
LLMs: The Essential Guide
Most engineers only see the API layer. Here's what's happening underneath.


What Happens When 81% of Your Code Is AI-Generated?
Presented by Checkmarx
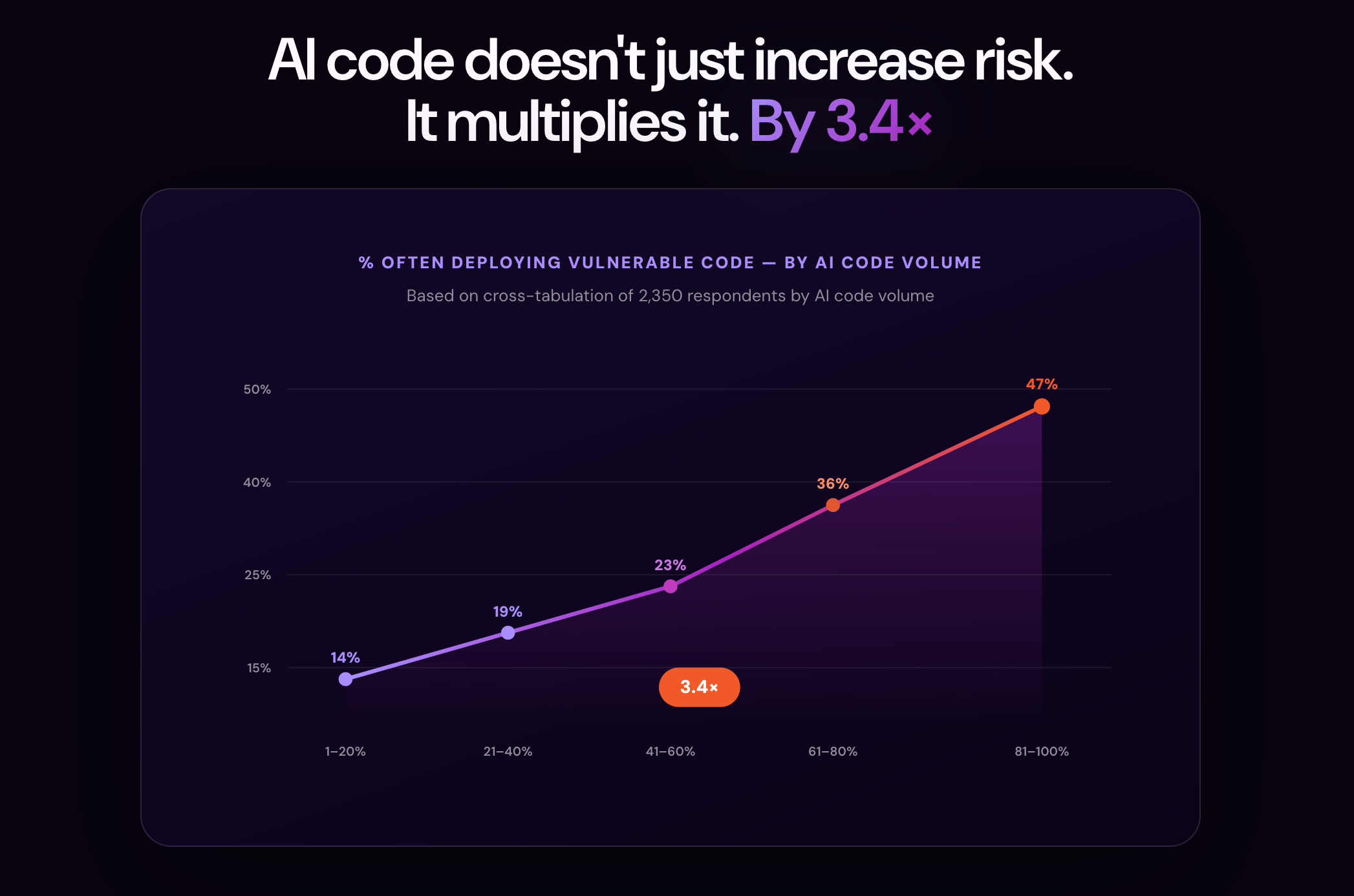
Organizations with more than 81% AI-generated code reported shipping vulnerable code 3.4x more often than organizations with low AI adoption. That’s just one of several findings from Checkmarx’s Future of Application Security in the Era of AI Report. See what the data reveals.
LLMs: The Essential Guide
LLMs are not just smarter search engines.
They are distributed systems built from many moving parts: the model itself, training pipelines, retrieval systems, inference infrastructure, safety layers, and the product experience around them.
Most engineers only see the API layer. That works fine until something goes wrong.
And when LLM systems fail, the failures are often hard to diagnose. Hallucinations, latency spikes, context loss, rising inference costs, inconsistent outputs; the problem is usually somewhere beneath the response itself.
Understanding how these systems work changes how you debug them, scale them, and design around their limitations. From tokenization and transformers to retrieval, fine-tuning, inference, and guardrails, every layer shapes the final answer you see on screen.
The four layers
An LLM system has four practical layers:
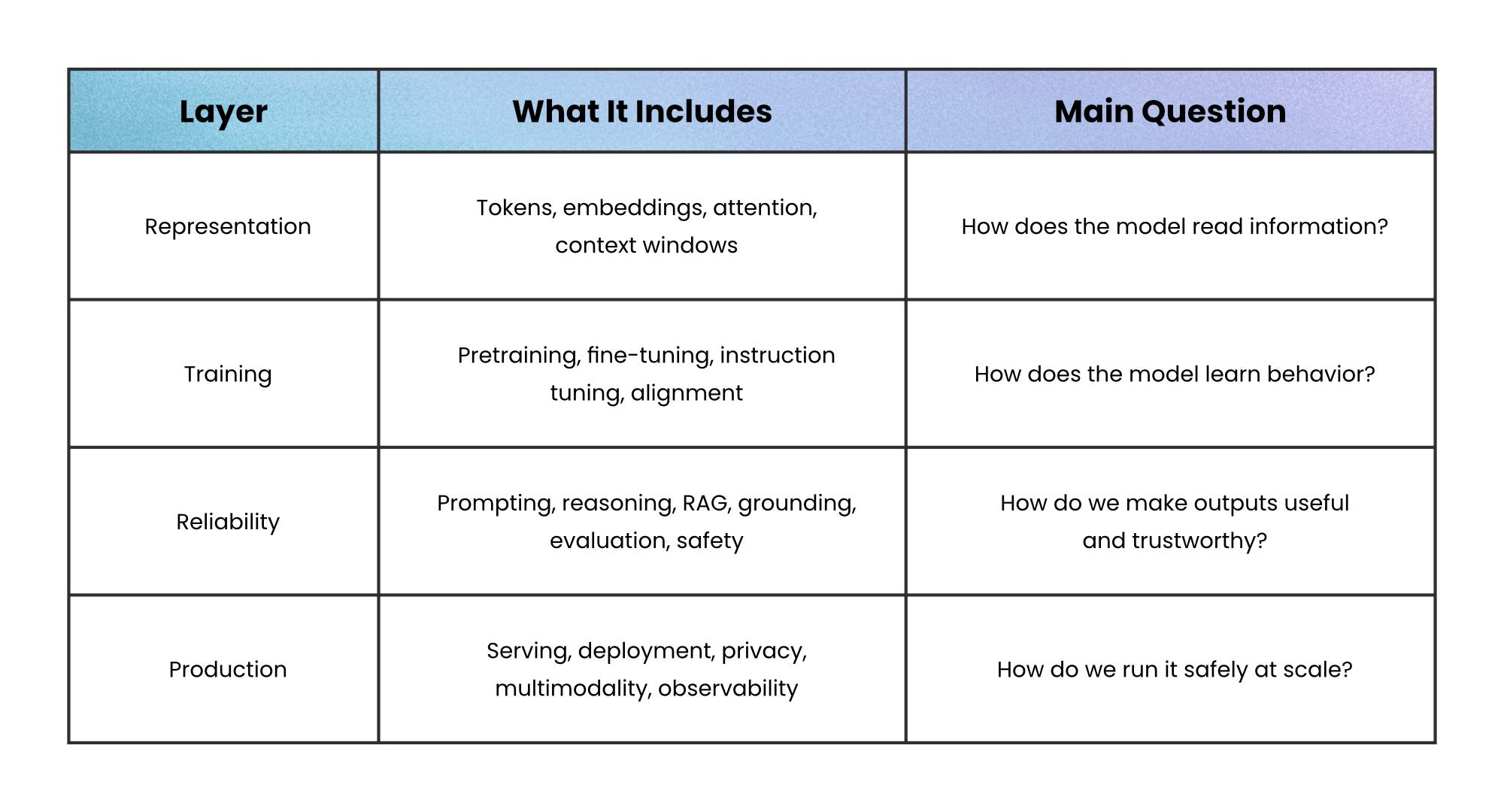
Most mistakes happen when teams blur these layers.
You do not fix missing company knowledge with a clever prompt. You do not fix hallucinations by blindly fine-tuning. You do not fix latency by only picking a “smarter” model. Each layer has its own job.
Transformers
Transformers are the neural network architecture behind modern LLMs.
Their core mechanism is attention: a way for tokens to look at other tokens in the sequence and decide what matters most.
Instead of reading text strictly one word at a time, Transformers build relationships across the entire context window. In a sentence like “The server crashed because it ran out of memory,” attention helps the model understand that “it” refers to the server.
Different Transformer architectures fit different jobs:
Encoder-only → Good for classification, embeddings, and semantic search.
Encoder-decoder → Good for transformations like translation and summarization.
Decoder-only → Good for chat, code generation, and next-token prediction.
Most modern chat models are decoder-only because they generate text one token at a time.
Tokenization
Tokenization is how text becomes something a model can process.
LLMs do not read raw text directly. They read tokens: small pieces of text created by a tokenizer. A single word may become multiple tokens, and symbols, code, or emojis can expand even further.
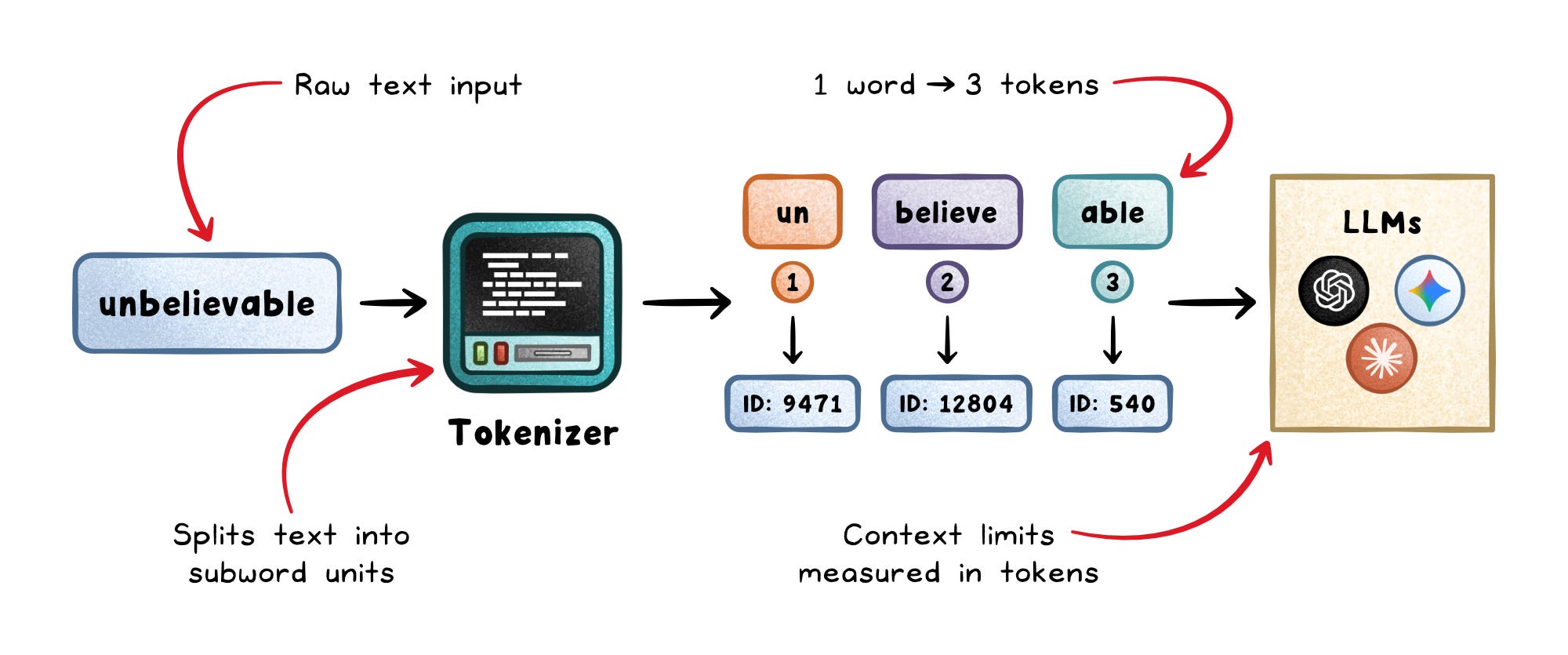
Tokens matter because they shape almost every system constraint:
Cost → Most providers bill by input and output tokens.
Context window → A model’s working memory is measured in tokens, not words.
Latency → More tokens usually mean more processing time.
Retrieval chunking → Documents must be split by token limits, not page count.
This becomes especially important with code, logs, multilingual text, and large prompts. Two inputs with the same word count can produce very different token counts.
Embeddings
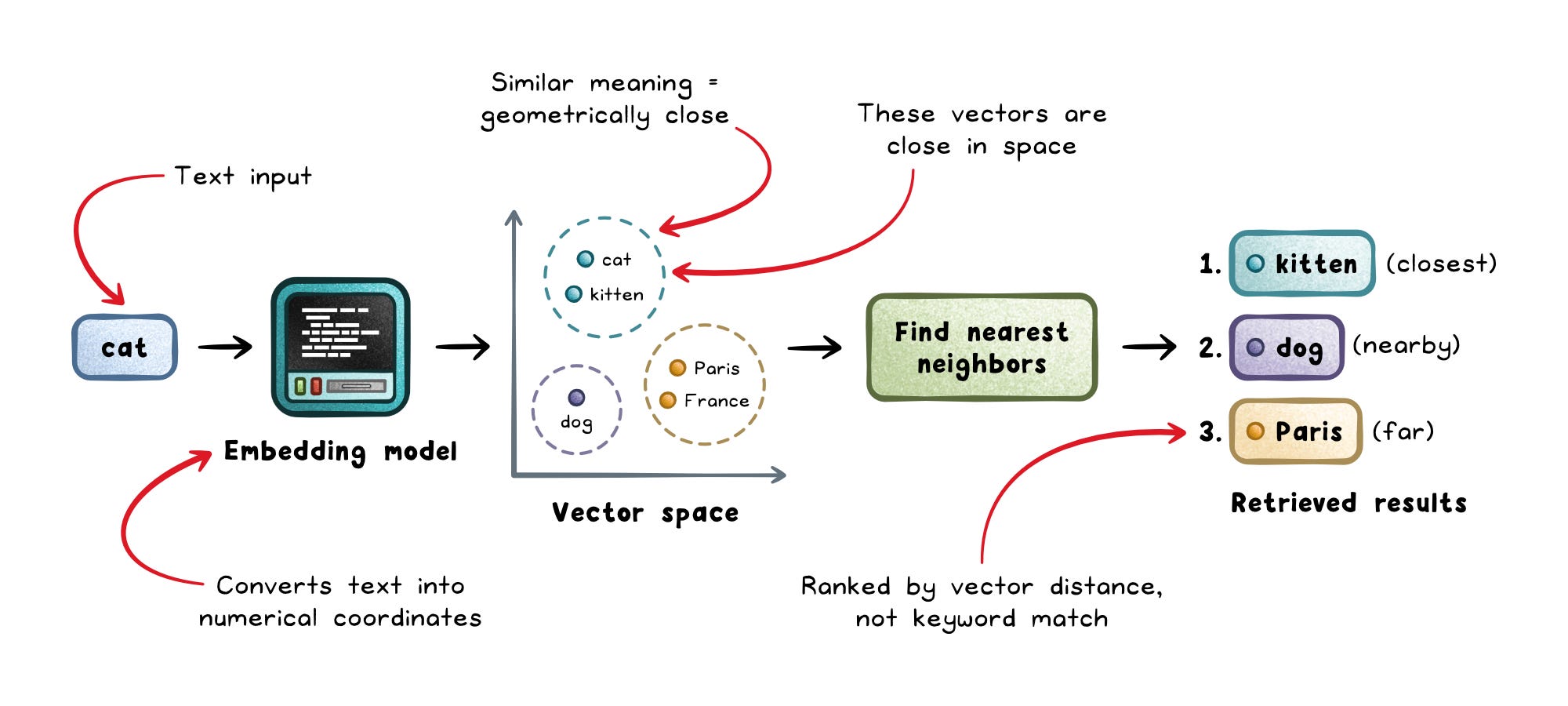
Embeddings turn text into vectors which are lists of numbers that represent meaning.
If two pieces of text mean similar things, their vectors should land close together. That makes embeddings the foundation of semantic search and retrieval systems.
A support platform might embed every help article. When a user asks, “Why was my payment declined?”, the system searches for nearby vectors and retrieves related articles about billing failures, fraud checks, or declined cards.
This is the backbone of retrieval-augmented generation (RAG), where external knowledge is fetched before the LLM generates a response.
There is no universally best embedding model. Different models optimize for different retrieval patterns. Some work better for semantic similarity, others for clustering or reranking. So the important part is testing them against your actual data and queries.
Attention, context windows, and long-context methods
Attention lets the model decide which earlier tokens matter most.
But attention becomes expensive as inputs grow because tokens may need to compare against many other tokens. That is one reason long-context systems are difficult to scale efficiently.
A context window is the amount of text a model can consider in one request. Larger windows help with long documents, codebases, and multi-step workflows, but more context is not always better.
A giant prompt full of loosely related information can behave like a desk buried under papers. The answer may exist somewhere in the pile, but finding the right signal becomes harder as the noise grows.
Good long-context systems usually follow a few principles:
Keep instructions clear → Signal matters more than volume.
Retrieve only relevant information → Smaller context is often more effective.
Summarize stale state → Compaction keeps the prompt focused.
Long context works best when many related facts are needed at the same time. Otherwise, retrieval is usually faster and cheaper.
Scaling laws
Scaling laws describe how model performance changes as parameters, data, and compute increase.
A common misconception is that bigger models automatically create better systems. Size helps, but only when the model is trained with enough high-quality data and served efficiently. A poorly trained large model can still underperform a smaller, better-balanced one.
Model selection is not a popularity contest. You need to balance several tradeoffs:
Quality → Does it solve the actual task well?
Latency → Can it respond fast enough for users?
Cost → Does unit economics make sense?
Reliability → Does it behave predictably under edge cases?
Grounding → Does it use the right source material correctly?
The best model is usually not the largest one. It is the one that delivers enough quality at the right cost, latency, and risk level.
Pretraining, fine-tuning, and instruction tuning
LLMs are trained in stages, with each stage solving a different problem.
Pretraining → The model learns general language patterns and broad knowledge from massive datasets.
Fine-tuning → The pretrained model is adapted for a narrower domain, behavior, or task.
Instruction tuning → The model learns how to follow prompts and respond in a more conversational, task-oriented way.
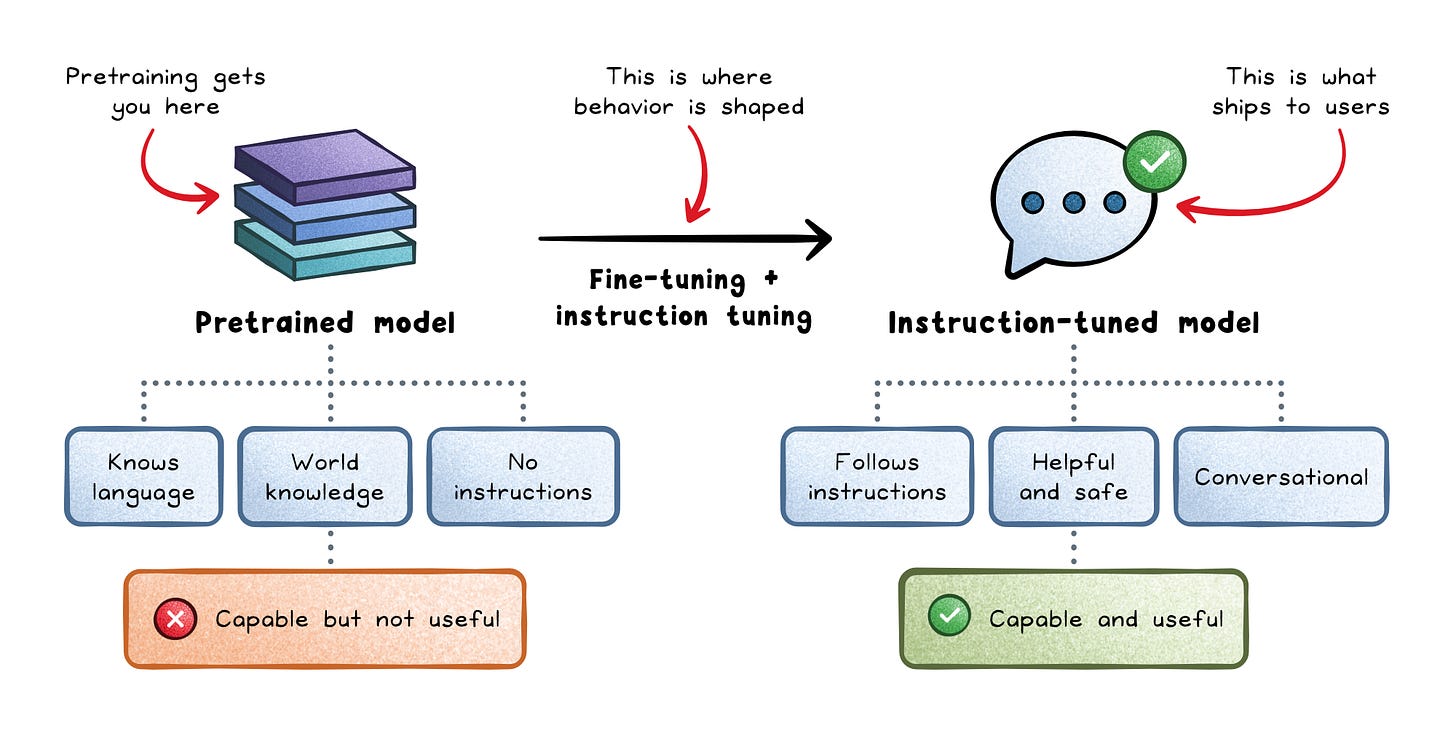
A common mistake is treating fine-tuning as the solution for everything.
Fine-tuning works best for stable behavior, like tone, formatting, or repeated workflows. A customer support assistant, for example, may need consistent escalation rules and response style.
But fast-changing information usually does not belong in the model weights. Product pricing, internal docs, or policy updates are usually better handled through retrieval systems like RAG.
In practice, fine-tuning shapes behavior. Retrieval supplies fresh knowledge.
Alignment
Alignment is the process of shaping model behavior toward goals like helpfulness, safety, and policy compliance.
The three main approaches are:
RLHF (Reinforcement Learning from Human Feedback) → Human reviewers rank model outputs, and the model learns to prefer responses people rate more highly.
DPO (Direct Preference Optimisation) → A simpler approach that learns directly from preference comparisons without a full reinforcement learning loop.
Constitutional AI → The model critiques and revises its own responses using a defined set of rules or principles.
Alignment is a balancing act, not a safety switch.
A model can become more helpful while also becoming more willing to follow harmful instructions. It can become safer while also refusing harmless requests too often. A polished response can still contain incorrect information.
That is why alignment alone is not enough. Reliable LLM systems still need retrieval, permissions, evaluation, and monitoring around the model itself.
Prompt engineering
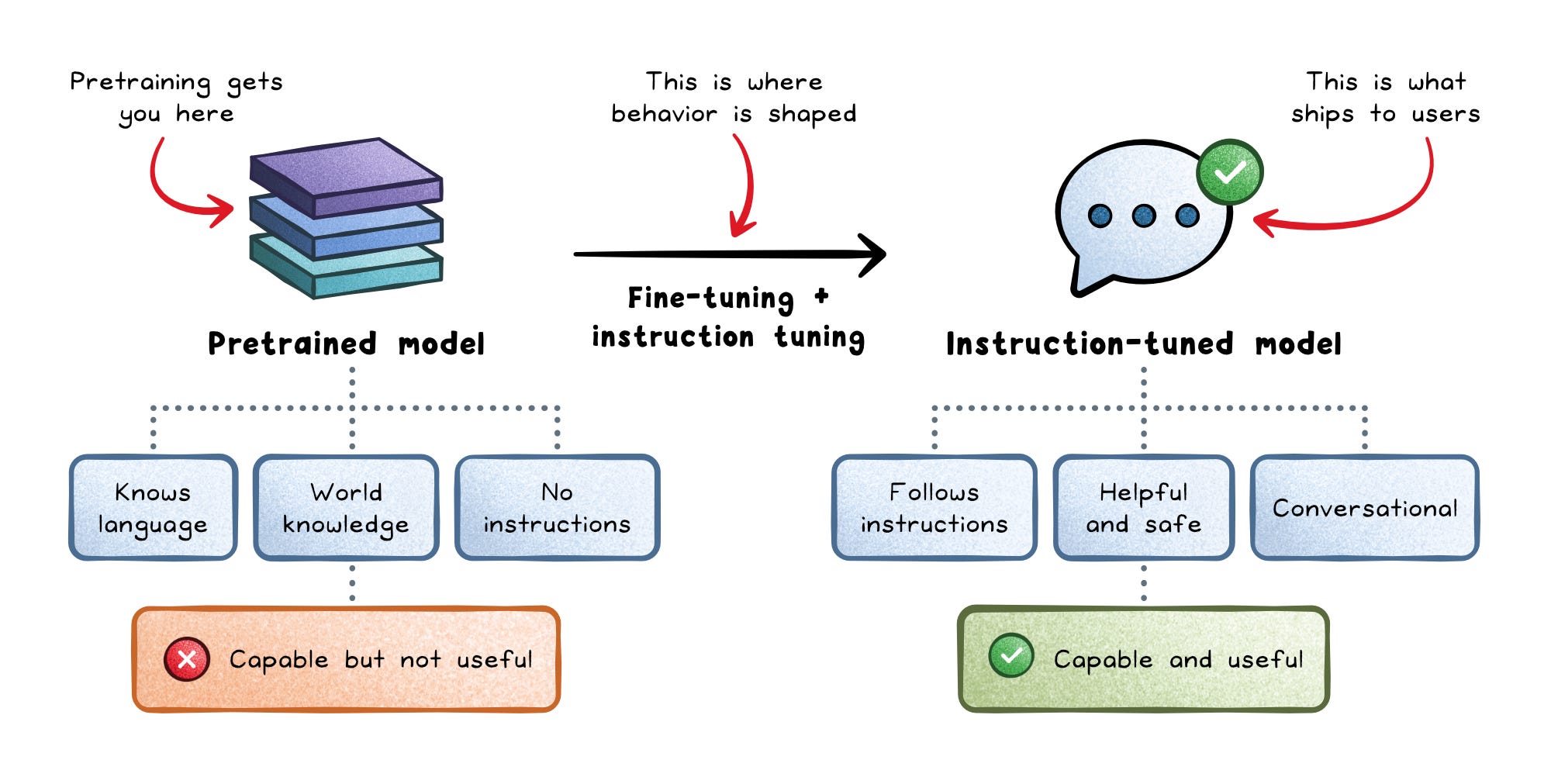
Prompt engineering is the design of instructions, examples, and context given to the model.
It is often the fastest way to improve an LLM system because changing a prompt is far cheaper than retraining a model. A good prompt can define the model’s role, constrain the output format, provide examples, and tell the model how to use retrieved information.
But prompts become fragile when they grow without structure.
Model updates can change behavior → A prompt that works today may drift tomorrow.
Examples can overfit → The model may mimic patterns instead of understanding intent.
Complexity accumulates → Large prompts can turn into brittle mini-applications.
Treat prompts like production code. Version them, test them, and monitor them because prompt behavior directly affects system behavior.
Reasoning patterns
Reasoning techniques help LLMs handle tasks with multiple steps, dependencies, or external information needs.
Chain-of-thought prompting → Encourages the model to reason step by step.
Self-consistency → Samples multiple reasoning paths and selects the most consistent answer.
ReAct → Combines reasoning with tool use, letting the model think, act, observe results, and continue.
These approaches work especially well for math, coding, research, and agent workflows where planning and evidence gathering matter more than fast responses.
But reasoning comes with tradeoffs.
Extra reasoning uses more tokens. Tool calls add latency. Multiple reasoning attempts increase cost even further.
Use reasoning patterns when correctness matters more than speed. For simpler tasks like classification, routing, or formatting, they usually add overhead without much benefit.
Retrieval-augmented generation (RAG)
Retrieval-augmented generation (RAG) connects an LLM to external knowledge sources.
The flow is simple: a user asks a question, the system retrieves relevant documents, and the model generates an answer using that retrieved context.
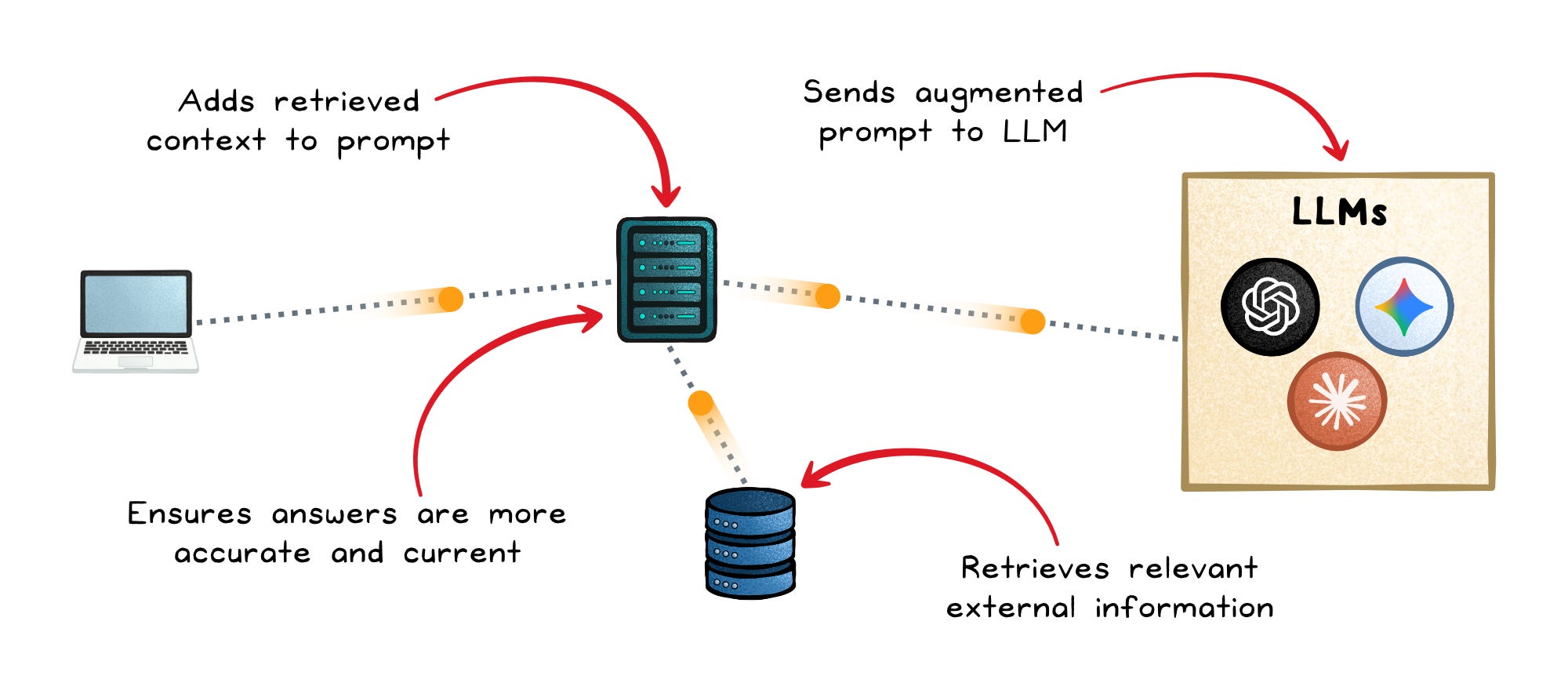
RAG matters because business knowledge changes far faster than model training. Instead of retraining the model every time information changes, you update the data source.
RAG works especially well when:
Facts change frequently → Policies, pricing, tickets, and docs evolve constantly.
Provenance matters → Users need to know where answers came from.
Knowledge is private → Internal documents should not require retraining a foundation model.
Updates must stay cheap → Reindexing documents is far easier than retraining models.
But RAG introduces its own failure modes.
The retriever may miss the right document. Chunking may separate information from its context. Ranking may surface misleading evidence. The model may even ignore the retrieved material entirely.
That is why grounding matters. Grounding means tying responses to verified source material instead of letting the model freely improvise.
Hallucination, evaluation, and safety
A hallucination is an unsupported or misleading output generated by the model.
But hallucinations are not caused by one single problem. The model may lack knowledge, retrieval may fail, the prompt may be unclear, the source material may be wrong, or a tool may return stale data.
That is why hallucinations cannot be solved with one technique. Reliable systems reduce them through layers of validation:
Retrieval evaluation → Did the system fetch the right evidence?
Grounding checks → Is the answer actually supported by the source material?
Safety testing → Does the system resist harmful or manipulative inputs?
Monitoring → Do real users expose failures missed during testing?
Benchmarks help, but they are only proxies. A model can perform well offline and still fail in production.
The real test is whether the system answers your users correctly, safely, and consistently under real-world conditions.
Compression and optimization
Efficiency is what turns an impressive model into something financially and operationally viable.
LLM inference is expensive because every generated token depends on the one before it. As outputs grow, latency and compute costs grow with them.
That is why production systems rely on techniques that reduce memory use and improve serving efficiency:
Quantization → Uses lower-precision weights to reduce memory and compute costs.
Pruning → Remove less useful parts of the model or computation.
Distillation → Trains a smaller model to mimic a larger one.
FlashAttention → Makes attention faster and more memory-efficient.
Speculative decoding → Uses a smaller model to draft tokens before a larger model verifies them.
PagedAttention → Improves memory management during inference serving.
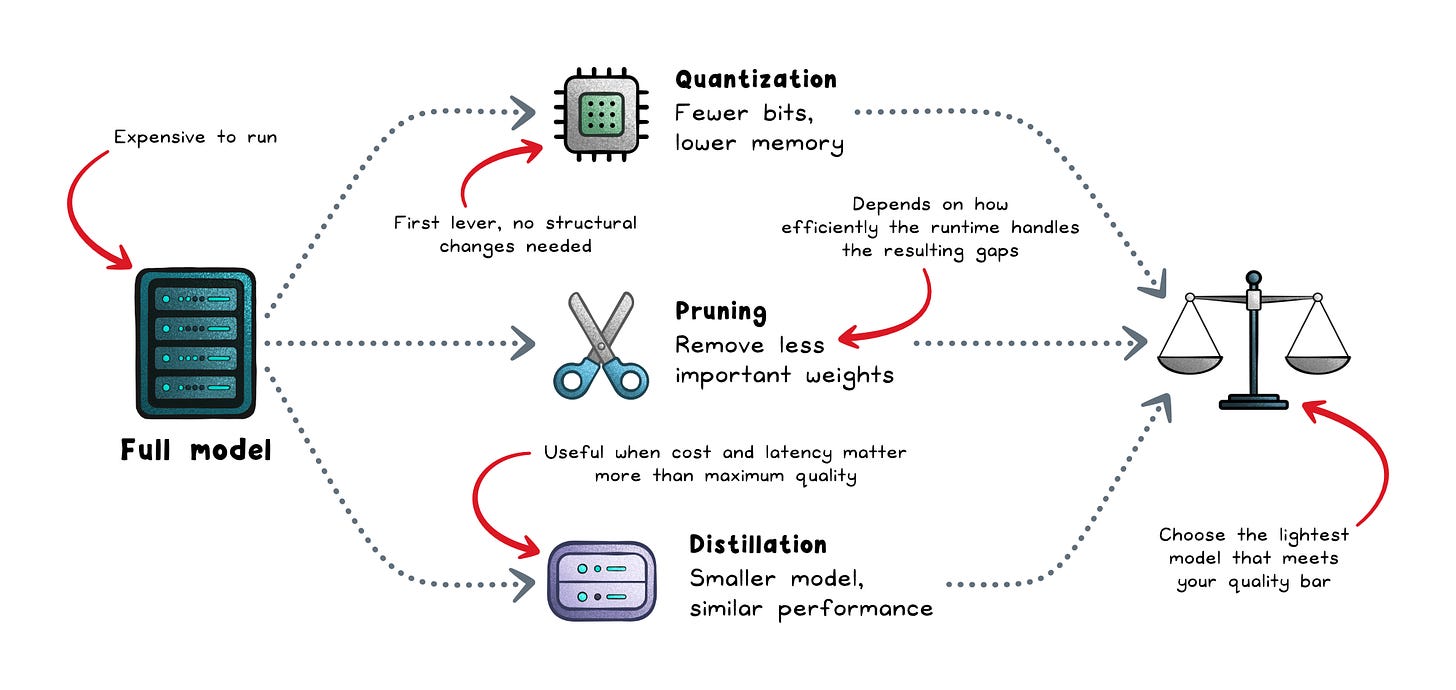
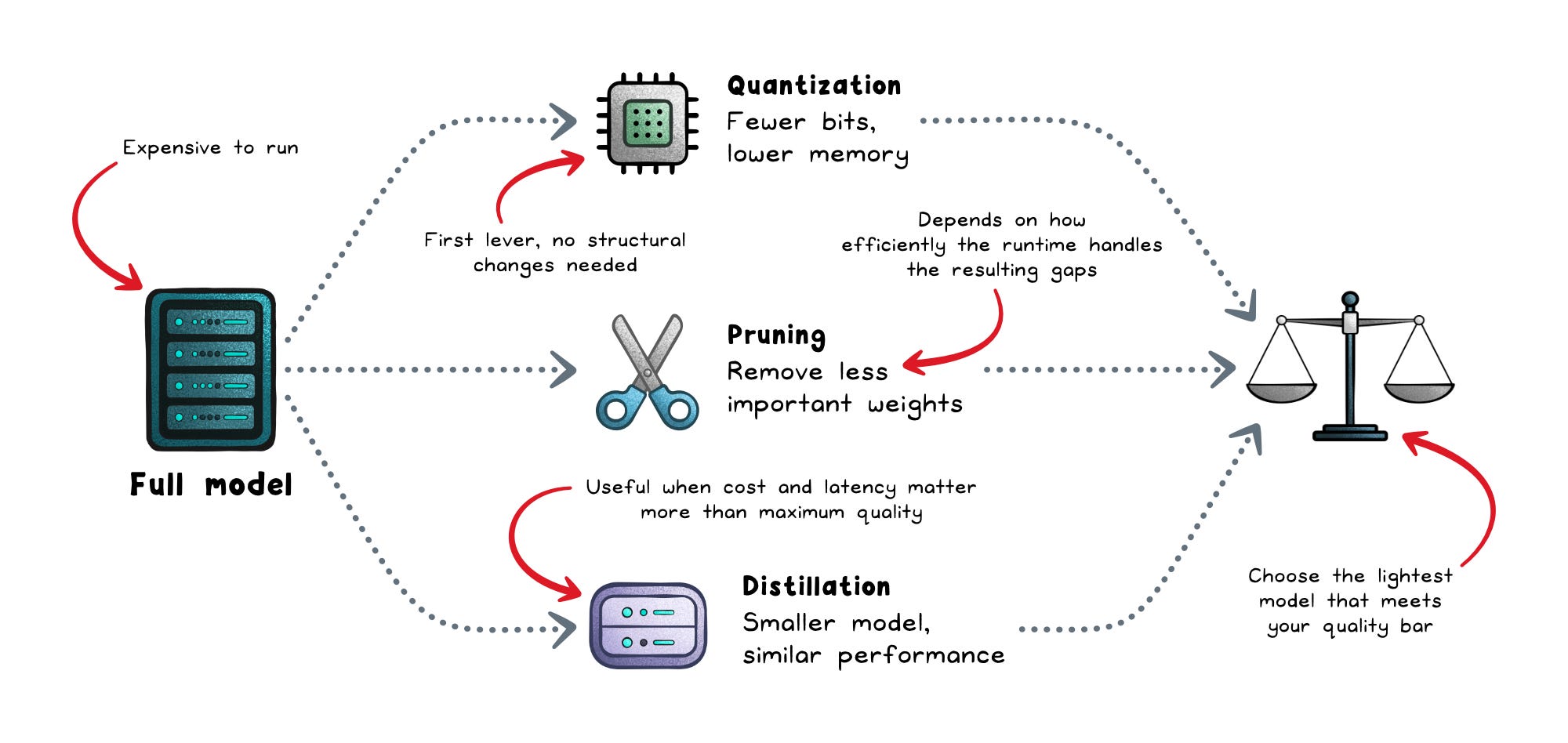
In practice, the biggest gains often come from simpler optimizations first: shorter prompts, capped outputs, cached context, batching, and smaller fallback models. You usually do not need a larger GPU cluster as the first solution.
Deployment patterns
Deployment determines where model inference happens, and that decision affects latency, privacy, reliability, and cost.
There are three common deployment patterns:

Edge deployment runs the model on-device or close to the user. Cloud deployment sends requests to centralized model infrastructure. Hybrid systems split workloads between both.
Choose edge when responsiveness and data locality matter most. Choose cloud when model capability and tooling matter more. Choose hybrid when you need both and can cleanly separate the workflow.
Privacy and data governance
Privacy and governance shape how data enters, moves through, and leaves an LLM system.
This is not just a compliance problem. It directly affects architecture.
A privacy-sensitive system may require local processing, encrypted logs, restricted tool access, and short retention windows. Regulated workflows may need human approval before the model can send messages, update records, or trigger actions.
Good governance usually comes down to a few core controls:
Classify inputs → Know which data is sensitive or regulated.
Separate instructions from retrieved data → External content should not override system rules.
Limit tool permissions → Give the model only the access it actually needs.
Control retention → Store logs only as long as necessary.
Review vendor policies → Understand how providers handle training and data storage.
The more autonomy a model has, the more important the guardrails become.
Multimodality
Multimodal models work with more than just text. They can process images, audio, video, documents, and combinations of different inputs together.
That expands what LLM systems can do: document analysis, visual search, voice assistants, meeting summaries, accessibility tools, and more natural interfaces.
But multimodality also increases the failure surface.
A model may misread an image, miss small text in a screenshot, mistranscribe audio, or incorrectly connect information across formats. A system that performs well in text may still struggle with visual grounding or audio accuracy.
That is why each modality needs separate evaluation:
Text → Does the model reason correctly?
Images → Does it identify visual details reliably?
Audio → Does transcription preserve meaning?
Combined inputs → Does it connect the right information across formats?
Evaluate each modality separately then evaluate the combined system, and keep modality-specific fallbacks where accuracy matters.
Observability and monitoring
Traditional monitoring tells you whether a request succeeded. LLM observability needs much deeper visibility.
You need visibility into the entire execution path: which prompt was used, what documents were retrieved, how many tokens were consumed, which tools were called, what safety checks fired, and whether the answer actually helped the user.
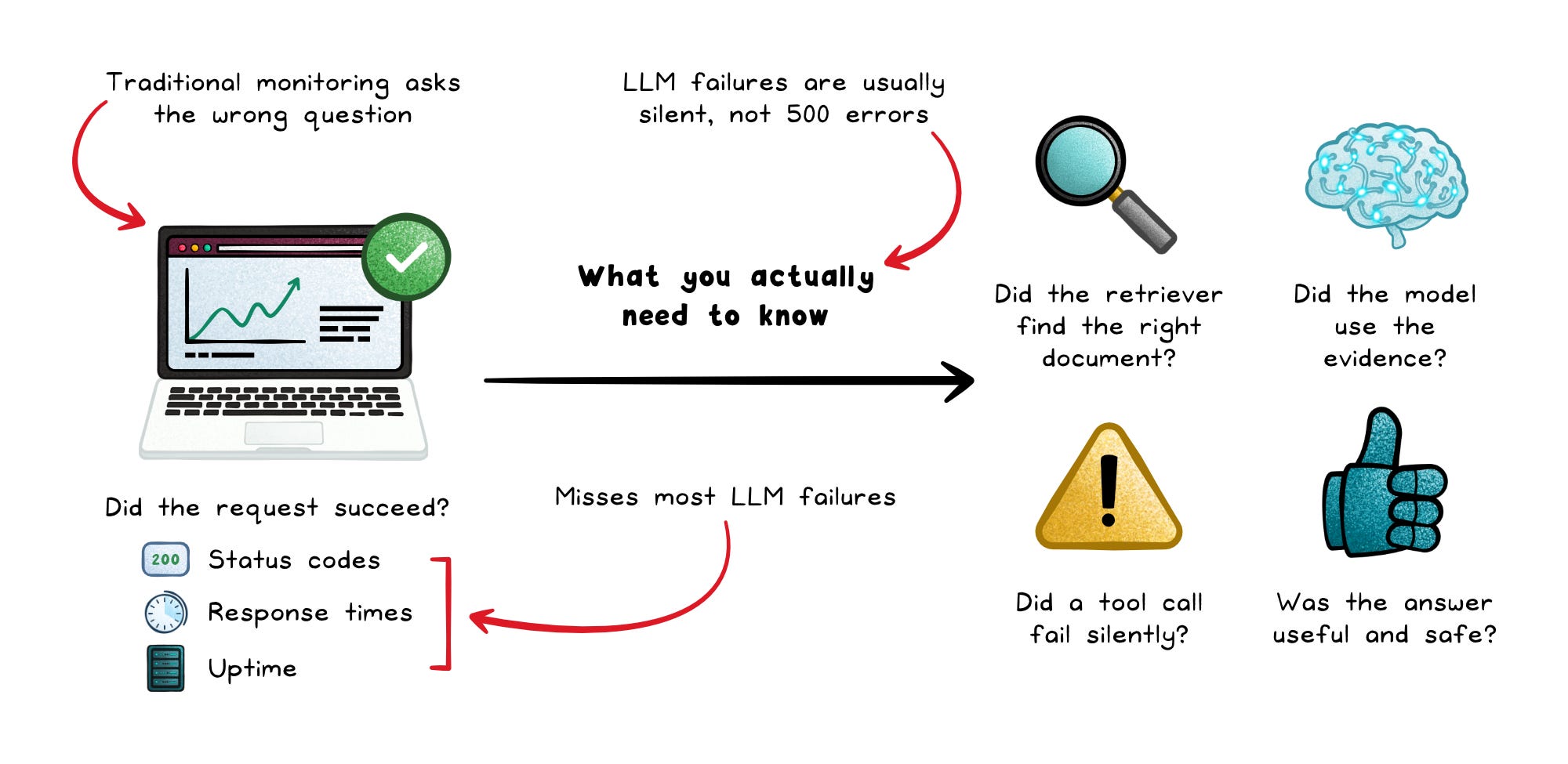
That usually means tracing several layers at once:
Prompt version → Which instructions generated the output?
Token usage → Did costs spike because prompts or outputs grew?
Retrieval results → Was the right evidence returned?
Tool calls → Did the model use the correct tools safely?
Latency → Was time spent in retrieval, generation, or external tools?
Safety events → Did the system detect prompt injection or sensitive data risks?
User outcomes → Did the response actually solve the problem?
Without observability, debugging LLM systems becomes guesswork. With it, failures become traceable.
Wrapping up
LLMs make more sense when you treat them as systems, not just models.
The difficult part is not generating text. It is making the entire system reliable, grounded, observable, fast, and safe under real-world conditions.
That is why successful LLM products are not built from prompts alone. They come from layers working together: retrieval, evaluation, guardrails, serving infrastructure, observability, governance, and careful system design.
The model produces the response.
The system around it determines whether that response can be trusted.
Related LUC reading
👋 If you found this useful → Like + Restack to help others learn system design.