
System Design Quality Attributes Clearly Explained
(9 Minutes) | How Quality Attributes Drive Architecture Decisions Under Real Constraints


Build AI Apps with MongoDB
Presented by MongoDB

Looking to stay ahead of the curve on AI? MongoDB AI Learning Hub has the technical training pathways and tools you need to level up your AI app-building game. Explore practical guides, tutorials, and quick starts for all skill levels, from foundational concepts like understanding AI tool stacks to advanced implementations using RAG, Atlas Vector Search, and LLM optimization.
System Design Quality Attributes
Many systems fail not because a feature is missing, but because the system buckles under real-world pressure: slow requests, flaky uptime, tangled code, or weak security.
The fix isn’t “more functionality”, it’s intentional attention to quality attributes and the design pillars that bring them to life.
This is the difference between software that merely works and software you can bet the business on.
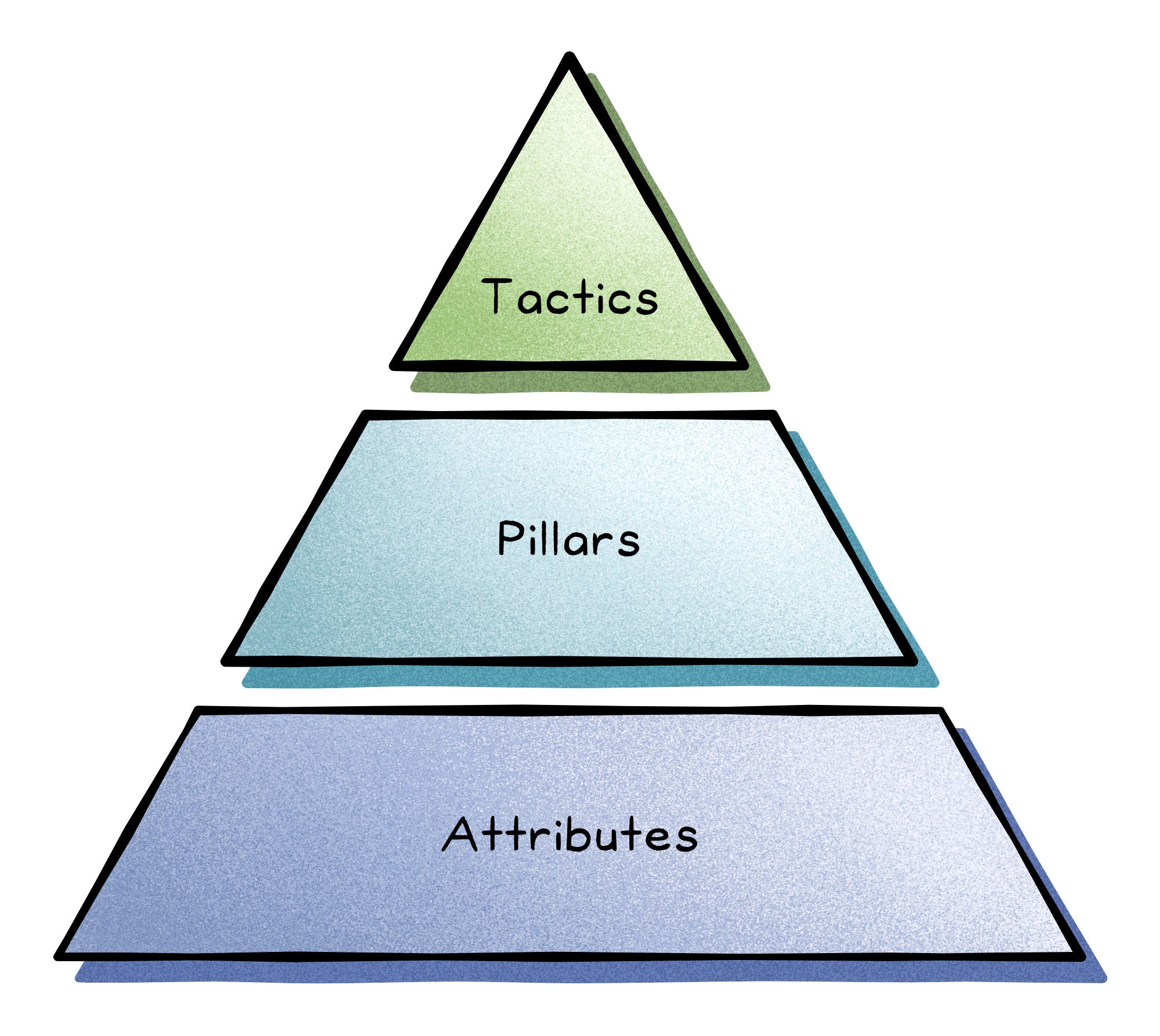
What You Actually Optimize
You can’t maximize everything. Availability (being up) competes with cost, strong consistency competes with global latency, and flexibility competes with simplicity.
Good architecture starts by ranking the attributes that matter for your context, then choosing the pillars and tactics that deliver them.
Think of attributes as goals, pillars as strategies (modularity, redundancy, fault tolerance), and tactics as mechanisms (caching, sharding, circuit breakers).
Decide the goals first; the rest follows.
What Makes These Qualities Work
Each quality attribute depends on a few foundational design ideas: the “pillars” that make those attributes achievable in real systems.
They aren’t silver bullets, but structural choices that shape how your software behaves under stress, change, and growth.
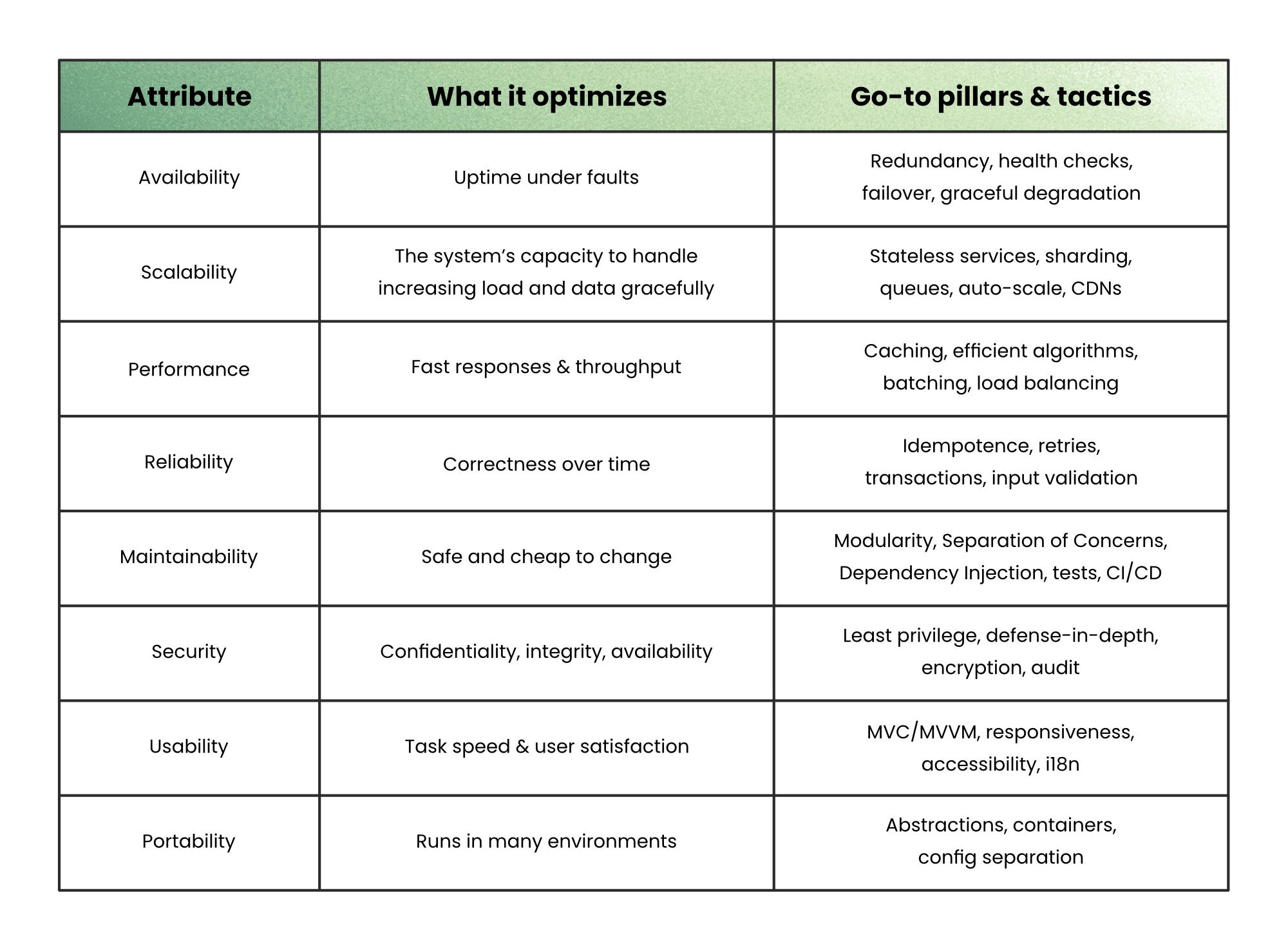
Availability → Redundancy and Fault Tolerance
A system stays available when no single failure takes it down.
Redundancy (multiple instances, replicas, or regions) removes single points of failure.
Fault tolerance ensures those backups actually help: retries, timeouts, health checks, and circuit breakers detect and recover from issues automatically.
Together, they keep users online even when parts of the system aren’t.
Scalability → Statelessness and Partitioning
Scalable systems handle more traffic by adding resources, not rewriting code.
Statelessness makes that possible; each request can land on any node without shared session data.
Partitioning (or sharding) spreads load and data across nodes so throughput grows linearly with capacity.
These two pillars let systems scale horizontally instead of vertically.
Performance → Efficiency and Locality
Performance starts with doing less work per request.
Efficient algorithms and data structures reduce processing time, while caching brings data closer to where it’s needed.
Locality (minimizing network hops and latency) keeps operations fast even at scale.
Optimize the slowest path first, not every line of code.
Reliability → Idempotence and Consistency
Reliability means the system behaves correctly, even under retries or crashes.
Idempotent operations ensure the same request can run twice without corrupting state.
Consistency models define how data changes propagate across replicas, balancing correctness with speed.
Strong reliability is predictable behavior under unpredictable conditions.
Maintainability → Modularity, Abstraction, and Separation of Concerns
Maintainability is about how safely and efficiently a system can evolve as requirements change.
Modularity breaks a system into independent components with clear boundaries, so teams can build, test, and deploy parts in isolation.
Abstraction defines stable interfaces that hide implementation details, allowing one module to evolve or be replaced without breaking other modules they interact with.
Separation of concerns divides a system into parts that each handle a distinct responsibility, keeping logic focused and dependencies minimal. This reduces coupling so changes in one area don’t ripple unpredictably through others.
These patterns lower the cost of change, which is crucial when a system evolves daily.
Security → Least Privilege and Defense in Depth
Security isn’t one feature, it’s embedded into the design.
Least privilege limits what each user or service can access.
Defense in depth ensures that if one layer fails (say, authentication), others like encryption or network isolation still protect data.
Secure systems expect breaches and constrain their impact.
Usability → Feedback and Accessibility
Usability measures how easily real people can accomplish real tasks without friction or confusion.
Clear feedback loops show users what’s happening.
Accessibility ensures everyone can interact with the system regardless of device, language, or ability.
Systems that are easy to use are harder to misuse and easier to adopt.
Portability → Abstraction and Configuration
Portable systems adapt to new environments without code changes.
Abstraction hides OS or vendor specifics behind interfaces.
Configuration separates environment data from logic.
Containers, infrastructure-as-code, and well-defined APIs make migration and deployment predictable.
Together, these pillars form a toolkit for building resilient software.
You can’t optimize every attribute equally; but knowing which pillars support which qualities helps you design systems that fail gracefully, scale smoothly, and evolve safely.
Trade-Offs
Every attribute improves one dimension of your system at the cost of another.
These trade-offs aren’t flaws, they’re the price of optimization.
Good architecture means knowing which compromises you’re making and why.
Availability → More Uptime, Higher Cost
You trade simplicity and cost for resilience.
Redundant servers, health checks, and failover systems keep users online but increase your infrastructure and operational overhead.
Scalability → More Users, More Complexity
Scaling out spreads load across many instances, but it also multiplies moving parts.
Stateless services, partitions, and load balancers improve throughput, yet they complicate coordination and consistency.
Performance → Faster Responses, Less Flexibility
Optimizing for speed often means increased caching, using specialized data structures, or hard-coding hot paths.
That boosts throughput but makes change harder; you win speed, but you lose some adaptability.
Reliability → Predictable Behavior, Slower Iteration
Systems that favor reliability add validation, retries, and strict contracts.
That stability helps users and other teams trust your APIs, but it slows experimentation and iteration.
The more predictable the system, the less nimble it becomes.
Maintainability → Easier Change, Lower Raw Efficiency
Maintainable systems favor structure over speed.
Clear boundaries and abstractions make change safe and predictable, even as the codebase grows.
The trade-off is small runtime overhead and extra layers to manage; but you gain long-term stability and faster development over time.
Security → Stronger Defense, Tougher Experience
Encryption, access controls, and audits protect data but add friction for both users and engineers.
Secure systems require more setup, more approvals, and sometimes slower paths.
The trick is balancing safety with usability.
Usability → Simpler Experience, Hidden Complexity
A clean, intuitive interface usually means more complexity behind the scenes.
Systems that “just work” hide orchestration, error recovery, and state management from the user.
You shift complexity from users to developers; a good trade, but still a trade.
Portability → Broader Reach, Less Specialization
Designing for portability across clouds or platforms demands abstraction and lowest-common-denominator choices.
You gain flexibility in where you deploy, but lose access to platform-specific optimizations.
How to Prioritize Competing Attributes
You can’t design for every quality attribute.
Each one adds complexity, cost, or latency.
The key is deciding which qualities actually define success for your system, and which ones you can defer or trade off.
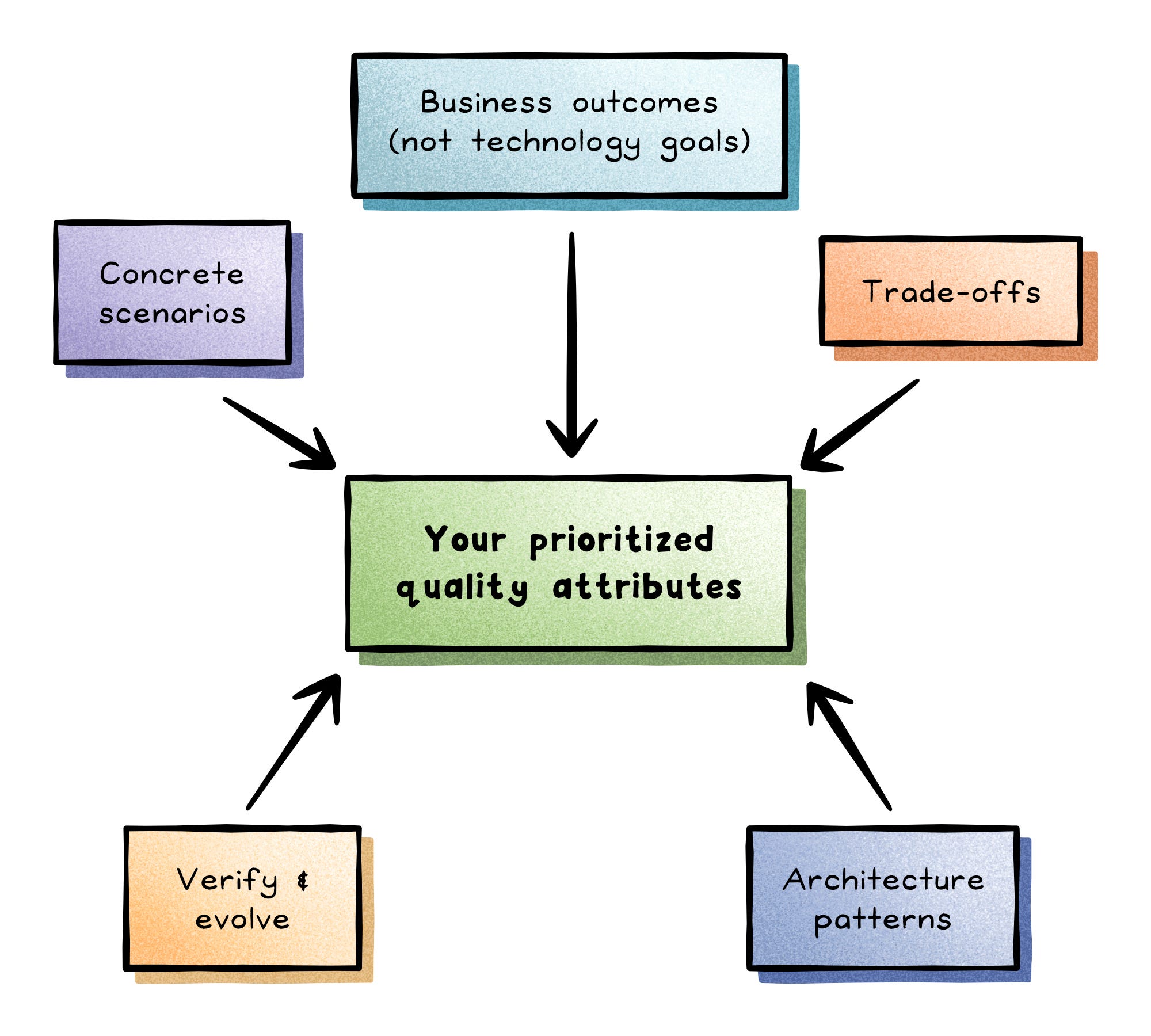
1. Start From Business Outcomes, Not Technology Goals
Every quality attribute serves a purpose beyond engineering elegance.
Availability matters when downtime costs revenue or trust.
Performance matters when user satisfaction or conversion depends on speed.
Maintainability matters when your system changes often and multiple teams contribute.
Security matters when you handle private or regulated data.
Tie each attribute to a business risk or metric; that’s how you avoid overengineering.
2. Translate Goals Into Concrete Scenarios
Vague targets like “highly available” or “scalable” don’t guide design decisions.
Instead, write attribute scenarios: specific what-if statements that describe stimulus, environment, and expected response.
For example: “If one region fails, 95% of requests should reroute within 30 seconds without data loss.”
This makes attributes measurable and testable, turning them into design constraints rather than aspirations.
3. Understand and Manage Trade-Offs
Attributes rarely align perfectly, optimizing one often weakens another:
Strong consistency vs latency → Replicas across regions slows down writes.
Availability vs cost → Redundancy increases uptime but increases costs.
Security vs usability → Stricter controls can add friction.
Explicitly decide which side matters more for your use case.
You can’t have “always up,” “always consistent,” and “always cheap” simultaneously.
4. Match Architecture Patterns to the Priorities
Different architectures emphasize different qualities:
Microservices → Scalability and deployability, but harder consistency and latency control.
Monoliths → Easier maintainability early on, but slower team velocity later.
Event-driven designs → Improve scalability and decoupling, but complicate observability.
Pick the structure that best aligns with your top attributes rather than what’s fashionable.
5. Verify and Evolve Continuously
Attributes drift as traffic, features, and teams grow.
What was “performant” last year may fail tomorrow.
Bake validation into your process:
Load tests → Check performance and scalability.
Chaos drills → Validate availability and fault tolerance.
Security audits → Confirm confidentiality and integrity.
UX testing → Validate usability and accessibility.
Measure, test, and recalibrate your attribute priorities often.
Quick Checklist
✓ Define success in user or business terms, not just uptime.
✓ Write measurable attribute scenarios.
✓ Make trade-offs explicit and documented.
✓ Align architecture choices with top priorities.
✓ Continuously validate and adjust as systems evolve.
Recap
Quality attributes are first-class requirements, not afterthoughts.
State them, prioritize them, and use design pillars to bring them to life with the right tactics.
Make trade-offs explicit, measure continuously, and evolve.
That’s how you ship software that stays fast, safe, and changeable long after launch.
👋 If you liked this post → Like + Restack + Share to help others learn system design.
Subscribe to get high-signal, visual, and simple-to-understand system design articles straight to your inbox:
Wow, I'm a huge fan of your blog posts.
The trade-off section is a must-read for anyone who's designing systems at work (or has an interview coming up!). Solid breakdown!