
SQL vs NoSQL
(5 Minutes) | How to Choose, How Each Works, the Differences, the Benefits, and the Trade-Offs


Depot’s Analysis of 66,821 GitHub Action Runs
Presented by Depot
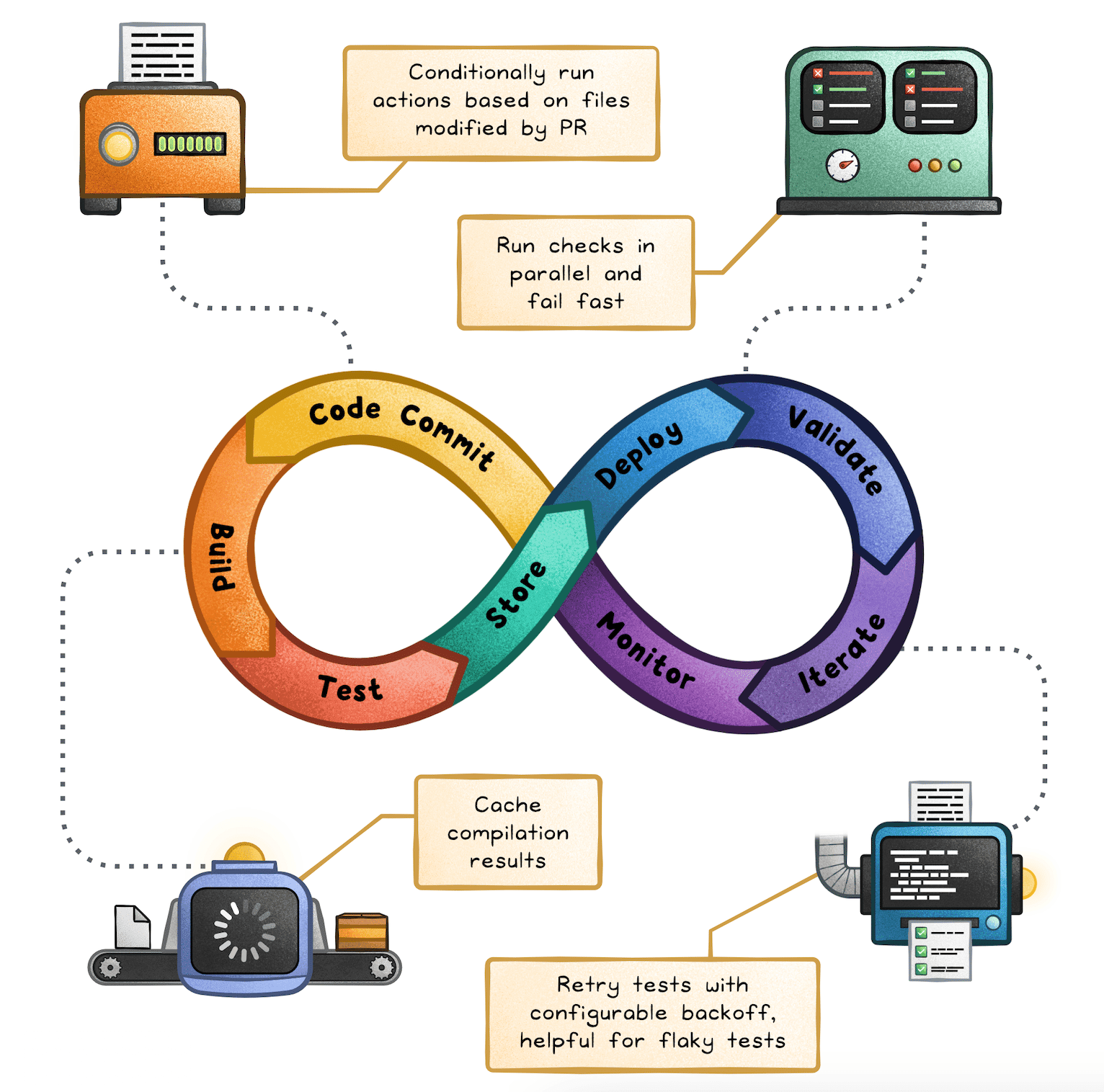
Depot analyzed 66,821 GitHub Actions runs. The analysis showed that teams often use third-party actions less as extensions and more as repairs. The report shares some great hidden gems. Even better than that is fixing the foundation, which Depot does with 20× faster runners and built-in distributed caching.
SQL vs NoSQL: Pick the Model That Matches Your Use Case
“Just use the database we always use” is how many systems paint themselves into a corner.
The wrong model can make simple features painfully complex or cause your app to buckle as it scales.
Your choice between SQL (relational) and NoSQL (non-relational) shapes how you model data, scale traffic, and recover from failure; so it’s important to choose with purpose, not by habit.
The Core Difference
At its core, the divide between SQL and NoSQL is about structure and flexibility.
SQL databases enforce a defined schema and consistent relationships, which is great for predictable data and complex queries.
NoSQL databases relax those rules to handle rapidly changing, varied, or massive data.
That design difference shapes everything else:
How you query → SQL uses a standard language (SQL) with joins and aggregations; NoSQL queries are model-specific and usually simpler.
How you scale → SQL scales vertically first; NoSQL scales horizontally through partitioning and replication.
How you stay consistent → SQL favors strong ACID guarantees; NoSQL often trades strict consistency for availability and speed.
How They Work
SQL
SQL databases revolve around structure and guarantees.
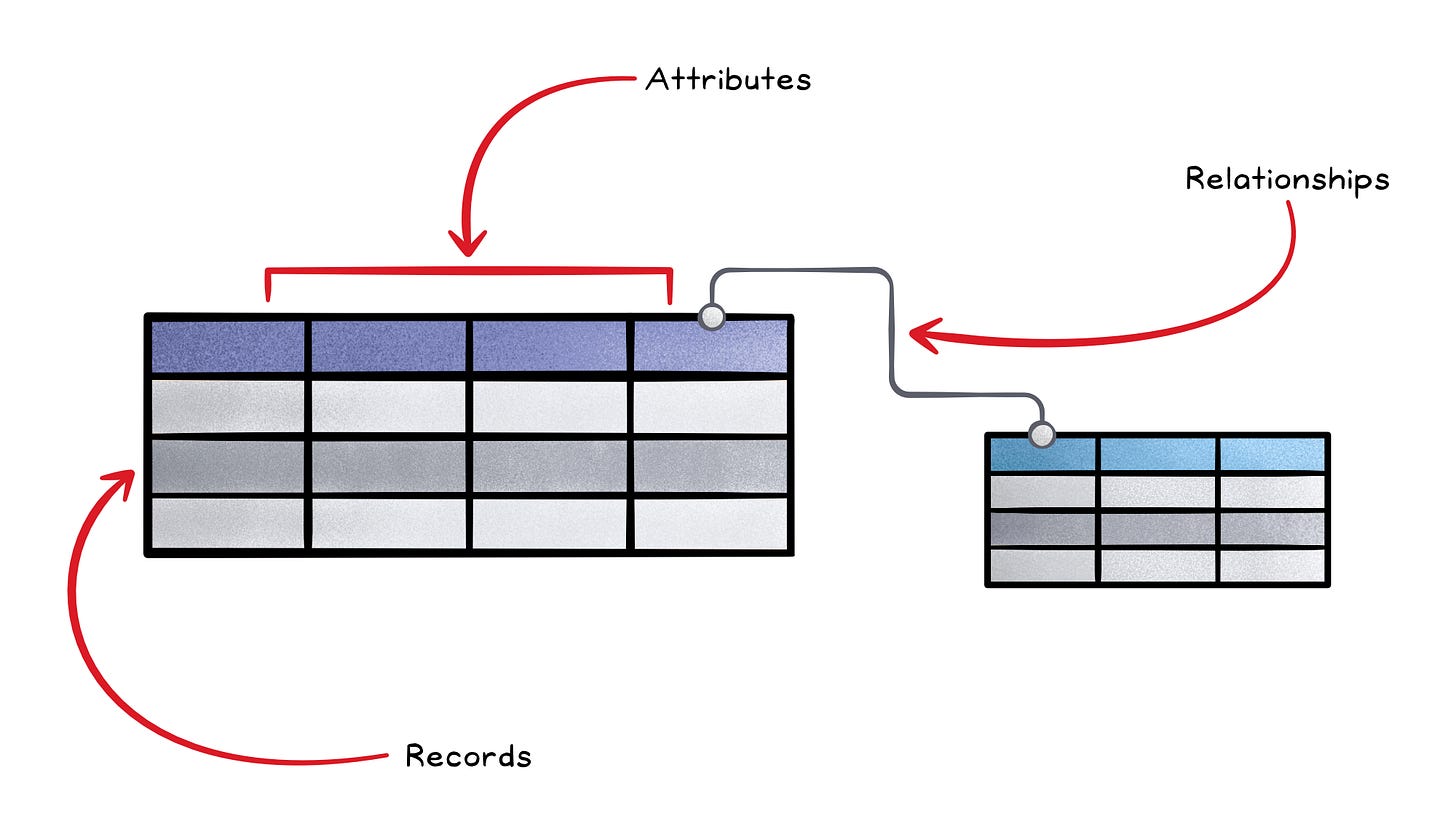
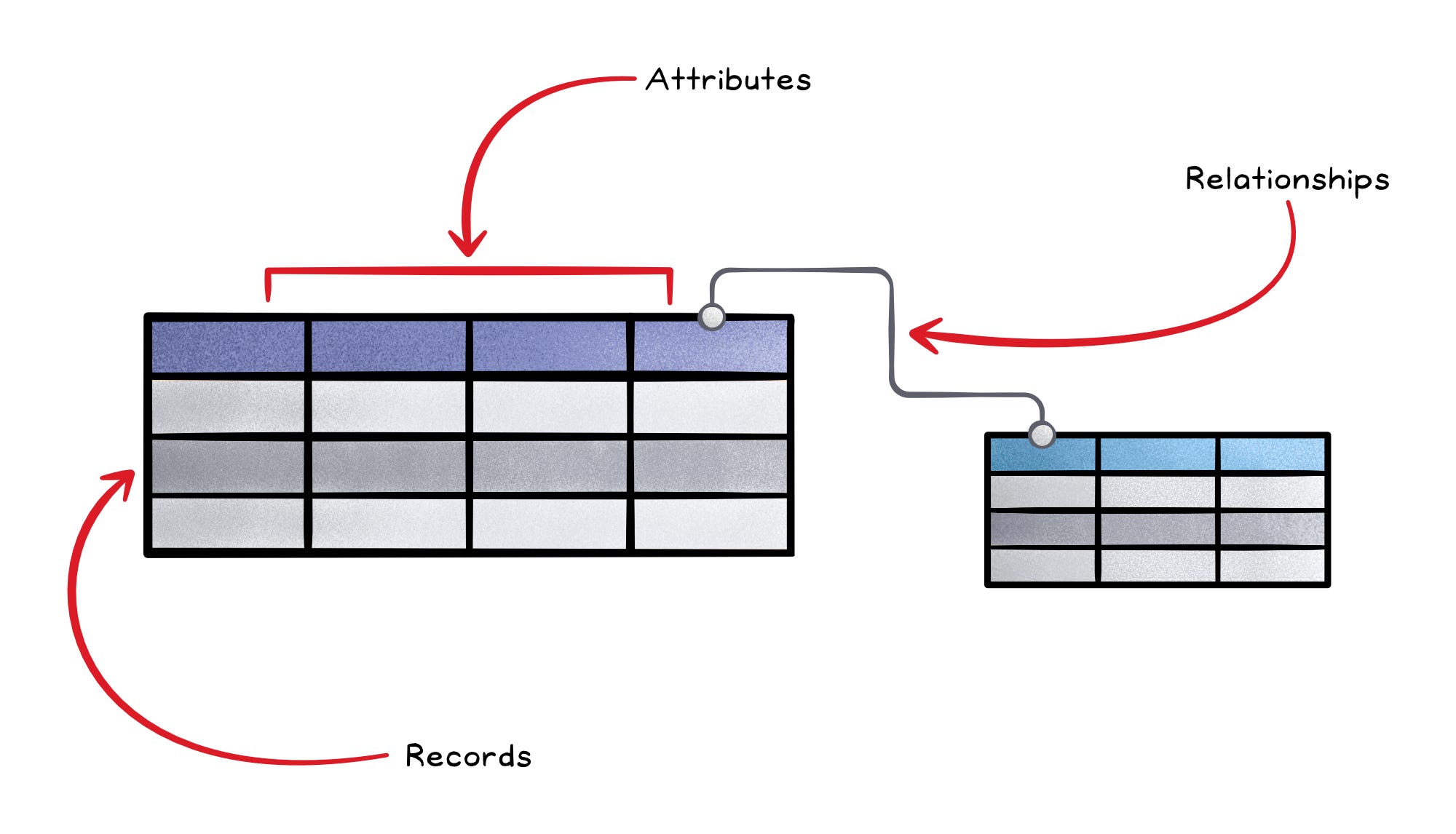
They store data in tables (rows for records, columns for attributes) with a schema that defines the structure of the data (what columns exist, their types, and how tables relate). This schema enforces consistency: every record follows the same rules for types, relationships, and constraints.
When you write data, SQL wraps your operations in an ACID transaction:
Atomicity → All steps succeed or none do (no partial updates).
Consistency → Business rules and constraints stay valid after each transaction.
Isolation → Simultaneous writes don’t interfere with each other’s changes.
Durability → Once a transaction commits, it’s safely stored; even after a crash.
Behind the scenes, a query planner optimizes your SQL statements; choosing indexes, join orders, and execution paths. This lets you express complex logic (“all orders over $200 from users in Australia”) without writing custom traversal code.
Most SQL databases rely on a single primary node to coordinate reads and writes for consistency. Replicas add redundancy, but scaling across nodes usually needs manual sharding or special tools.
NoSQL
NoSQL databases are built for flexibility and scale.
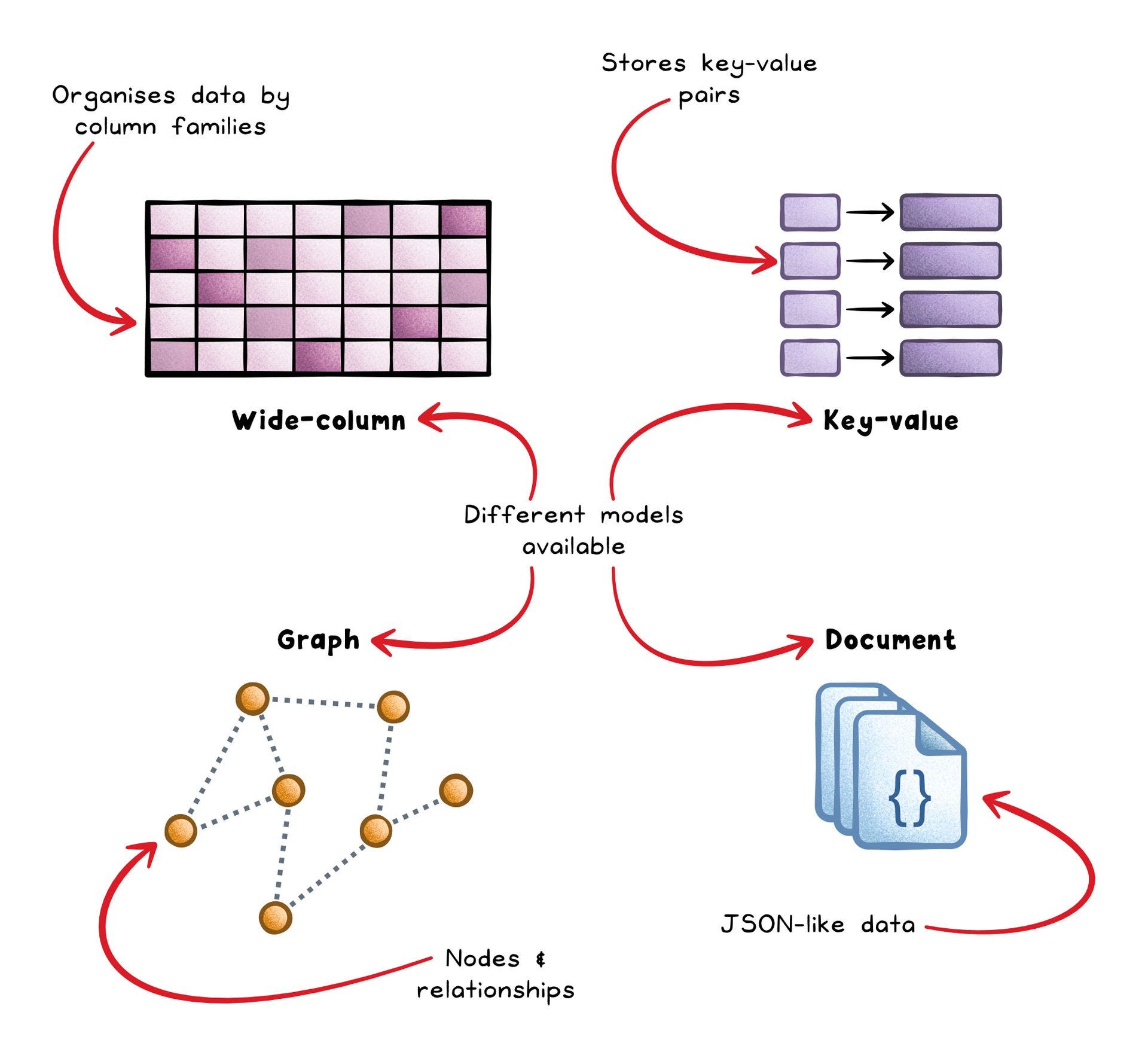
Instead of fixed tables and schemas, they store data in models that match the use case; documents, key–value pairs, wide-column tables, or graphs. Each record can have different fields, letting you evolve data structures without migrations.
NoSQL systems favor the BASE approach over ACID:
Basically Available → The system stays responsive even during failures.
Soft State → Data may change while replicas synchronize.
Eventually Consistent → All copies align once updates settle.
They scale horizontally by sharding (splitting data across nodes) and replicating (copying it for fault tolerance). This design means more servers handle more traffic, instead of relying on one powerful machine.
Each NoSQL model has different strengths:
Document stores (e.g. MongoDB) → Store JSON-like data and make flexible queries easy.
Key–value stores (e.g. Redis) → Read and write simple data extremely fast.
Wide-column stores (e.g. Cassandra) → Handle massive write volumes across many nodes.
Graph databases (e.g. Neo4j) → Represent and query complex relationships naturally.
Advantages and Trade-offs
Both SQL and NoSQL solve different problems well. The key is knowing which trade-offs you’re accepting.
SQL
NoSQL
How to Choose Between SQL and NoSQL
There’s no one “better” database; only the one that fits your problem.
Use the data shape, access patterns, and scale needs of your system to guide your choice.
Choose SQL when…
Your data is structured → Tables, relationships, and rules are well-defined.
You need strong consistency → Every transaction must be correct right away.
Your queries are complex → You rely on joins, aggregations, and filters.
Your workload is moderate → Vertical scaling and replicas are enough to scale with.
Your team depends on analytics → SQL integrates cleanly with BI tools and dashboards.
Choose NoSQL when…
Your data is flexible → Records vary by type, version, or product.
You need horizontal scale → Your data or traffic must be spread across many servers to handle growth.
Availability matters most → You can tolerate slightly stale data during syncs.
Your queries are simple → Reads and writes by key or ID dominate your workload.
Your app evolves fast → You don’t want migrations blocking rapid iteration.
Many systems use both, here’s how you can too:
Use SQL for transactions and analytics where integrity matters.
Use NoSQL for caching, sessions, or event data where scale and flexibility is needed.
Final Thoughts
Choosing between SQL and NoSQL isn’t about right or wrong; it’s about finding the right fit.
SQL gives you order, reliability, and mature tools for structured data.
NoSQL gives you freedom, scale, and resilience when data or traffic grows unpredictably.
The best systems often use both, matching each workload to the strengths of its data model.
Pick intentionally, design for your future scale, and let your data (not trends) drive the decision.
Subscribe to get simple-to-understand, visual, and engaging system design articles straight to your inbox: