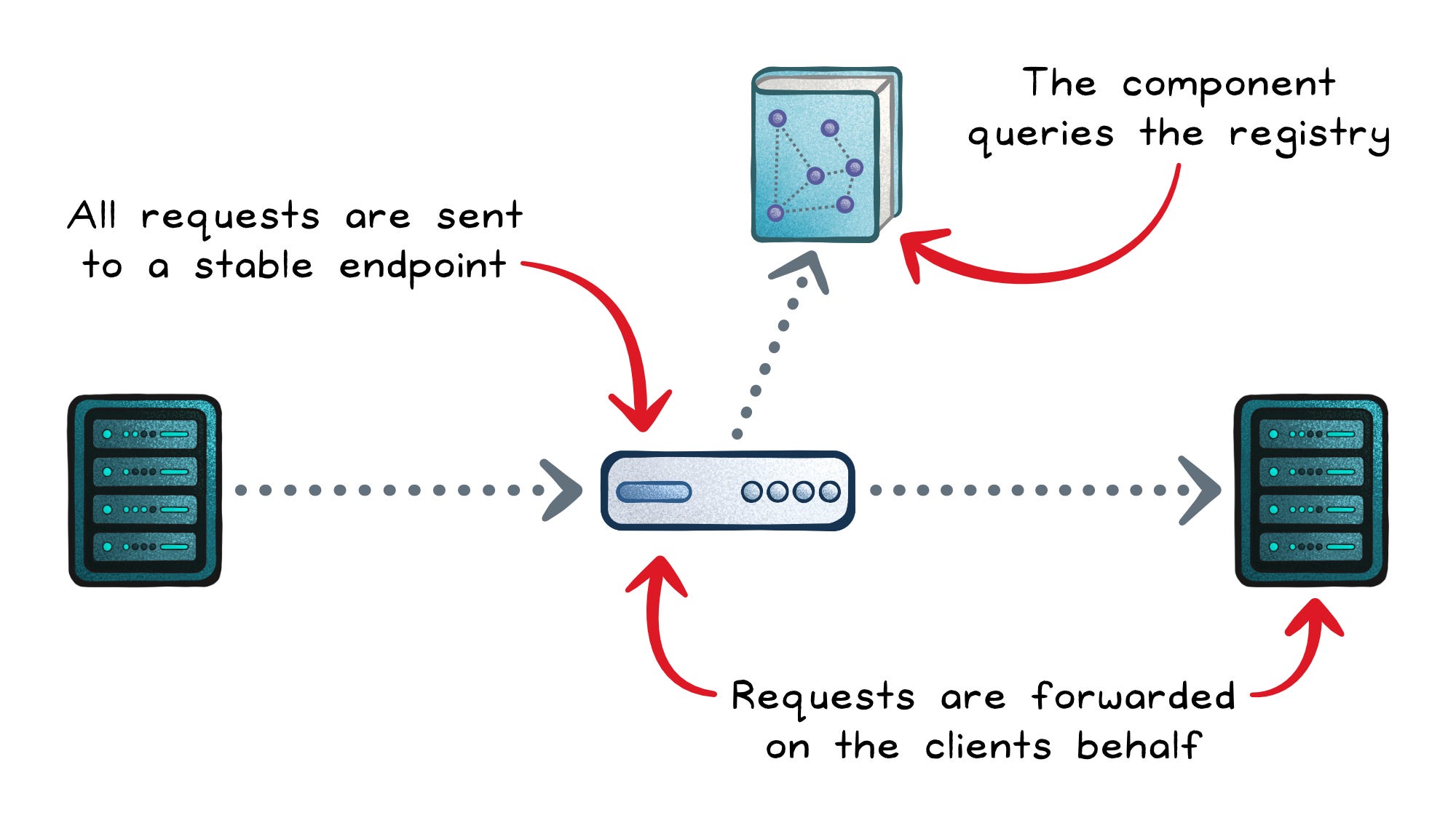
Server-Side Discovery
In server-side discovery, the client doesn’t talk to the registry at all.
Instead, it sends every request to a stable endpoint—usually a load balancer, reverse proxy, or gateway. That component then queries the registry, picks a healthy instance, and forwards the request on the client’s behalf.
From the client’s perspective, it’s always calling the same address, regardless of where services are actually running.
The Benefits
Simpler clients → Every client calls the same stable endpoint with no extra logic required.
Easier polyglot support → One routing tier works for all languages and frameworks.
Centralized control → Load-balancing, retries, and security policies can be managed in one place.
Operational consistency → A single router can log, monitor, and enforce rules across all requests.
The Tradeoffs
Extra network hop → Each request passes through a proxy or load balancer, adding some latency.
Infrastructure dependency → The router or proxy must be highly available, since it becomes part of the critical path.
Operational overhead → Teams need to run, scale, and monitor an additional component.
Less flexibility in clients → Custom routing strategies are harder, since decision-making happens elsewhere.
Server-side discovery works best when your system has many different kinds of clients, or when you want to centralize complexity in the platform instead of scattering it across services. The tradeoff is accepting one more hop in exchange for simpler and more uniform clients.
Recap
Service discovery may run quietly in the background, but it’s one of the foundations of modern distributed systems.
Without it, scaling, deploying, or even just keeping services connected becomes a fragile mess of broken addresses and manual fixes.
Even if you get service discovery “for free,” knowing the patterns and tradeoffs makes you better equipped to debug failures, scale confidently, and design services that can evolve.
Think of service discovery not as an add-on, but as a design principle that allows distributed systems to operate as a cohesive whole instead of disconnected pieces.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: